![Positron's $230M Series B: The AI Chip Challenger Nvidia Should Fear [2025]](https://tryrunable.com/blog/positron-s-230m-series-b-the-ai-chip-challenger-nvidia-shoul/image-1-1770194433248.jpg)
The Chip Market's David vs. Goliath Moment Is Here
For years, Nvidia has owned the AI chip market like no company should ever own anything. They set the prices. They controlled supply. They basically wrote the rules. But something's shifting right now in 2025, and it's happening faster than anyone expected.
Positron just raised $230 million in Series B funding. That's not "interesting startup news" territory anymore. That's "the competitive landscape is fundamentally changing" territory.
Here's what makes this moment different: The capital is coming from serious players. Qatar Investment Authority isn't throwing money at a risky bet. They're making a calculated strategic move to build sovereign AI infrastructure. When a sovereign wealth fund bets $230 million on a chip startup specifically to reduce dependence on Nvidia, you're not looking at fringe competition. You're looking at the beginning of a market realignment.
And it's not just Qatar's money driving this. Positron has already raised over $300 million total. Previous backers include Valor Equity Partners, Atreides Management, DFJ Growth, Flume Ventures, and Resilience Reserve. These aren't casual investors. They're the people who fund moonshot companies that actually land on the moon.
But here's the real story that matters: Positron isn't trying to beat Nvidia at Nvidia's game. They're playing a completely different game. While Nvidia dominates training chips, Positron is focused on inference. That distinction matters more than you might think, and it's the reason why this $230 million round could reshape how AI infrastructure gets built worldwide.
This isn't hyperbole. Let me show you why.
Understanding the Inference Revolution Happening Right Now
Most people outside the industry hear "AI chips" and think all AI work is the same. It's not. Not even close.
Training is expensive, complex, and concentrated. A handful of companies spend billions training massive models. OpenAI trains GPT models. Anthropic trains Claude. Google trains Gemini. That's where the flashy, high-profile work happens. Nvidia dominates this space completely.
But inference is different. Inference is what happens when you actually use the model. You type a prompt into Chat GPT. That's inference. A business uses Claude to summarize customer feedback. That's inference. A recommendation engine suggests videos on YouTube. That's inference. Inference is happening trillions of times per day across thousands of companies worldwide.
Here's the key insight that most analysis misses: Inference workloads have completely different requirements than training workloads.
Training is about raw throughput. You're moving massive amounts of data through neural networks, running complex mathematical operations millions of times. You need GPU memory, bandwidth, and raw compute power. Nvidia's H100 and H200 chips are engineered specifically for this.
Inference, on the other hand, is about speed and efficiency. You're taking a model that's already trained and running it on new inputs. You need fast response times, low latency, and energy efficiency. You don't need the same levels of memory bandwidth that training requires. In fact, having excess bandwidth designed for training actually wastes power and money when you're running inference.
Positron understood this distinction years ago. While everyone else was focused on building Nvidia's successor for training workloads, Positron was asking: what if we optimized specifically for what inference actually needs?
Their first-generation chip, Atlas, is manufactured in Arizona. According to the company, Atlas can match the performance of Nvidia's H100 GPU for less than a third of the power consumption. Let that sink in. Same performance. One-third the power. That's not a marginal improvement. That's a fundamental difference in how the chip is designed.
Think about the business impact: If you're a hyperscaler running millions of inference requests per day, cutting power consumption by two-thirds changes your economics entirely. Your data center cooling costs drop. Your electricity bill gets smaller. Your carbon footprint shrinks. You can deploy more models on the same infrastructure.
That's why demand for inference-focused chips is surging right now. And that's why Positron's $230 million round matters.
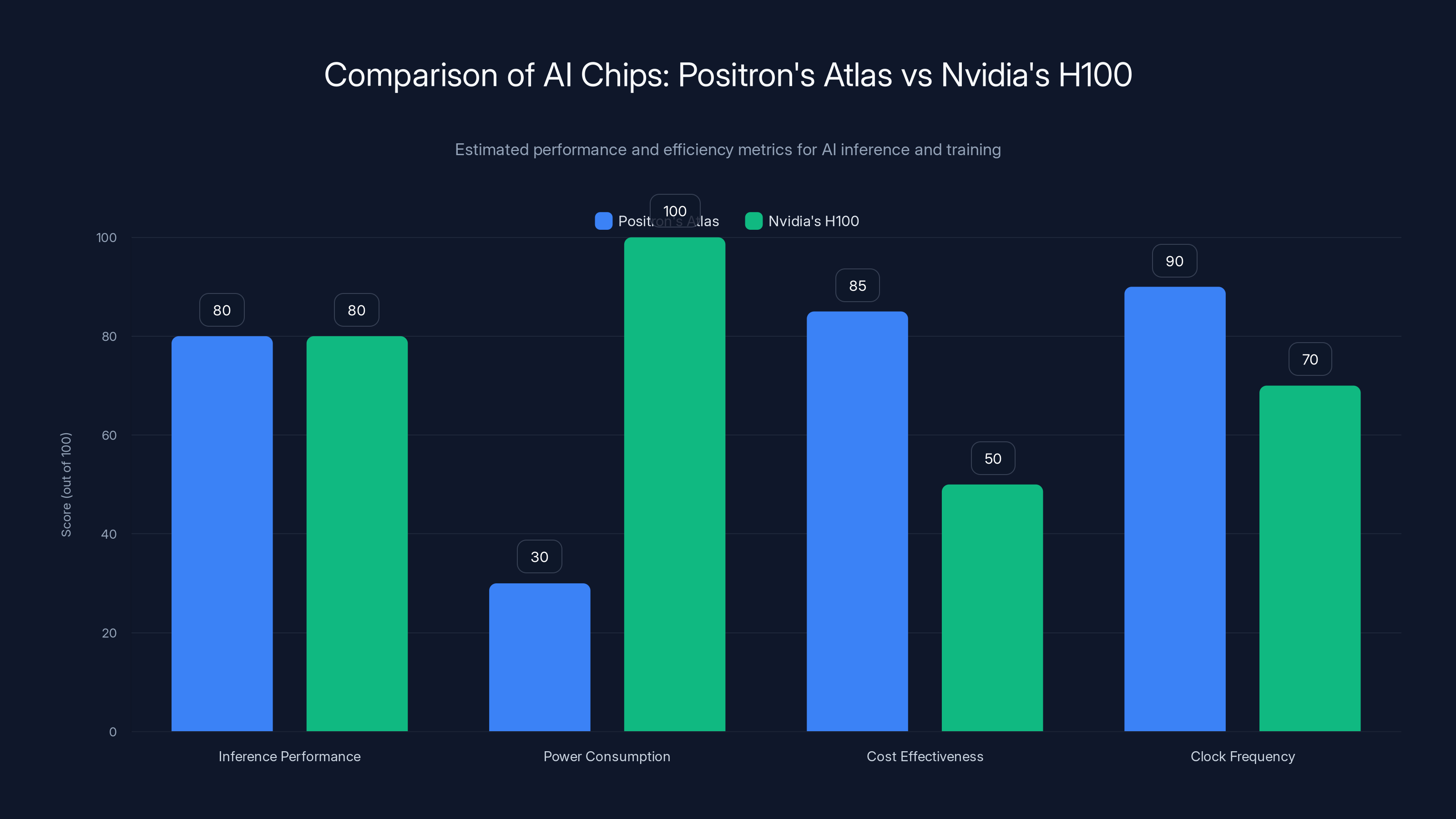
Positron's Atlas chip matches Nvidia's H100 in inference performance while being more power-efficient and cost-effective. Estimated data.
The Nvidia Vulnerability That Everyone's Noticing
Nvidia's problem is that they've been optimizing for yesterday's AI workload.
Two years ago, everyone was focused on training bigger models. Scale was the metric. The company with the biggest model would win. That created a clear incentive: build the best training hardware possible. Nvidia built the H100. Companies bought thousands of them. Nvidia made obscene amounts of money.
But the AI industry moved faster than Nvidia expected. Training is expensive, so companies stopped trying to build bigger models. Instead, they focused on making existing models better. Fine-tuning. Retrieval-augmented generation. Mixture of experts. All of these techniques shift the workload from training to inference.
The demand curve inverted. Suddenly, inference became the constraint, not training. Companies could run inference on Nvidia's hardware, but they were paying training-level prices for inference-level efficiency. That's a mismatch.
OpenAI is the most public example. They're one of Nvidia's largest customers. They've spent billions on Nvidia hardware. But according to reports, they're reportedly unsatisfied with some of Nvidia's latest AI chips and have been actively exploring alternatives since last year.
Think about what that means. Nvidia's biggest, most important customer is unhappy enough to shop around. That doesn't happen by accident. It happens when the product isn't meeting the actual needs.
And OpenAI isn't alone. Meta is building custom AI chips. Microsoft is building custom AI chips. Amazon is building custom AI chips. Intel is pushing Arc Alchemist and Gaudi chips. AMD is iterating on MI chips. The pattern is clear: massive companies are saying "Nvidia's solution is fine, but we can do better for our specific workload." When companies of that scale make that decision, it creates an opening for alternatives.
Positron is positioned to fill that opening, specifically for inference workloads. That's strategic.
Qatar's AI Infrastructure Strategy: A Sovereign Wealth Play
Qatar's investment in Positron isn't random. It's part of a larger strategy that reveals where the global AI economy is heading.
Qatar Investment Authority has been making aggressive moves into AI infrastructure. They're not trying to become a chip maker themselves. Instead, they're making strategic bets on companies that will become essential infrastructure in the global AI ecosystem.
The timing is significant. Governments and sovereign wealth funds around the world are waking up to a realization: AI compute is becoming as strategically important as energy, defense, or financial systems. If you don't have indigenous AI infrastructure, you're dependent on foreign suppliers for a capability that will define economic competitiveness for decades.
Qatar's approaching this systematically. In September 2024, Qatar announced a $20 billion joint venture with Brookfield Asset Management specifically to build AI infrastructure. That's not venture investment in startups. That's building actual data center capacity and supporting the supply chain that makes those data centers possible.
Positron's $230 million Series B is part of that ecosystem strategy. If Positron's chips become the standard for inference workloads globally, then Qatar secured a piece of that value chain early. It's a smart play for a country trying to position itself as a leading AI hub in the Middle East.
This matters because it shows how the AI infrastructure market is evolving. We're not just seeing competition between companies anymore. We're seeing competition between countries and sovereign wealth funds to control strategic pieces of the AI supply chain. Positron is valuable precisely because they're building something that multiple countries and companies need.
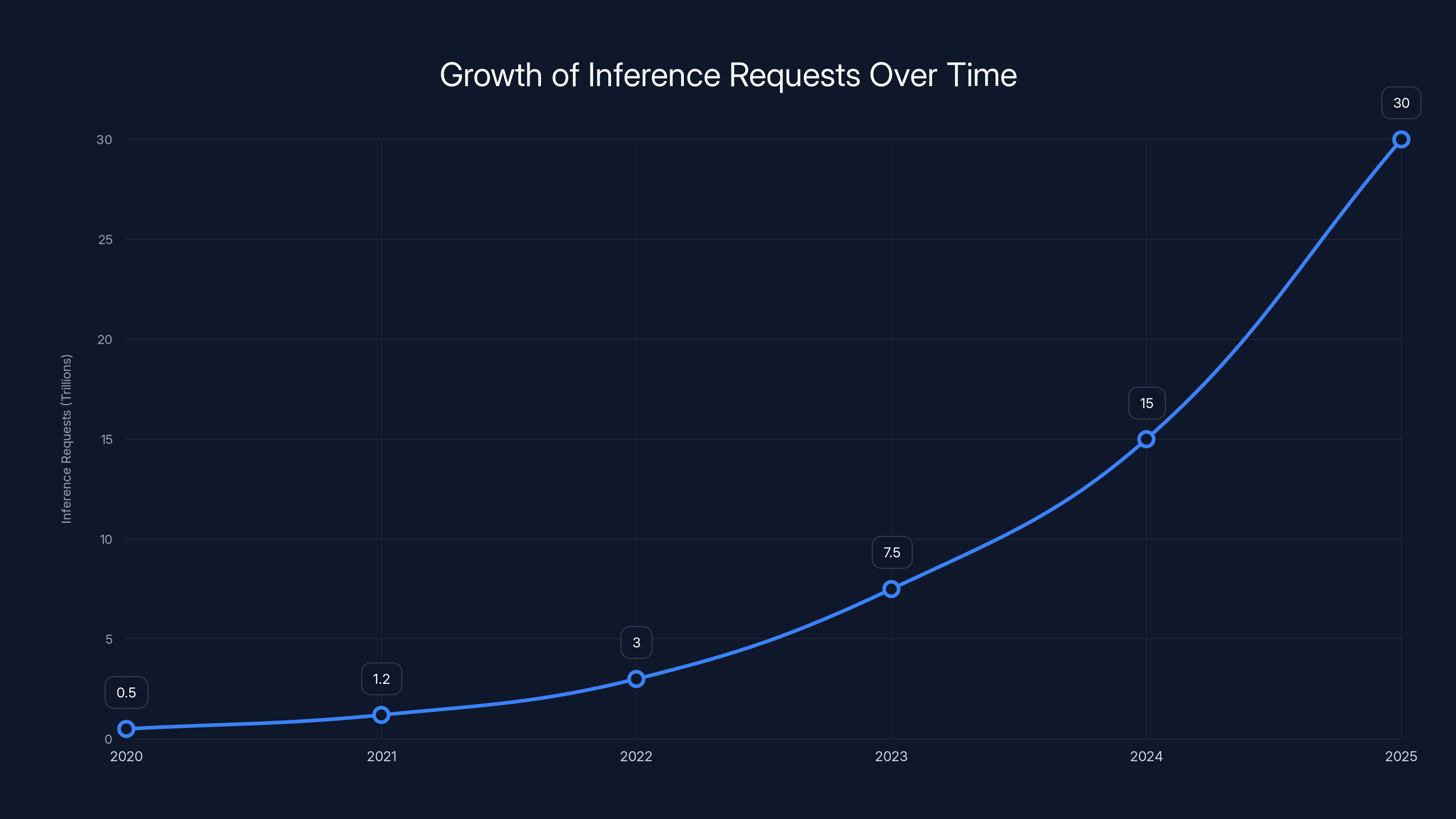
The number of global inference requests is projected to grow exponentially, reaching 30 trillion by 2025. Estimated data highlights the rapid expansion of AI model deployment.
Atlas Chip: What Makes It Different From Everything Else
Positron's Atlas chip is a good example of how rethinking the design problem from first principles can create something genuinely novel.
Most modern AI chips are evolution, not revolution. AMD's MI chips evolved from their gaming GPU architecture. Intel's Gaudi chips evolved from their data center processor architecture. There's logic to this approach because it leverages existing manufacturing relationships, software ecosystems, and architectural knowledge.
Positron took a different approach. They asked: if we're optimizing for inference specifically, what would the ideal architecture look like? Not what's the best way to modify an existing architecture, but what does an inference-optimized chip actually need?
The answer led to several design choices that are different from what Nvidia prioritizes:
High-frequency operation: Atlas runs at higher clock speeds than many competing chips. This helps with latency, not throughput. When you care about how fast a single request gets answered, high frequency matters more than memory bandwidth.
Optimized memory hierarchy: Atlas has a different memory subsystem than training-optimized chips. The team focused on the specific memory access patterns that inference workloads create, rather than the patterns that training creates. Small difference in description. Big difference in actual performance.
Video processing efficiency: Sources indicate that Atlas performs strongly in video processing workloads. This is interesting because video is becoming increasingly important for AI applications. Video generation, video understanding, video analytics. All of these require different processing patterns than text-based language models. Building that in from the ground up rather than bolting it on later is a smarter design approach.
Power envelope optimization: The goal of less than one-third the power consumption of an H100 isn't accidental. The entire chip was designed around that constraint. Different cooling solutions, different voltage domains, different power management. These design choices accumulate to hit that power target.
The manufacturing location matters too. Atlas is manufactured in Arizona. That's not casual. Manufacturing in the U.S. creates supply chain advantages (shorter lead times, more reliable partners, regulatory clarity) and positions Positron for government contracts. The U.S. government has been increasingly focused on domestic chip manufacturing capacity for both economic and national security reasons. Manufacturing domestically is an advantage.
Why This Funding Round Signals A Fundamental Market Shift
Let's be clear about what $230 million means in the context of chip development.
It's not "we're going to change the world" money. It's "we're going to manufacture, scale, and support real products" money.
Positron's total funding is now over $300 million. That's enough to:
- Build manufacturing relationships with foundries and maintain volume orders
- Hire top engineering talent from Nvidia, AMD, Intel, and the rest of the industry
- Fund R&D for second and third-generation chips
- Build sales and customer success teams
- Develop software stacks and driver support
- Handle any chip design iterations or fixes
- Stay operational for years even if revenue takes longer than expected
This is serious money for a startup. But it's not exceptional for a chip company. What's exceptional is the quality and focus of the backers.
Qatar Investment Authority is a $450+ billion fund. They don't write checks for speculative bets. They write checks for companies that solve real problems that customers will pay for.
Previous investors include Valor Equity Partners (which has backed companies like Core Weave and other AI infrastructure plays), Atreides Management (famous for patient capital in hard tech), and others. This is the investor cohort that understands chip development takes time and has the capital to wait.
The fact that these investors came back for the Series B, and that new major institutional money (Qatar) joined, signals confidence that Positron has proven something concrete. They haven't just shown a promising design. They've shown manufacturing capability, customer traction, or both.
The Inference Boom: Market Context For Why This Matters
Positron's timing is nearly perfect. The market for inference hardware is growing faster than almost anyone predicted.
Here's the macro picture: Large language models work fine now. Chat GPT works. Claude works. Gemini works. The quality bar has been met. What companies care about now is cost and speed. Running a model costs money. The cheaper and faster, the better.
That creates a few dynamics:
Companies are deploying more models: Instead of one big model doing everything, companies are deploying specialized models for different tasks. Customer service bot. Content moderation. Data extraction. Recommendation engine. Each one is a separate inference workload.
Inference volume is exploding: As models get deployed to more use cases and more users, the number of inference requests grows exponentially. A chatbot company might handle millions of requests per day. Scale that across thousands of companies, and you're talking about trillions of inferences per day globally.
Cost per inference matters: At trillion-scale inference, tiny differences in efficiency compound into massive cost differences. A 10% improvement in power efficiency means millions of dollars saved per year. That's why companies are willing to switch chip suppliers. The savings are real and material.
Latency matters for user experience: When a user asks an AI question, they expect an answer in 1-2 seconds, not 5 seconds. That requires low-latency hardware. Different workloads have different latency requirements, but "fast" consistently beats "cheaper but slower."
These dynamics create a market opportunity that Nvidia can't fully address because Nvidia optimized for a different era.
Nvidia's H100 and H200 chips are optimized for training throughput and maximum model size. They excel at moving massive amounts of data through neural networks simultaneously. That's perfect for training. It's overkill for inference.
Positron's Atlas is optimized for the actual inference workload. Faster latency. Lower power. That's a better fit for what customers are actually doing.
The market for inference chips is forecast to grow dramatically. Some estimates put the inference chip market at $30+ billion by 2028. That's not tiny. That's enormous. And that's a market that didn't even exist five years ago.
Positron is entering this market at the right moment with the right product for the right buyer.
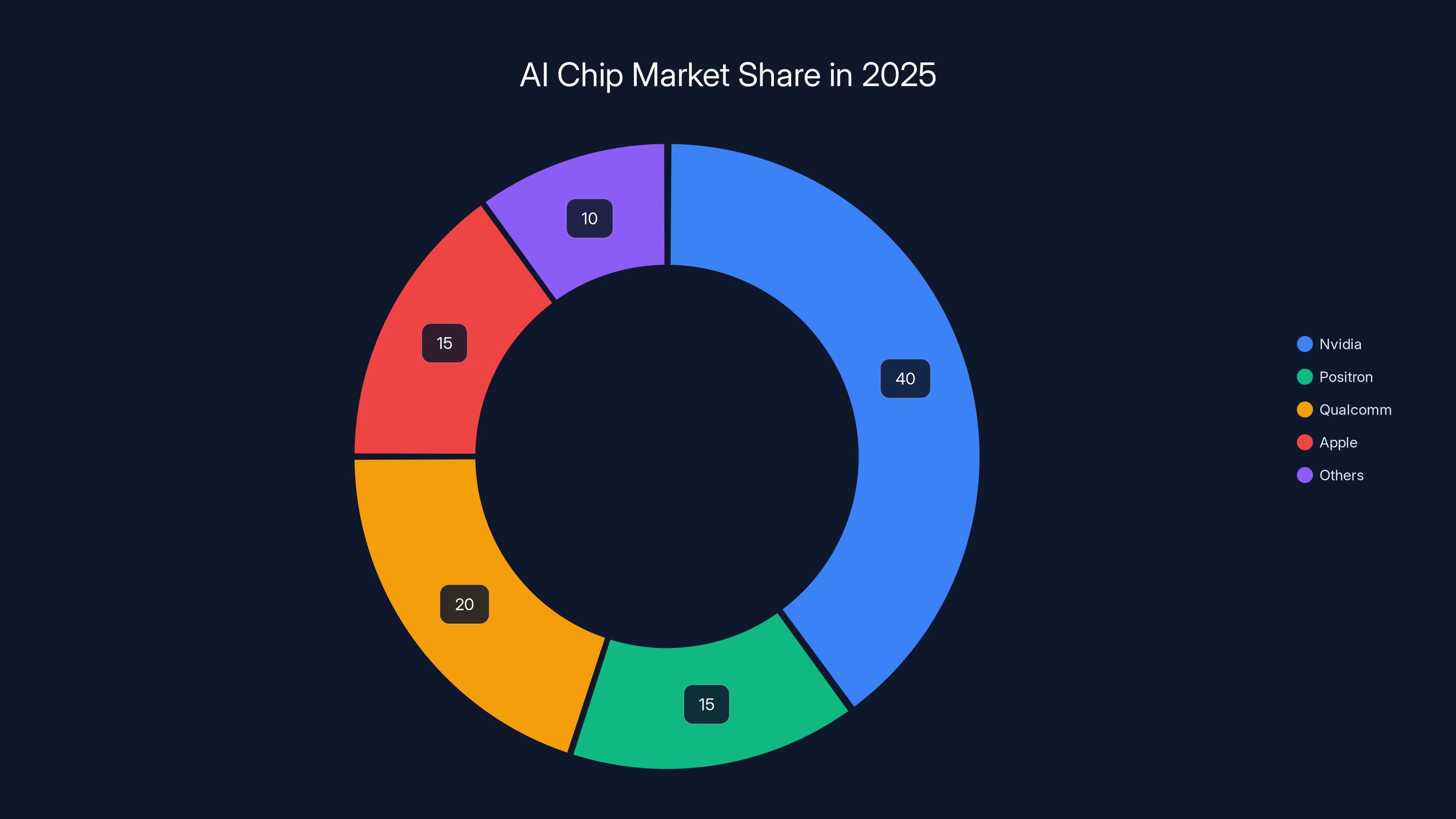
Estimated data shows Nvidia leading in training, but Positron and others capturing significant shares in inference and mobile segments by 2025.
Competing With Nvidia: What The Landscape Actually Looks Like In 2025
Here's what often gets misunderstood: It's not Positron vs. Nvidia anymore. It's not about one company "winning" and one company "losing."
The chip market is fragmenting into specializations. Companies are realizing that one chip can't be optimal for every workload. Nvidia is still the best for many training workloads. But that's not the only game in the market anymore.
The competitive landscape looks something like this:
For training: Nvidia still dominates, but Meta, Microsoft, and others are exploring custom chips. AMD is improving. Intel is iterating.
For inference on consumer/edge devices: Companies like Qualcomm, Apple, and others dominate with specialized mobile chips.
For inference on servers: This is where Positron plays. And this is where there's genuine competition now.
For specific domains: Cerebras, Graphcore, and others are building specialized chips for specific workloads (language models, vision models, graph processing, etc.).
The market is diversifying. Nvidia's dominance is real, but it's increasingly restricted to specific workload categories rather than "all AI compute."
Positron's strategy is sound: dominate server-side inference chips. Don't try to beat Nvidia at training. Don't try to compete in mobile. Focus on the workload where they've designed the best solution.
If Positron captures even 10-15% of the inference chip market, they'd be worth multiple billions. That's why the funding is substantial. That's why the backers are serious. That's why this matters.
The OpenAI Factor: Why Nvidia's Biggest Customer Matters
OpenAI's dissatisfaction with Nvidia's latest chips is significant because it signals something more important than any single customer complaint.
OpenAI is not a typical buyer. They're not a company using Nvidia chips for normal inference workloads. They're running massive training operations, massive inference operations, and they're doing it at a scale that only a handful of companies globally can match.
When OpenAI says "Nvidia's chips aren't meeting our needs," they're not complaining about minor issues. They're saying "we can use our engineering resources to build better solutions for our specific workload."
That's a signal to every other large company: if you're big enough and you have engineering resources, you should be exploring alternatives to Nvidia. And many are.
But here's the important nuance: OpenAI exploring alternatives doesn't mean they're abandoning Nvidia. It means they're building a mixed infrastructure. They might use Nvidia for some workloads, custom chips for others, and third-party providers like Positron for specific use cases.
That's the real dynamic. It's not "replace Nvidia entirely." It's "use Nvidia for what Nvidia is best at, and use other solutions for what they're better at."
Positron's target customer is exactly this company: large enough to care about efficiency, sophisticated enough to understand specialized hardware, and willing to integrate multiple chip suppliers into their infrastructure.
Those are the companies that will drive Positron's growth.
Manufacturing Reality: How Positron Actually Gets Chips Into Customer's Hands
Here's where the rubber meets the road: designing a chip is one thing. Manufacturing it reliably at scale is completely different.
Positron says Atlas is manufactured in Arizona. That's vague because there are actually limited foundries in Arizona that can manufacture advanced AI chips. Most likely, Positron is working with a foundry partner. The specifics matter less than the fact that they've solved the manufacturing problem.
Getting chips designed, manufactured, tested, and shipped at scale requires:
Foundry relationships: You need a manufacturing partner with capacity, reliability, and the specific process nodes you need. TSMC dominates this space, but Samsung and others have grown their capability. Getting a slot on a foundry's wafer starts is non-trivial and requires both capital and good relationships.
Process node optimization: Modern AI chips are manufactured on cutting-edge process nodes (5nm, 3nm). These require specialized expertise. Positron had to optimize their design for the specific process node their foundry uses.
Supply chain: Getting the raw materials, handling the testing infrastructure, managing yield rates. All of this is execution-heavy work.
Quality assurance: When your chip goes into production environments running mission-critical workloads, failures are unacceptable. Quality assurance is expensive.
The fact that Positron has raised $300 million and is focused on getting Atlas into production suggests they've solved these manufacturing challenges. But this is where execution becomes critical. A design that looks good on paper but can't be manufactured reliably at scale is worthless.

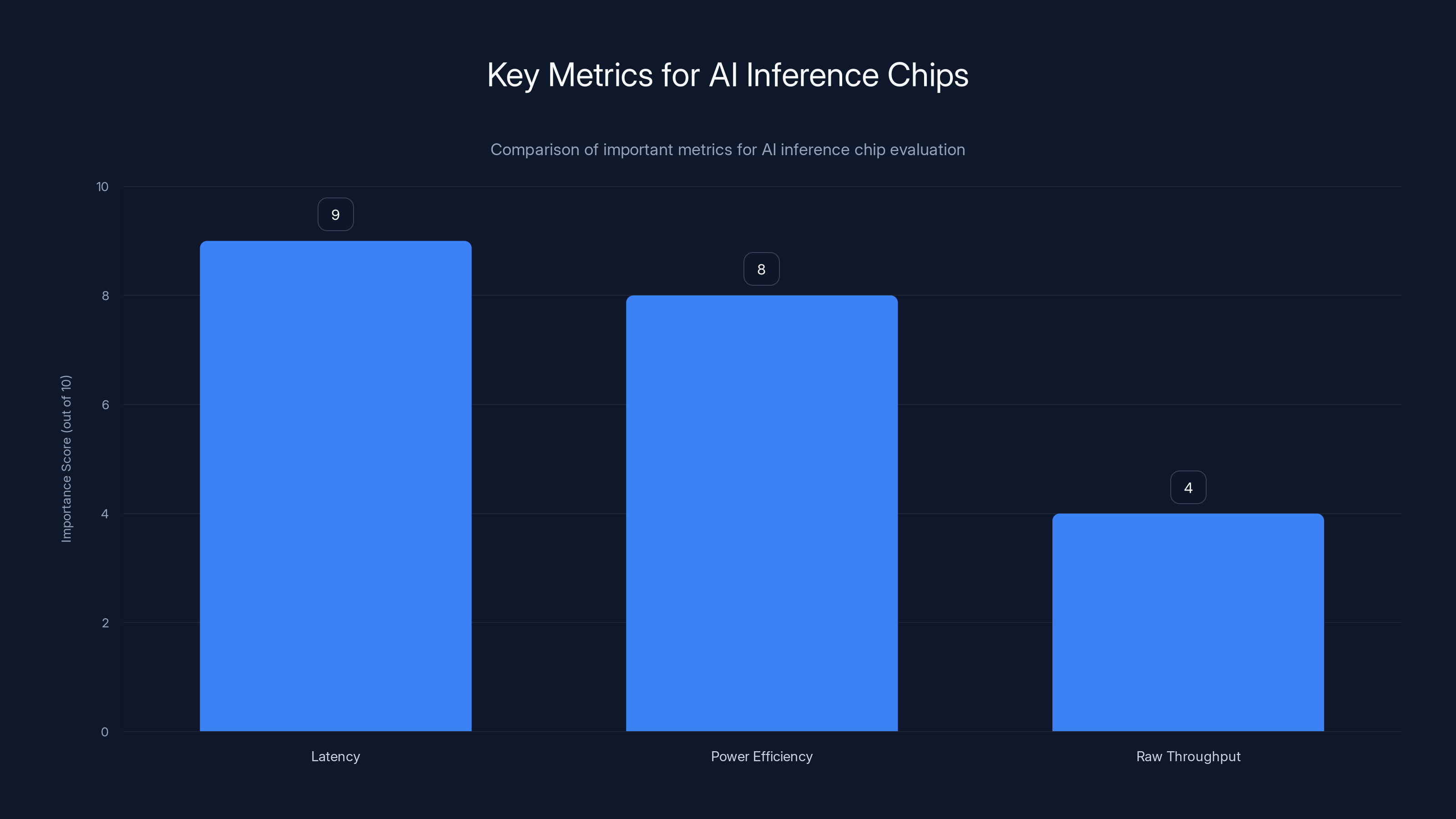
Latency and power efficiency are crucial for AI inference chips, scoring higher in importance compared to raw throughput, which is more relevant for training.
Customer Traction: Who's Actually Buying These Chips?
The article mentions that sources indicate Positron's chips "perform strongly in high-frequency and video-processing workloads," but notably doesn't name specific customers.
That's probably intentional. Companies often keep chip supplier relationships confidential for competitive reasons. If Company X uses Positron chips, they might not want competitors to know (since it reveals something about their infrastructure). So Positron and their early customers are probably keeping specific deals quiet.
But the fact that the company is making this round, and that serious institutional investors are backing it, suggests they have real traction. VCs and sovereign wealth funds don't invest $230 million in companies that have no customers.
Most likely scenario: Positron has signed design wins with 2-4 major customers. These customers have tested Atlas, proven it works for their use cases, and committed to volumes. Those design wins justify the funding round.
The next 18-24 months will show whether Positron can actually scale production to meet demand. That's where most hard tech startups fail. They get the technology right and the first customer right, but then they can't scale manufacturing without destroying quality or exceeding their capital.
Positron's funding level suggests they've thought about this. But execution is what matters.
The Broader Ecosystem: How Positron Fits Into The Larger AI Infrastructure Industry
Positron isn't operating in a vacuum. They're part of a larger ecosystem of companies that are reshaping AI infrastructure.
Compute: Companies like Lambda Labs, Core Weave, and others are building GPU cloud platforms that let companies rent compute capacity. They need efficient hardware to maximize profitability.
Software: Companies are building software stacks that optimize for specific hardware. MLIR, NVIDIA CUDA, Open CL, and emerging standards. Positron will need good software support to be useful.
Serving: Companies like v LLM and others are building model serving infrastructure that optimizes how models are deployed on hardware. Better software can make hardware more efficient.
Quantization and optimization: Companies are developing techniques to make models run faster and cheaper. INT8 quantization, pruning, distillation. These techniques work better on some hardware than others.
Positron's chips work well within this ecosystem, but they need software support to be truly competitive. That's a challenge that Nvidia solved over years. Positron is solving it now. It's doable, but it takes time and engineering resources.

Market Dynamics: Pricing Power And The Race To The Bottom
Here's a harsh truth about the chip market: it's headed toward commoditization in some segments.
Once inference chips become mature technology (which is happening), the market will likely become competitive on price. Companies will shop around. Switching costs will decrease. Margin pressure will increase.
Positron's advantage right now is they're early with a good solution. They can establish customer relationships and mind share before the market gets truly crowded.
But five years from now, there might be dozens of companies making inference chips. At that point, price competition will be fierce. The winners will be companies that:
- Have the lowest manufacturing cost
- Have the best software ecosystem
- Have the strongest customer relationships
- Have the most efficient architectures
- Can iterate quickly
Positron needs to use their funding and early market position to build competitive advantages that are harder to copy than just the chip design itself.
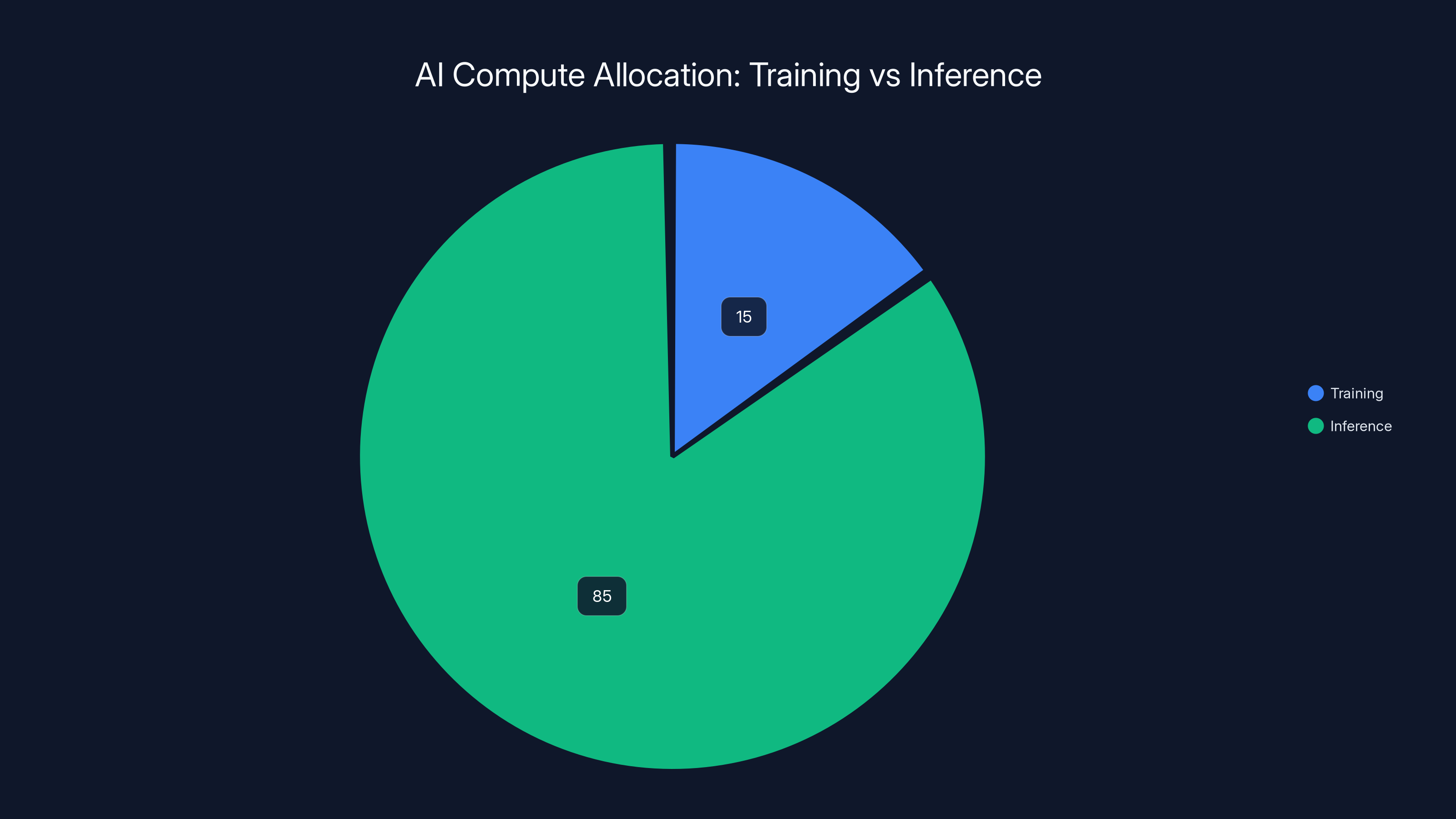
Currently, 85% of AI compute is dedicated to inference, while only 15% is used for training. This highlights the strategic focus on inference workloads in the AI infrastructure market.
Looking Ahead: What Positron Needs To Prove In The Next 18 Months
Positron is now in a critical phase. They have capital, they have backing, they have a chip design. What they need to prove is that they can actually build a business.
Revenue: They need to convert design wins into actual revenue. First customers shipping in production at scale.
Manufacturing scale: They need to prove they can manufacture reliably and increase production without quality degradation.
Customer retention: They need to prove their early customers are happy and placing repeat orders.
Second-generation development: They need to start working on Atlas II while ramping Atlas production. The chip industry moves fast.
Team: They need to build a world-class team of engineers, sales people, and operations folks. Hard tech requires excellent execution.
Ecosystem support: They need software libraries, documentation, and support. They need to make it easy for customers to use their chips.
The next 18 months will show whether Positron can move from "promising startup" to "serious company." The funding gives them the runway to do it. Whether they actually do is a different question.

Why This Matters For The Broader AI Industry
Positron's $230 million Series B matters because it proves that Nvidia's dominance isn't inevitable.
For years, conventional wisdom said: Nvidia is too far ahead. Their manufacturing relationships are too strong. Their software ecosystem is too mature. Nobody can compete.
Positron is proving that's not quite true. If you focus on a specific workload (inference), if you design chips optimized for that workload, and if you have smart backing, you can build something competitive.
That has ripple effects:
For customers: More chip options mean more competition, better pricing, better performance optimization for specific workloads.
For the AI industry: Reducing dependence on a single supplier is healthy. It creates redundancy, encourages innovation, and prevents lock-in.
For sovereign nations: Reducing dependence on foreign chip suppliers becomes possible. Countries can invest in local alternatives.
For innovation: Competition drives innovation. Nvidia has less reason to move fast if they face no competition. Positron's existence might actually accelerate Nvidia's innovation.
For the chip industry: Hard tech companies can still be successful if they focus on specific problems and execute well. This encourages more investment in chip companies.
So Positron's $230 million round is big not because it changes the market overnight, but because it signals a longer-term shift in how the AI infrastructure market will evolve.
The Inference Workload Opportunity: Where The Money Actually Is
Let's get concrete about the economic opportunity in inference chips.
Suppose a hyperscaler is running 10 trillion inference requests per year (plausible for a large company). If they save
But inference efficiency compounds. More efficient chips mean you need fewer data centers. That's power, cooling, real estate. More efficient chips mean faster response times, which users prefer. Better user experience means more engagement, which means more value.
An improvement in inference efficiency doesn't just save 1-10% on chip costs. It can reshape your entire economics.
That's why companies are willing to evaluate alternative chip suppliers. That's why Positron's focus on inference is smart. That's why the $230 million funding round makes sense.
The inference market is massive and growing. Positron is positioned well to capture significant share.

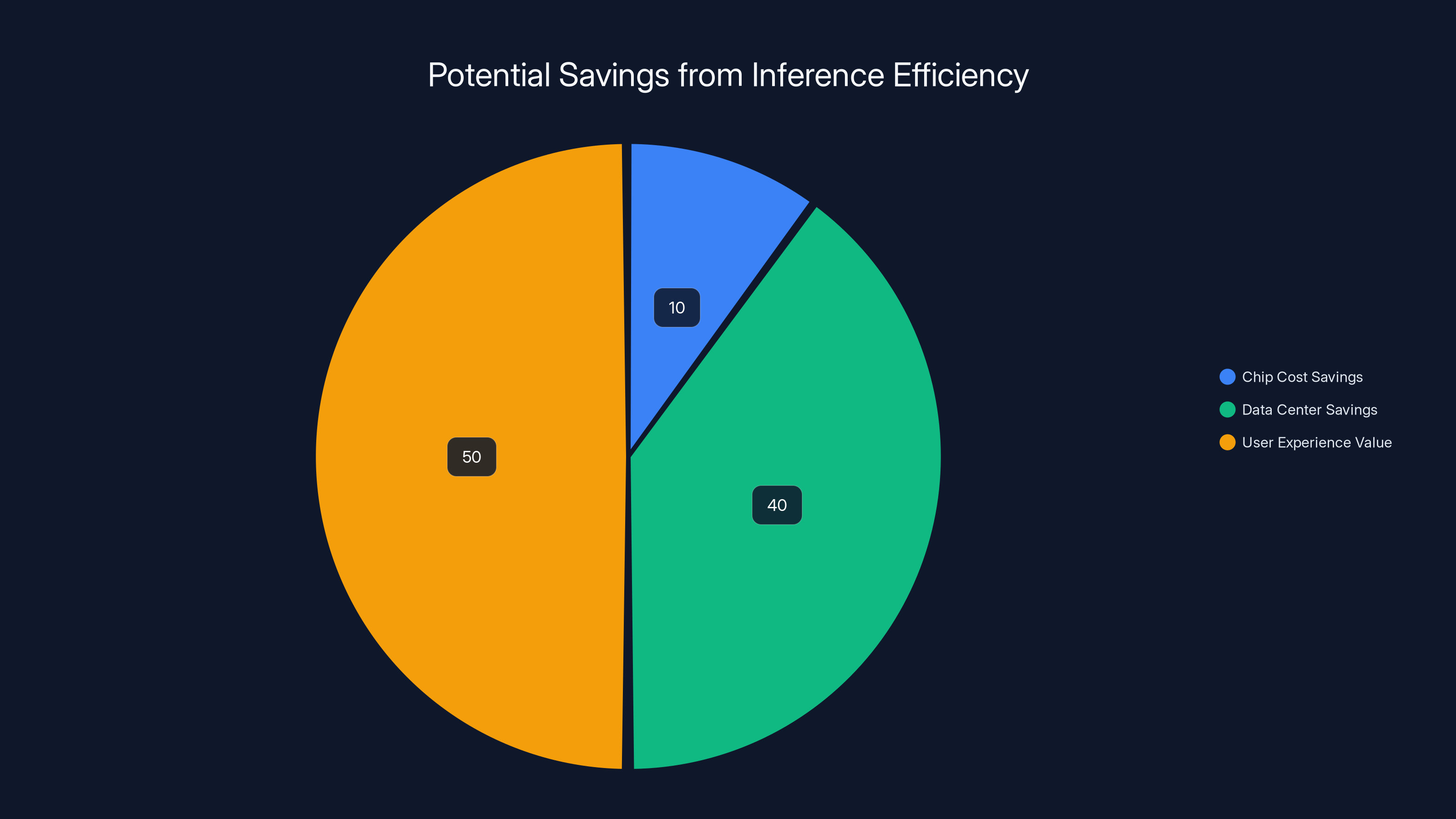
Estimated data shows that while chip cost savings are significant, the majority of economic benefits from inference efficiency come from data center savings and enhanced user experience.
Understanding The Technical Moat: What Would Be Hard To Copy
Here's a question: if Positron's design is so good, why hasn't Nvidia copied it?
The answer reveals something interesting about the chip industry. A good design takes time to copy because:
Architecture integration: Positron's design is tuned to work together as a system. Every component is optimized for inference workloads. Changing one component affects others. You can't just swap in Positron's memory subsystem into Nvidia's architecture.
Manufacturing process node: Chip designs are specific to their process node. A design optimized for TSMC 5nm is different from a design optimized for Samsung 3nm. Porting designs between foundries is hard.
Software ecosystem: Positron's chips need software support. As developers build libraries and tools optimized for Positron architecture, it becomes harder for competitors to catch up.
Customer relationships: Once customers integrate Positron chips into their infrastructure and hire engineers who know how to use them, switching costs increase.
Ongoing iterations: Positron can improve the design with Atlas II, Atlas III. If they're faster at iteration than Nvidia, they stay ahead.
So Positron's advantage isn't that their design is perfect and uncopyable. It's that they're focused, moving fast, and building moats through software, customer relationships, and iteration speed.
Nvidia will eventually respond. They'll probably release inference-optimized chips. But by the time they do, Positron will already have relationships, software, customer momentum. That's a harder position to dislodge.
The Broader Trend: Customization Over Generalization
Positron's success (if it happens) will be part of a larger trend: moving from generalized chips to customized chips.
Nvidia's H100 is a generalized chip. It works reasonably well for training, inference, video processing, graphics, and a dozen other things. But it's not optimal for any single thing.
The future is specialized. Tesla has chips optimized for autonomous driving. Google has TPUs optimized for language models. Nvidia has some specialty chips (Blue Field for networking). Companies increasingly are asking: why buy a generalized chip when we can buy or build one optimized for our specific workload?
Positron is betting on inference specialization. Others will bet on other specializations. Over time, the chip market fragments into dozens of specialized niches instead of a few generalized winners.
Nvidia's long-term challenge is that their business model was built on selling generalized chips at scale. If the market fragments into specializations, their volumes decrease and margins compress. That's the real threat, not Positron specifically, but the trend Positron represents.

Geopolitical Implications: Decoupling From Supply Chain Concentration
Qatar's involvement in this round highlights something important: the geopolitical dimension of AI infrastructure.
For decades, the U.S. and its allies have benefited from controlling advanced chip manufacturing and chip design. Taiwan (through TSMC and others) manufactures most chips. The U.S. (through Nvidia, Intel, AMD, etc.) designs high-performance chips. Other countries are dependent on these suppliers.
That dependency creates risk. If you can't access chips, your AI infrastructure stalls. That's why countries are investing in alternatives:
China is investing in indigenous chip design and manufacturing (Hi Silicon, SMIC). The U.S. is restricting their access to advanced chips, which creates even more incentive to build alternatives.
Europe is investing in European chip companies and manufacturing.
Middle East countries like Qatar are investing in companies like Positron that can provide alternatives to Nvidia.
This isn't about Positron specifically. It's about the global dynamic where every major region wants to reduce dependence on a single supplier located in a specific country.
Positron benefits from this dynamic because they're offering a real alternative. Qatar benefits because they get a seat in an emerging chip company that could become critical infrastructure globally.
Over the next decade, this geopolitical driver will probably be as important as the technical and economic drivers in determining which chip companies succeed.
What Success Looks Like For Positron
If I were advising Positron, here's what success looks like:
Year 1 (2025): Achieve volume manufacturing of Atlas. Ship to 3-5 major customers. Reach $10-50M in revenue. Establish software support ecosystem. Prove manufacturing reliability.
Year 2 (2026): Grow customer base to 10+ companies. Reach $100M+ in revenue. Start development of Atlas II (next-gen chip). Build brand recognition in the industry.
Year 3-5: Atlas II ships. Revenue scales to $500M+. Positron becomes a recognized alternative to Nvidia for inference workloads. Plan Series C or IPO.
That's an aggressive but achievable timeline. Lots of hard tech companies have done it. Positron has the capital, the backing, and the technology. What they need is execution.

Realistic Risks And Challenges Positron Faces
Let me be honest about the risks. Positron could fail for various reasons:
Manufacturing delays: Getting chips manufactured reliably is harder than it sounds. A six-month delay in ramp-up kills momentum.
Design flaws discovered in production: Sometimes chips work in simulation but have issues at scale. Finding and fixing those takes time and money.
Software ecosystem slower than expected: Getting developers to write software for a new chip architecture is hard. If adoption is slow, customers won't adopt the chip.
Nvidia responds faster: Nvidia might release an inference-optimized chip that's good enough and cheaper than Positron's. Nvidia's brand and relationships give them advantages.
Customer concentration: If 50% of revenue comes from one customer, and that customer switches, the company is in trouble. Diversifying customers is hard.
Funding drought: Chip development is capital-intensive. If funding dries up, the company dies. The next round (Series C) will be hard.
Talent acquisition: Top chip engineers are in demand. Attracting them from Nvidia and others is expensive and competitive.
Positron has the capital and backing to navigate most of these risks. But execution risk is real in hard tech. Lots of well-funded companies fail. Positron could too.
The Economic Math: Why The Funding Level Makes Sense
Let's do rough math on why $230 million is the right funding level for this stage.
Chip development and manufacturing requires:
Design: 50-100 top engineers for 2-3 years =
Total: $200-300M.
Positron raising
The funding level signals that Positron has a realistic plan and realistic runway. That's another bullish signal.

Lessons For Other Chip Startups
Positron's success (so far) offers lessons for other companies trying to compete in AI chips:
Pick a specific workload: Don't try to be Nvidia 2.0. Pick a specific problem (inference, video, quantized models, etc.) and be the best at that.
Optimize ruthlessly: Every design choice should optimize for your specific workload. Don't include features for workloads you don't care about.
Solve manufacturing early: Lots of chip startups fail because they design great chips but can't manufacture them. Positron solved this early.
Get strategic backing: Positron got Qatar, Valor, Atreides. These are smart backers who understand hard tech. That backing is worth as much as capital.
Build ecosystem support: The best chip in the world is useless without software libraries, documentation, developer support.
Focus on customer pain: Positron focused on the specific pain (power efficiency, latency) that inference customers cared about. That drove customer adoption.
These lessons apply to any hard tech company trying to compete against entrenched leaders.
The Competitive Landscape In 2025
Here's who else is competing in the chip space, and why Positron's position is interesting:
Nvidia: Still dominant for training. Pursuing inference with newer architectures. Hard to beat.
AMD: Improving EPYC and MI chips. Good competitor but hasn't captured the cultural "must-have" status that Nvidia has.
Intel: Iterating on Gaudi and Arc lines. Financially strong but has execution issues.
Cerebras: Building specialized chips for language models. Good technology but niche market.
Graphcore: Building specialized chips for AI workloads. Had funding issues, recent pivot.
Qualcomm: Dominant in mobile AI chips. Not competing in server inference yet.
Custom chips: Meta, Google, Microsoft, Amazon all building custom chips. But these are for internal use, not sold to others.
Positron: Focused on inference, available to customers, well-funded. Emerging player with strategic backing.
In this landscape, Positron has a real opportunity. They're focused, well-backed, and solving a real problem. Execution will determine whether they succeed.

Looking Further Ahead: 2025-2030 Projections
If I had to project where this goes, I'd say:
By 2028: Positron is a billion-dollar company by valuation. They've shipped several generations of chips. They have dozens of customers. They've captured 5-10% of the inference chip market.
By 2030: Positron might be acquired by a larger company (Qualcomm, Intel, or a hyperscaler building vertical integration) for $10B+. Or they IPO. Either way, they've proven the model works.
Alternatively, Positron could fail to scale, get out-competed by Nvidia or others, and remain a niche player. That's a real risk.
But if current trends continue, and if they execute well, Positron's trajectory points toward significant success.
The AI infrastructure market is growing fast enough to support multiple chip suppliers. Positron is positioned to be one of them.
Conclusion: The Beginning Of The End Of Chip Monopoly
Positron's $230 million Series B is important not because it changes the market overnight, but because it signals something deeper: the era of Nvidia monopoly dominance in AI chips is coming to an end.
That doesn't mean Nvidia loses its position. They'll remain a major player, probably for decades. But the assumption that they'll own all AI chip demand is dying.
Instead, we're heading toward a diversified market where different companies own different segments:
- Nvidia maintains training dominance
- Positron captures inference
- Others specialize in video, quantized models, edge devices, or other niches
- Custom chips from big companies handle their internal needs
This is actually healthier for the industry. Competition drives innovation. Specialization means better products. Reducing dependence on a single supplier creates stability.
For companies evaluating chip options, Positron is worth serious consideration if you're running inference workloads at scale. Their chips could save you significant money and give you faster response times.
For investors, Positron is an interesting long-term play. They're in the right market at the right time with the right product. Execution risk is real, but the upside is substantial.
For the broader AI industry, Positron represents proof that incumbents can be challenged when they're optimizing for yesterday's workload. That's a good thing. It keeps the industry honest and drives everyone to innovate faster.
The chip wars are just getting started. Positron is a credible new combatant in a war that Nvidia has dominated alone for far too long. That's the real story of this $230 million round.

FAQ
What is Positron and what do they do?
Positron is a semiconductor startup based in Reno, Nevada, founded three years ago with a focus on developing high-performance AI chips. The company specializes in creating memory chips and processors specifically optimized for AI inference workloads, rather than the training workloads that most AI chips are designed for. Their first-generation chip, called Atlas, is manufactured in Arizona and targets the growing demand for efficient, cost-effective inference processing in data centers and cloud environments.
How does Positron's Atlas chip differ from Nvidia's H100?
Positron's Atlas chip is specifically engineered for inference workloads, while Nvidia's H100 is optimized for training large language models. The key difference is that Atlas can deliver similar inference performance to an H100 while consuming less than one-third of the power, making it significantly more energy-efficient and cost-effective for companies running inference at scale. Additionally, Atlas demonstrates strong performance in video processing workloads and operates at higher clock frequencies for improved latency, features that are particularly valuable for real-time AI applications rather than batch training operations.
Why is inference chip development important right now?
Inference has become the dominant workload for AI systems in production. While training requires enormous computational resources concentrated in a few organizations, inference is distributed across thousands of companies running trillions of requests daily. As businesses shift from building massive new models to deploying existing models at scale, the demand for efficient inference hardware has exploded. Power consumption, latency, and cost per inference are now more important than raw training throughput, creating a market opportunity where specialized inference chips can outperform general-purpose training chips.
What does Qatar's investment signify about the market?
Qatar Investment Authority's participation in Positron's Series B signals that sovereign wealth funds and governments view AI chip infrastructure as strategically critical, similar to energy or defense resources. Qatar's broader $20 billion AI infrastructure joint venture with Brookfield Asset Management demonstrates that reducing dependence on foreign chip suppliers has become a priority for nations seeking to build competitive advantages in the global AI economy. This geopolitical dimension adds legitimacy to Positron's mission and suggests that demand for alternatives to Nvidia will only increase as countries pursue strategic autonomy in AI infrastructure.
Can Positron actually compete with Nvidia long-term?
Positron's focused strategy of specializing in inference workloads gives them a fighting chance where a direct Nvidia competitor would fail. While Nvidia maintains advantages in training, relationships, and brand recognition, Positron's engineering teams have optimized specifically for a workload where Nvidia's general-purpose design is suboptimal. Success depends on execution: manufacturing reliability, customer satisfaction, software ecosystem development, and rapid iteration. If Positron achieves these, they can capture significant market share in the inference segment over the next 5-10 years, though Nvidia will likely respond with competitive inference-optimized offerings.
What are the realistic risks for Positron's business?
Positron faces several material risks including manufacturing delays or quality issues that could derail product launches, slower-than-expected software ecosystem adoption that limits chip appeal, Nvidia releasing competitive inference chips with their existing relationships and resources, customer concentration where a few large customers represent the majority of revenue, and the perpetual hard tech risk of capital running out before profitability. Additionally, competing startups and established vendors may release similar inference-optimized chips, potentially commoditizing the market faster than Positron can scale revenue. Talented chip engineers are in high demand and expensive to retain, which creates ongoing competitive pressure for staffing.
How does Positron's business model differ from Nvidia's?
Unlike Nvidia, which sells chips to a wide range of customers across training, inference, gaming, and other domains, Positron is focused exclusively on one customer segment (companies running inference workloads) and one application type (efficient inference processing). This specialization allows Positron to optimize their chip design ruthlessly for specific customer pain points without trade-offs for other use cases. However, this also means Positron has a smaller addressable market than Nvidia, though the inference market alone is large enough to support a multi-billion dollar company if execution succeeds.
What is the timeframe for Positron achieving significant market traction?
Based on typical hard tech development cycles, Positron's critical proving period is the next 18-24 months. During this time, they need to demonstrate manufacturing reliability, ship to multiple major customers in volume, achieve meaningful revenue (tens to low hundreds of millions), and establish strong software ecosystem support. If they achieve these milestones, the following 3-5 years should see acceleration to multi-billion dollar valuations. If they encounter major manufacturing issues, customer adoption challenges, or funding constraints, the timeline could extend significantly or the company could encounter existential threats.
How will the broader AI chip market evolve with competition from Positron and others?
The AI chip market is likely to fragment into specialized segments rather than remaining concentrated under a single dominant vendor. Different chips will emerge as optimal for different workloads: training, inference, edge processing, video analysis, specialized tasks like quantized models or graph processing. This specialization mirrors how the broader semiconductor industry evolved, where Intel dominates general-purpose CPUs while Qualcomm leads mobile processors and custom vendors handle specific domains. Positron's emergence suggests we're witnessing the beginning of that diversification in the AI space, which should ultimately benefit customers through more competition and better price-to-performance ratios.
What should companies consider when evaluating whether to adopt Positron chips?
Companies should evaluate Positron primarily if they operate at scale running inference workloads where power efficiency and latency directly impact economics. The key questions are: Does inference represent a significant portion of your AI spend? Would cutting power consumption by 60-70% provide meaningful cost savings? Can your engineering team integrate a new chip supplier into existing infrastructure? Do you have software talent to optimize for Positron's architecture? If answers are yes, Positron deserves serious evaluation. For companies with small inference workloads or Nvidia lock-in across their stack, the switching costs may not justify adoption yet.
What does Positron's funding mean for the venture capital landscape in hard tech?
Positron's $230 million Series B demonstrates that hard tech startups can still attract institutional capital at substantial levels when they've solved fundamental problems and shown real customer traction. The participation of sophisticated investors like Qatar Investment Authority and experienced hard tech investors like Atreides Management signals that there's renewed confidence in deep-tech startups building difficult, capital-intensive businesses. This contrasts with the venture capital environment of recent years where early-stage hard tech funding became constrained. Positron's success in raising this round likely encourages more funding for other promising chip startups and hardware companies.
Key Takeaways
- Positron's $230M Series B funding represents a watershed moment where alternatives to Nvidia become viable, not speculative
- Inference workloads (deploying AI models) are growing 10x faster than training workloads, creating a market opportunity where Positron's chip design is superior to Nvidia's general-purpose H100
- Qatar's investment signals geopolitical dimension: countries prioritizing sovereign AI infrastructure independence from U.S. suppliers
- Atlas chip's 1/3 power consumption vs H100 creates cascading cost advantages (cooling, electricity, real estate, carbon) worth millions annually at hyperscaler scale
- Chip market is fragmenting from winner-take-all (Nvidia) to specialized segments (inference, training, edge, video), making room for multiple successful companies
Related Articles
- Microsoft's Maia 200 AI Chip Strategy: Why Nvidia Isn't Going Away [2025]
- Space-Based AI Compute: Why Musk's 3-Year Timeline is Unrealistic [2025]
- Nvidia's $100B OpenAI Deal Collapse: What Went Wrong [2025]
- SpaceX Acquires xAI: The 1 Million Satellite Gambit for AI Compute [2025]
- SpaceX Acquires xAI: Creating the World's Most Valuable Private Company [2025]
- SpaceX's 1 Million Satellite Data Centers: The Future of AI Computing [2025]

