
Qwen 3-Max Thinking vs GPT-5.2 & Gemini 3 Pro: AI Reasoning Showdown 2025
Introduction: The Reasoning Model Revolution and Global Competition
The landscape of artificial intelligence has fundamentally shifted. For years, Western laboratories—primarily OpenAI, Google DeepMind, and Anthropic—dominated the conversation around AI capabilities, setting benchmarks that seemed unreachable for competitors. But in early 2025, a significant challenge emerged from an unexpected quarter: Alibaba Cloud's Qwen Team unveiled Qwen 3-Max-Thinking, a proprietary reasoning model that didn't just match the performance of established giants but genuinely outpaced them on rigorous, complex benchmarks.
This development matters far beyond academic interest. The emergence of competitive reasoning models from non-Western AI labs signals a fundamental democratization of advanced AI capabilities. For enterprise teams, startups, and developers evaluating AI infrastructure, this competition suddenly creates more options, better pricing, and—critically—opportunities to build sophisticated AI systems without depending exclusively on a single vendor ecosystem.
The timing is particularly significant because "reasoning models" represent a genuine leap in AI capabilities. Unlike traditional language models that generate tokens sequentially without deeper reflection, reasoning models allocate computational resources to "think through" problems step-by-step, similar to human problem-solving. This architectural difference enables them to tackle Ph.D.-level mathematics, complex coding challenges, and multi-step analytical tasks that previously required human expertise.
When Qwen 3-Max-Thinking achieved a 49.8 score on "Humanity's Last Exam" (HLE)—a benchmark of 3,000 Google-proof graduate-level questions—it surpassed both Gemini 3 Pro (45.8) and GPT-5.2-Thinking (45.5). This wasn't a marginal improvement; it was an 8.7% performance advantage over OpenAI's latest offering and a 8.7% advantage over Google's flagship model. These benchmarks matter because they measure real-world capabilities: the ability to solve problems that cannot be solved through simple web search or memorization.
For organizations making AI infrastructure decisions, this creates an urgent question: What does the emergence of competitive reasoning models mean for your development strategy, vendor selection, and long-term AI roadmap? Should teams still default to established providers, or does competitive pricing and performance justify evaluation of alternatives? What architectural advantages does each approach offer, and how should these technical differences influence your adoption decisions?
This comprehensive analysis examines not just the benchmark numbers, but the fundamental architectural innovations driving Qwen 3-Max-Thinking's performance, how it compares to GPT-5.2 and Gemini 3 Pro across real-world use cases, the economic implications of choosing one model over another, and critically—what this competitive landscape means for teams evaluating reasoning models in 2025.
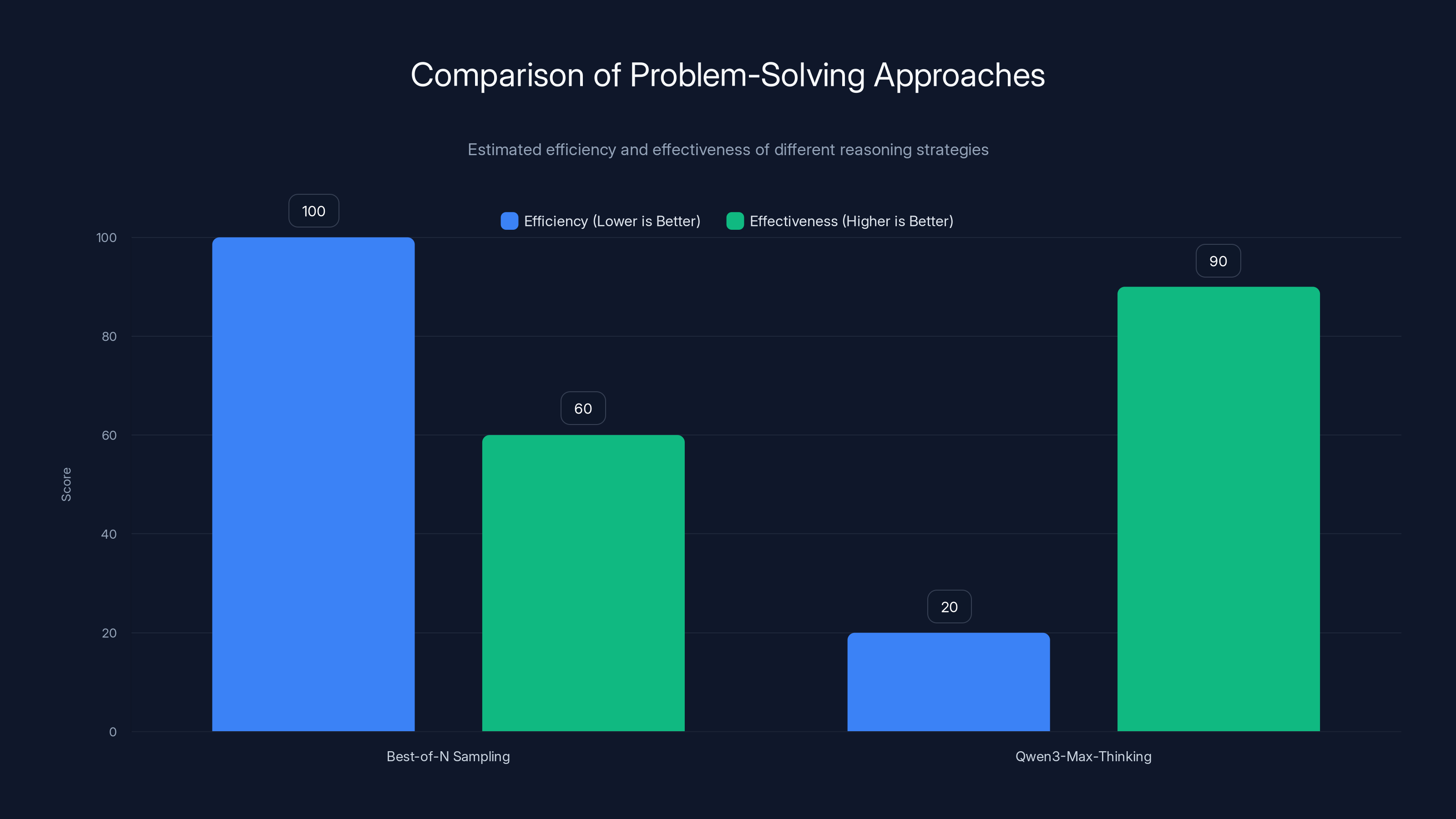
Qwen3-Max-Thinking is estimated to be significantly more efficient and effective than traditional best-of-N sampling, due to its iterative refinement strategy. Estimated data.
Understanding Reasoning Models: From Sequential Generation to Iterative Thinking
What Are Reasoning Models?
Reasoning models represent a fundamental shift in how AI systems approach complex problems. Traditional large language models operate through sequential token generation: they predict the next word, then the next word, then the next, building output token-by-token without pausing to evaluate whether their current reasoning path is sound.
Reasoning models, by contrast, allocate computational resources to "think through" problems before generating final answers. This architectural difference mirrors human cognition—when you solve a complex calculus problem, you don't immediately write down the answer; you work through intermediate steps, check your work, and verify your logic before committing to a response.
The practical impact is profound. On benchmark tests like GPQA (Graduate-level Google-Proof Questions), traditional models might score 60-70% accuracy. Reasoning models on the same benchmarks score 90%+ because they have computational space to verify mathematical steps, check logical consistency, and identify flawed reasoning before finalizing answers.
How Reasoning Models Changed the AI Landscape
When OpenAI introduced reasoning models with GPT-o 1 and subsequently GPT-5.2-Thinking, the industry responded with intense focus. Google rushed to develop Gemini 2 Thinking, and other labs accelerated research into similar architectures. The emergence of Qwen 3-Max-Thinking indicates that this capability is no longer the exclusive domain of Western AI labs; it's becoming a standard feature across competitive AI platforms.
This shift has three critical implications:
First, it elevates the baseline for what constitutes "state-of-the-art" AI. Traditional benchmarks measuring general language understanding become less relevant; instead, performance on reasoning-intensive tasks becomes the primary differentiator.
Second, it changes the economics of AI infrastructure. When reasoning was a scarce capability, organizations paid premium prices for access. As multiple vendors offer reasoning models, competitive pricing pressure emerges, potentially reducing costs by 30-50% compared to previous generations.
Third, it fragments the AI vendor landscape. Organizations can no longer assume that a single provider "owns" the best capabilities; instead, they must evaluate multiple platforms across reasoning performance, integration quality, pricing, and governance considerations.
The Technical Mechanics Behind Reasoning Inference
Reasoning models achieve their capabilities through a process called test-time scaling, which operates fundamentally differently from the training-time scaling that has driven AI improvements for the past decade. Training-time scaling involves collecting more data, using larger models, and deploying more compute during the training phase. Test-time scaling, by contrast, allocates additional compute during inference—the moment when users actually query the model.
This seemingly simple shift has massive implications. It means that instead of a reasoning model generating an answer in milliseconds like a traditional model, it might take 5-30 seconds to think through a complex problem. Users experience this as a latency trade-off for accuracy improvement.
Within the test-time scaling framework, different vendors implement different strategies. OpenAI's approach emphasizes chain-of-thought reasoning—the model explicitly traces through logical steps. Qwen's approach, as we'll explore in detail, emphasizes what the company calls "experience-cumulative, multi-round strategy"—the model reflects on previous reasoning iterations and refines its approach based on what it learns.
Qwen 3-Max-Thinking: Architecture and Innovation
The Core Innovation: Experience-Cumulative Test-Time Scaling
The fundamental architectural innovation driving Qwen 3-Max-Thinking's superior performance is what the Alibaba Cloud Qwen Team describes as experience-cumulative, multi-round reasoning. Unlike simpler approaches that generate multiple candidate answers and select the best one (best-of-N sampling), Qwen 3-Max-Thinking employs an iterative refinement strategy where each reasoning round learns from previous rounds.
Here's how it works mechanically:
When presented with a complex query, the model doesn't immediately attempt a full solution. Instead, it enters a thinking mode where it:
- Formulates initial hypotheses about what the problem is asking and what approach might work
- Tests those hypotheses through simulated reasoning, exploring whether each pathway leads toward or away from a solution
- Identifies dead ends early—recognizing when a particular logical branch won't yield results, without requiring the model to traverse it completely
- Consolidates insights from successful reasoning paths, building up an understanding of the problem structure
- Refines the approach based on what worked and what didn't, redirecting computational resources toward "unresolved uncertainties"
- Generates the final answer only after exhausting promising reasoning pathways and achieving confidence in the solution
This iterative approach offers a critical efficiency advantage: the model avoids redundant reasoning. In traditional best-of-N sampling, if a model generates 100 candidate solutions, it essentially redoes the problem-solving from scratch 100 times. With Qwen 3-Max-Thinking's approach, insights from iteration 1 inform iteration 2, insights from iteration 2 inform iteration 3, and so forth. This cumulative learning means the model becomes progressively more intelligent about the problem as it reasons, requiring fewer total iterations to reach high confidence.
"Heavy Mode" and Test-Time Compute Allocation
Qwen 3-Max-Thinking introduces what the team calls a "heavy mode" of inference—a setting where users can request that the model allocate maximum computational resources to thinking before responding. This contrasts with standard inference where the model prioritizes speed over depth of reasoning.
The practical implication is that users face a latency-accuracy trade-off: standard inference might return an answer in 2-3 seconds but with 85% accuracy on complex problems; heavy mode might require 15-30 seconds but achieve 95%+ accuracy. For use cases where accuracy matters far more than speed—medical diagnosis support, financial risk analysis, scientific research assistance—heavy mode provides a genuine value proposition.
Allocating compute during test-time rather than training-time has a subtle but important implication for vendors: it decouples inference cost from model capability. A vendor can offer the same reasoning model in both fast and slow configurations, with users paying more for longer thinking times. This creates flexible pricing options: teams with tight latency constraints use standard inference and pay standard prices; teams where accuracy is paramount use heavy mode and pay premium prices.
Adaptive Tool Integration and Agentic Autonomy
One of Qwen 3-Max-Thinking's distinctive advantages over pure reasoning models is its integration of adaptive tool use—the ability to autonomously select and deploy external tools without explicit user direction. This capability distinguishes it from models that require users to manually specify which tools to use or what information to retrieve.
The adaptive tool suite includes:
- Web Search & Extraction: Real-time access to current information, critical for queries about recent events, current statistics, or live data
- Code Interpreter: Python execution environment enabling the model to write, test, and debug code during the reasoning process
- Memory Systems: Persistent storage of user context, conversation history, and custom knowledge bases
- Calculation Engines: Specialized mathematical computation capabilities for precise numerical work
What makes this integration "adaptive" is that the model independently evaluates whether a tool is necessary for the current query. If asked "What is 2+2?", the model recognizes that web search and code interpretation are unnecessary—it can answer directly. If asked "What was the GDP growth rate in Japan during Q4 2024?", the model autonomously determines that web search is required because current information isn't reliably in its training data.
This autonomous decision-making matters enormously for agentic workflows—where users describe a goal rather than specific steps, and the AI system determines how to accomplish it. Instead of requiring explicit prompting like "Search for X, then use the code interpreter to calculate Y, then summarize the result," the user simply states the goal and the model orchestrates the necessary tools.
Performance Improvements: Quantified Benchmarks
The performance improvements delivered by Qwen 3-Max-Thinking's architecture are substantial and measurable:
On GPQA (Graduate-level Google-Proof Questions)—Ph.D.-level science questions:
- Previous Qwen 3 iteration: 90.3%
- Qwen 3-Max-Thinking: 92.8%
- Improvement: +2.5 percentage points (+2.8% relative gain)
On Live Code Bench v 6 (real-world coding challenges):
- Previous iteration: 88.0%
- Qwen 3-Max-Thinking: 91.4%
- Improvement: +3.4 percentage points (+3.9% relative gain)
On HMMT Feb 25 (rigorous mathematics reasoning):
- Qwen 3-Max-Thinking: 98.0
- Gemini 3 Pro: 97.5
- GPT-5.2-Thinking: (benchmark score not directly reported, but context indicates lower performance)
- Deep Seek V3.2: 92.5
On "Humanity's Last Exam" with web search (the headline benchmark):
- Qwen 3-Max-Thinking: 49.8
- Gemini 3 Pro: 45.8
- GPT-5.2-Thinking: 45.5
- Improvement over Gemini 3 Pro: +8.7%
- Improvement over GPT-5.2-Thinking: +9.2%
On Arena-Hard v 2 (general reasoning and instruction-following):
- Qwen 3-Max-Thinking: 90.2
- Claude-Opus-4.5: 76.7
- Improvement: +17.6%
These benchmarks deserve careful interpretation. Humanity's Last Exam is particularly significant because it measures performance on questions specifically designed to be "Google-proof"—they cannot be solved through simple information retrieval or memorization. The fact that Qwen 3-Max-Thinking achieved 9.2% higher performance than GPT-5.2-Thinking on this benchmark suggests that Qwen's architecture for combining reasoning with web search integration is genuinely superior to OpenAI's approach on this particular problem class.
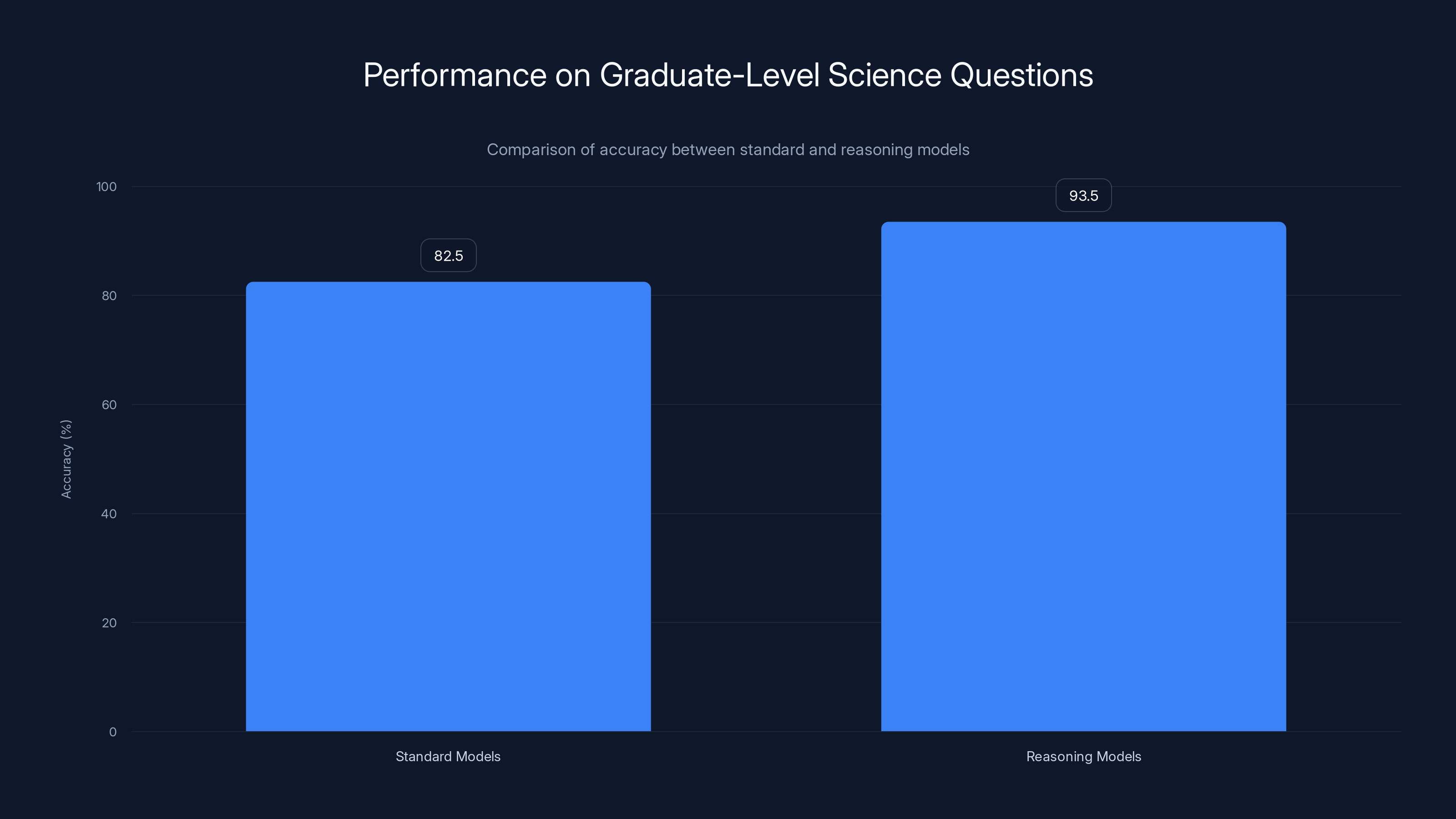
Reasoning models achieve higher accuracy (92-95%) on complex science questions compared to standard models (80-85%). Estimated data.
GPT-5.2-Thinking: OpenAI's Reasoning Architecture
Development Timeline and Positioning
OpenAI's reasoning models emerged from the company's work on chain-of-thought prompting, a technique where models are encouraged to work through problems step-by-step rather than jumping immediately to answers. This research eventually evolved into dedicated reasoning model architectures, first introduced with GPT-o 1 and subsequently refined with GPT-5.2-Thinking.
OpenAI's strategic positioning emphasizes that reasoning models represent a fundamental new paradigm in AI—one where compute allocation during inference becomes as important as model scale. This represents a departure from the previous scaling mentality where "bigger always meant better," instead introducing nuance: different problem types benefit from different amounts of thinking time.
GPT-5.2-Thinking integrates reasoning capabilities with OpenAI's multimodal architecture, enabling the model to reason about both text and images. This is relevant for use cases where visual reasoning—analyzing charts, diagrams, screenshots—is important.
Reasoning Mechanism and Chain-of-Thought Implementation
OpenAI's approach to reasoning emphasizes explicit chain-of-thought processes. When operating in thinking mode, GPT-5.2-Thinking generates reasoning tokens—intermediate steps that trace the logical pathway from problem to solution. These reasoning tokens are computationally expensive (they don't contribute to the final output that users see) but they enable deeper problem-solving.
The user-facing behavior is relatively opaque: when you query GPT-5.2-Thinking in thinking mode, you receive a final answer without seeing the intermediate reasoning steps (though users can optionally request to see the reasoning, depending on their implementation). This contrasts with Qwen 3-Max-Thinking, which more explicitly surfaces its reasoning process.
OpenAI reports that the reasoning mechanism helps the model:
- Verify calculations before stating numerical answers
- Check logical consistency by tracing implications through multiple steps
- Explore alternative approaches when initial attempts fail
- Identify knowledge gaps and work around limitations
Benchmark Performance and Comparative Strengths
While Qwen 3-Max-Thinking achieved higher scores on Humanity's Last Exam, GPT-5.2-Thinking maintains competitive performance on many other reasoning benchmarks:
- MMLU-Pro (advanced knowledge): Strong performance on professional and academic knowledge
- ARC-Hard (science): Reasoning about complex scientific scenarios
- Math QA (mathematics): Multi-step mathematical problem-solving
- APPS (algorithm design): Writing algorithms to solve specified problems
The interesting data point is that GPT-5.2-Thinking, despite being developed by a Western lab with presumably substantial computational resources for training, achieved lower performance than Qwen 3-Max-Thinking on the specific benchmark emphasizing web-augmented reasoning. This suggests that the architectural advantages of Qwen's experience-cumulative approach and its integration of adaptive tooling provide genuine advantages on this particular problem class.
Integration with OpenAI's Ecosystem
A significant advantage of GPT-5.2-Thinking is its integration with OpenAI's broader ecosystem. Teams already using OpenAI APIs, GPT-4o for vision tasks, or fine-tuned models experience relatively seamless migration to reasoning models. The API interfaces are consistent, error handling follows familiar patterns, and integration libraries across multiple programming languages are well-documented.
For teams building production systems on OpenAI infrastructure, choosing GPT-5.2-Thinking doesn't require platform migration or learning new vendor-specific patterns. This ecosystem integration, while not affecting raw reasoning performance, significantly affects total cost of ownership and implementation timeline.
Gemini 3 Pro: Google DeepMind's Response
Google's Reasoning Model Architecture
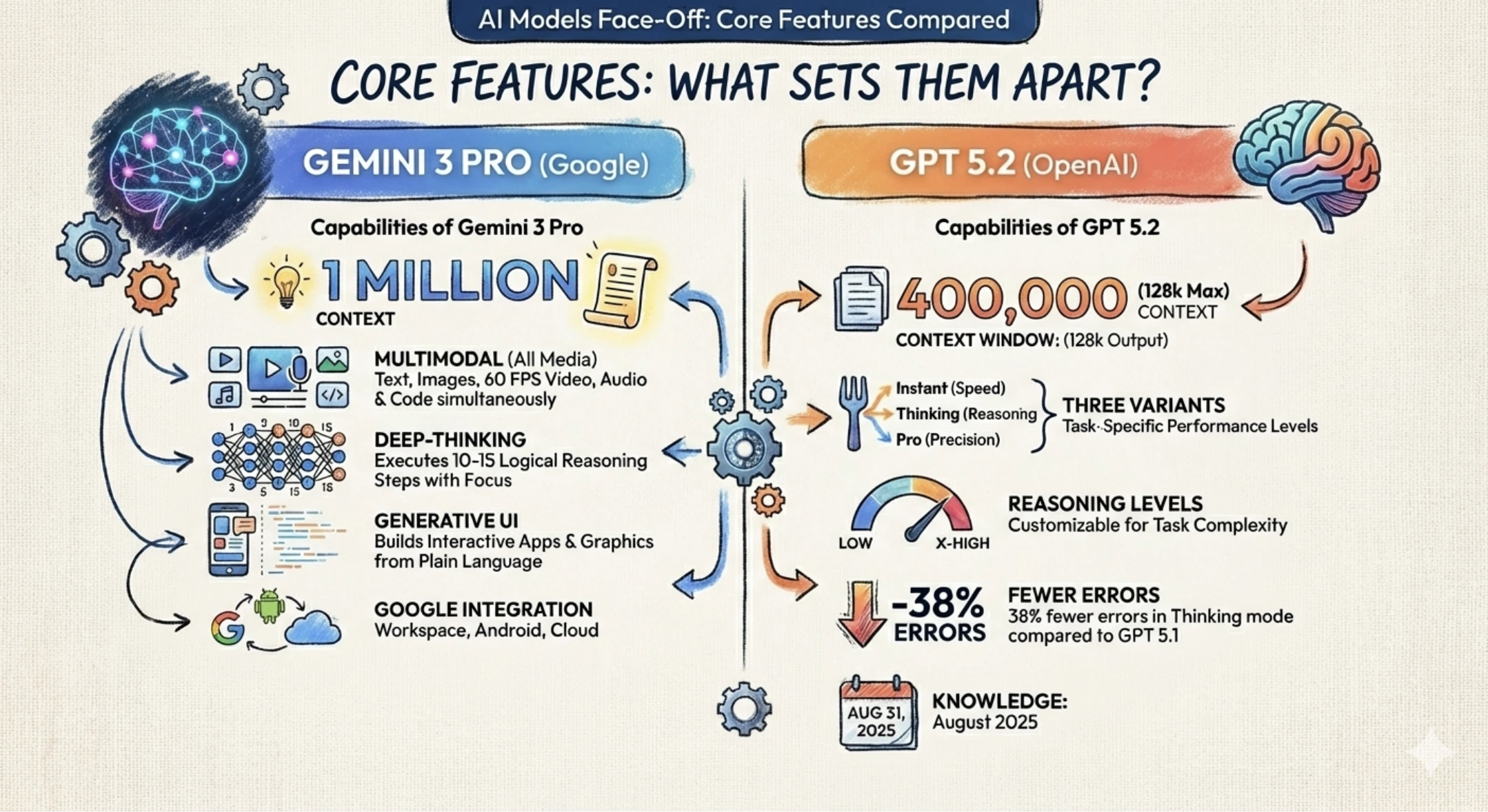
Google DeepMind developed Gemini 3 Pro as its reasoning model offering, incorporating learnings from Gemini 2 and leveraging Google's substantial compute infrastructure. Gemini 3 Pro builds on Gemini's native multimodality—the ability to reason across text, images, video, audio, and code simultaneously.
Google's architectural approach emphasizes inference-time scaling with cross-modal reasoning. Where many reasoning models focus exclusively on text and code, Gemini 3 Pro designed reasoning capabilities that work across modalities. This enables use cases like: analyzing a scientific paper (text) while evaluating supporting charts (images) and running simulations (code)—all within a unified reasoning framework.
The multimodal reasoning capability is genuinely distinctive. If your use case involves analyzing complex documents with embedded visualizations, reasoning about data shown in charts and graphs, or understanding concepts across multiple representation formats, Gemini 3 Pro offers advantages that text-only reasoning models don't provide.
Benchmark Performance Analysis
On Humanity's Last Exam, Gemini 3 Pro achieved 45.8—strong performance but trailing Qwen 3-Max-Thinking's 49.8. On other benchmarks:
- MMLU (broad knowledge): Competitive with other flagship models
- Math QA (mathematics): Strong but not superior to competitors
- HMMT Feb 25 (competition mathematics): 97.5, second only to Qwen's 98.0
The performance profile suggests that Gemini 3 Pro excels at general-purpose reasoning but doesn't demonstrate specific advantages on any single benchmark class. It's a generalist tool rather than a specialist.
Integration with Google Cloud and Vertex AI
For organizations already invested in Google Cloud infrastructure, Gemini 3 Pro offers advantages through tight Vertex AI integration. Google's managed AI platform provides enterprise features like monitoring, audit logging, fine-tuning, and model evaluation tools that are natively integrated with Gemini 3 Pro.
Google also provides more sophisticated access controls and data residency options than some competitors, which matters for regulated industries (financial services, healthcare) where data governance is critical.
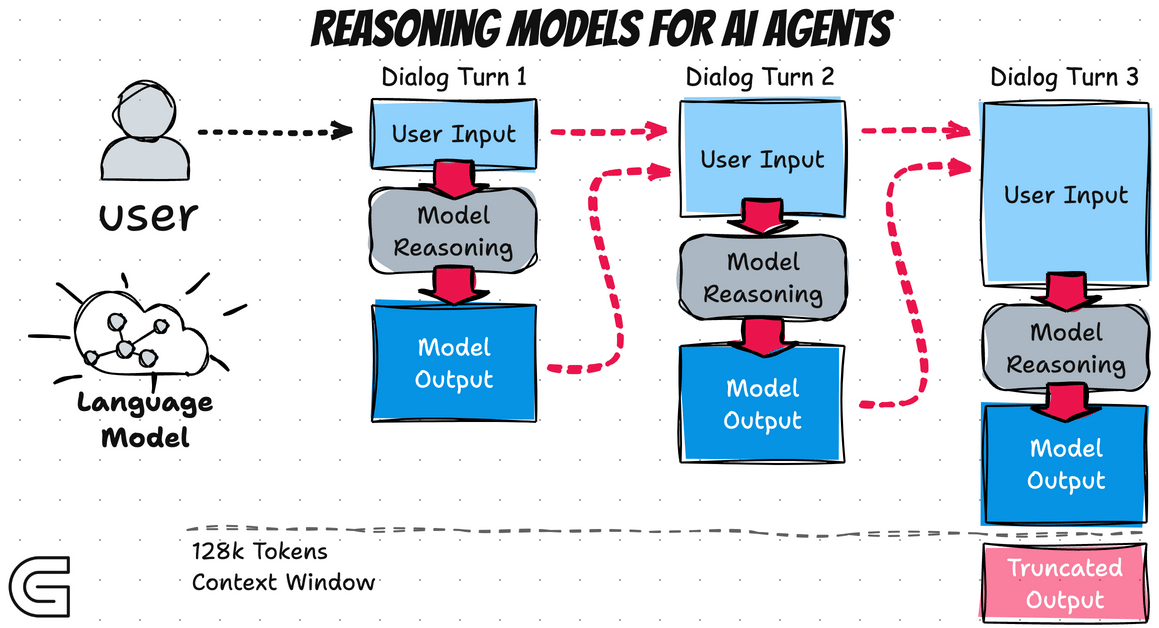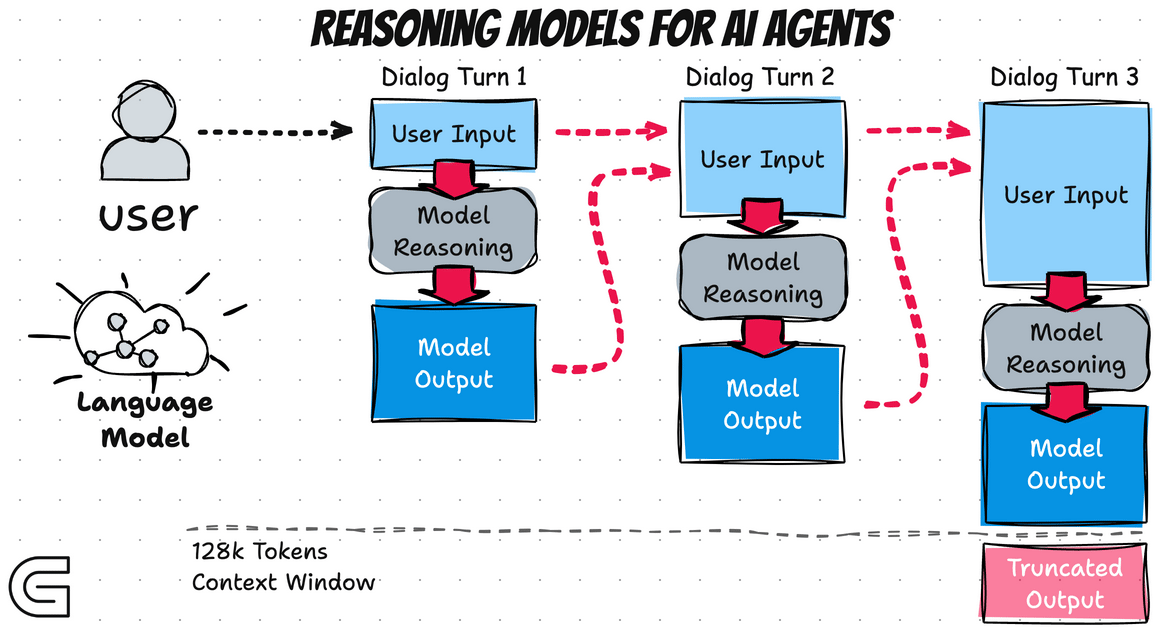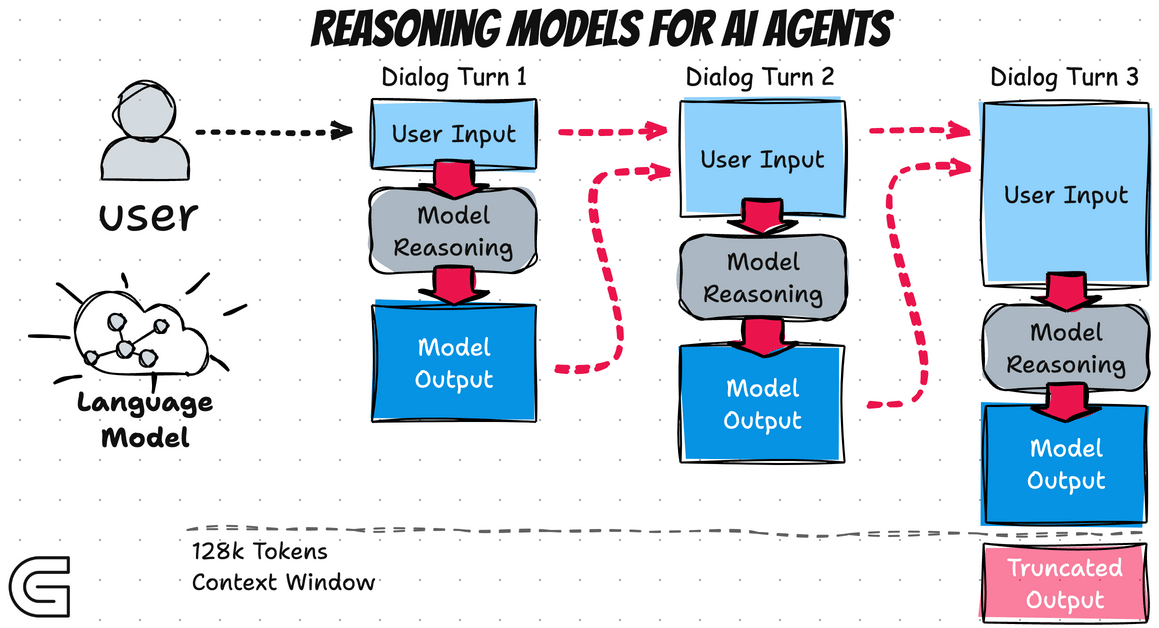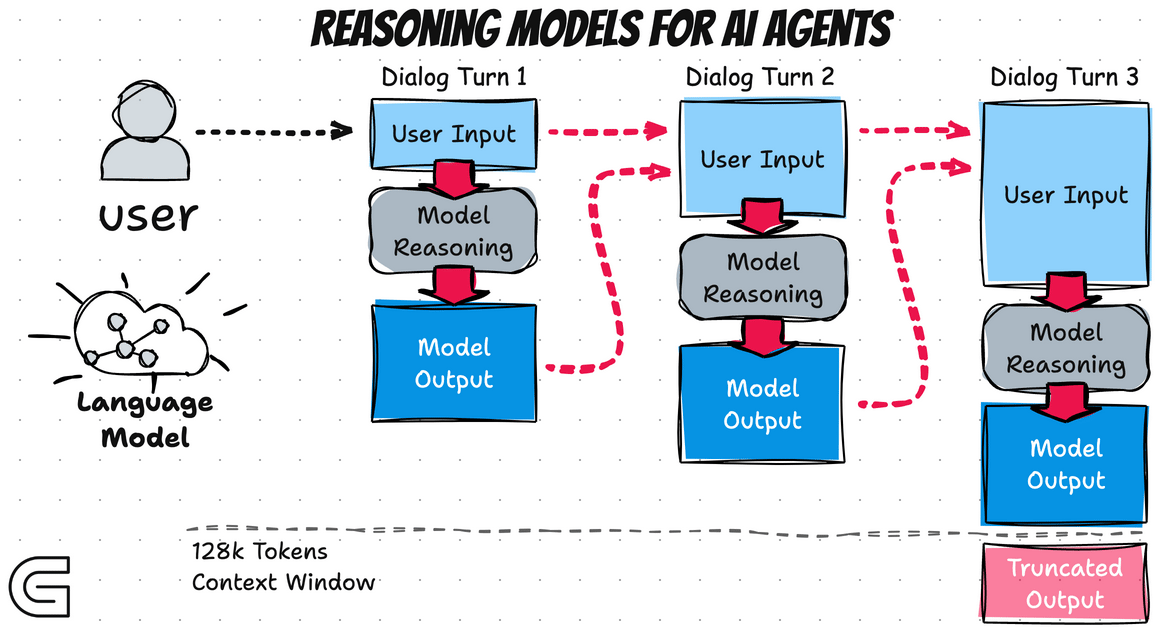
Comparative Benchmark Analysis: Head-to-Head Performance
Humanity's Last Exam: The Primary Differentiator
"Humanity's Last Exam" deserves special attention because it represents the most rigorous benchmark specifically designed to test reasoning models' capabilities. The test comprises 3,000 questions drawn from professional exams, graduate-level courses, and specialized certifications across mathematics, science, computer science, humanities, and engineering.
Critically, these questions are "Google-proof"—they cannot be solved through simple web search or pattern matching against training data. Solving them requires genuine reasoning: applying principles, combining concepts, working through multi-step logical chains.
The results tell a clear story:
| Model | Score | Advantage vs Next | Use Case Implication |
|---|---|---|---|
| Qwen 3-Max-Thinking | 49.8 | +8.7% vs Gemini | Superior on complex agentic reasoning with search |
| Gemini 3 Pro | 45.8 | +0.7% vs GPT-5.2 | Competitive general-purpose reasoning |
| GPT-5.2-Thinking | 45.5 | Baseline | Established performance, well-integrated |
Qwen's advantage on this specific benchmark is notable because the benchmark explicitly includes web search access. This suggests that Qwen's adaptive tool integration and agentic capabilities provide genuine advantages for reasoning tasks that benefit from external information retrieval.
GPQA: Ph.D.-Level Science Questions
GPQA tests whether models can answer graduate-level science questions, many of which don't appear in training data and require combining multiple concepts. On GPQA, Qwen 3-Max-Thinking achieved 92.8%, establishing a clear performance advantage.
For comparison:
- Claude-3.5-Sonnet (non-reasoning): ~80-85%
- GPT-4o (non-reasoning): ~80-85%
- Earlier reasoning models: ~88-91%
- Qwen 3-Max-Thinking: 92.8%
This benchmark is particularly relevant for scientific research applications, where models need to understand domain-specific knowledge and apply it to novel problems.
Live Code Bench: Real-World Coding Challenges
Live Code Bench v 6 evaluates whether models can write working code for real-world problems. This is more challenging than traditional coding benchmarks like Human Eval because it uses problems published after training data cutoffs, ensuring evaluation against genuinely novel challenges.
Qwen 3-Max-Thinking achieved 91.4%—significantly higher than Claude-Opus-4.5 (which scores around 85% on coding benchmarks) and substantially ahead of GPT-4's non-reasoning performance (~90%).
The significance here is that reasoning models make a tangible difference in code generation quality. For teams using AI for real-world development work, the difference between 85% and 91% success rate translates directly to fewer failed code generations, less debugging, and higher productivity.
HMMT Feb 25: Competition Mathematics
HMMT (Harvard-MIT Mathematics Tournament) problems represent some of the most challenging mathematics reasoning tasks. Qwen 3-Max-Thinking achieved 98.0, edging out Gemini 3 Pro's 97.5. For context, non-reasoning models score in the 60-75% range on similar problems.
This benchmark is important for:
- Scientific computing applications
- Financial modeling and quantitative analysis
- Educational AI tutoring systems
- Research data analysis
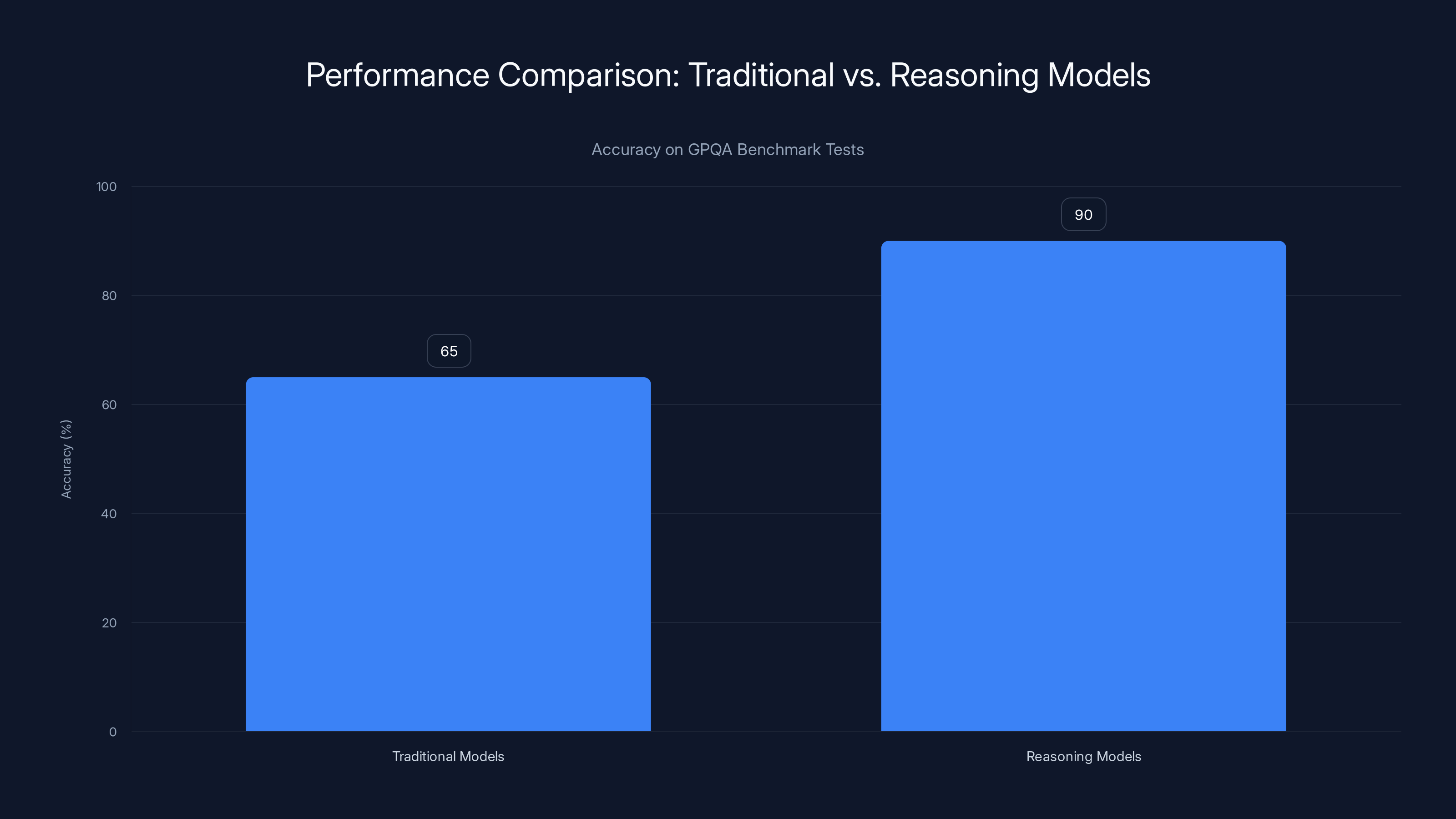
Reasoning models significantly outperform traditional models on GPQA benchmarks, achieving over 90% accuracy compared to 60-70% for traditional models. Estimated data based on typical performance ranges.
Real-World Use Cases and Practical Applications
Scientific Research and Academic Applications
Reasoning models enable AI to function as genuine research assistants for scientific work. A researcher studying quantum mechanics can ask Qwen 3-Max-Thinking to analyze the mathematical implications of a theoretical framework, verify calculations, and identify potential experimental approaches.
The distinction between reasoning and non-reasoning models here is not subtle: a traditional model might provide plausible-sounding but incorrect mathematical derivations; a reasoning model explicitly works through the mathematics and can identify errors in its own reasoning.
Practical workflow:
- Researcher uploads a preprint paper with embedded mathematics
- Model uses web search to find cited papers and context
- Model reads through the mathematical arguments
- Model explicitly works through derivations, checking consistency
- Model identifies potential issues or alternative approaches
- Researcher receives analysis with explicitly-traced reasoning
For academic applications, this transforms AI from a tool for drafting text into a tool for genuine intellectual collaboration.
Enterprise Data Analysis and Reporting
Organizations frequently face complex analytical challenges: understanding why quarterly revenue changed, analyzing why customer churn increased in a particular segment, identifying which cost reduction initiatives would have the highest impact without compromising quality.
These tasks require combining multiple data sources, reasoning through causal relationships, and explicitly working through assumptions. Reasoning models excel here because they can:
- Autonomously identify relevant data sources
- Combine information across databases and systems
- Trace through analytical logic step-by-step
- Identify alternative explanations or hypotheses
- Verify conclusions against assumptions
The practical impact is that knowledge workers can delegate complex analytical projects to AI systems with greater confidence that the analysis is sound.
Software Development and Code Review
Reasoning models provide concrete value for software development in multiple ways:
Code Generation for Complex Algorithms: Writing an algorithm to solve a novel problem (like optimizing inventory allocation across warehouses) requires more than pattern matching against training data. Reasoning models can work through the logical requirements, consider edge cases, and verify that their implementation satisfies constraints.
Code Review and Bug Detection: A reasoning model can examine code and identify not just obvious errors but subtle logical flaws—race conditions, off-by-one errors, incorrect error handling. Because the model explicitly works through code execution, it can catch issues that static analysis tools miss.
Architecture Design: For significant system redesigns or migrations, reasoning models can help evaluate trade-offs: How would moving from monolithic to microservice architecture affect latency, complexity, and operational overhead? A reasoning model can work through these implications.
Medical and Professional Diagnosis Support
In regulated fields like healthcare, reasoning models provide value beyond raw performance: they provide explainability. When a model works through a diagnosis step-by-step, medical professionals can understand and evaluate the reasoning. A model saying "Patient is likely to have condition X" is dangerous; a model saying "Patient presents with symptom A and symptom B; condition X explains both symptoms; laboratory test C would confirm" is clinically useful.
While AI reasoning models cannot and should not replace professional medical judgment, they can dramatically accelerate diagnostic reasoning in clinical decision support systems.
Pricing, Economics, and Cost Analysis
Qwen 3-Max-Thinking Pricing Structure
Alibaba Cloud positions Qwen 3-Max-Thinking as a premium but competitive offering. The pricing model reflects the computational cost of test-time inference: more thinking time costs more.
Estimated pricing (based on Alibaba Cloud's typical structure):
- Input tokens: ~$0.003-0.004 per 1K tokens
- Output tokens: ~$0.012-0.015 per 1K tokens
- Thinking tokens: ~$0.03-0.04 per 1K tokens (higher cost because they consume compute but don't contribute to visible output)
For a typical enterprise use case—analyzing a 5,000-word document and generating a 1,000-word analysis with moderate thinking—the cost might be $0.50-2.00 per request.
Alibaba's strategic pricing emphasizes accessibility compared to historical reasoning model pricing. When OpenAI first introduced reasoning models, pricing was 5-10x standard models. Qwen's pricing, by establishing a more moderate premium, signals intent to drive adoption through competitive economics.
GPT-5.2-Thinking Pricing from OpenAI
OpenAI prices reasoning models significantly higher than standard models:
- Input tokens: ~0.003 for GPT-4o)
- Output tokens: ~0.006 for GPT-4o)
- Reasoning tokens: Premium multiplier applied
This pricing reflects both computational cost and scarcity value—OpenAI has limited production capacity for reasoning models and prices to manage demand.
For the same 5,000-word document analysis mentioned above, GPT-5.2-Thinking might cost $3-8 per request—3-4x the cost of Qwen 3-Max-Thinking.
Gemini 3 Pro Pricing from Google
Google's Gemini 3 Pro pricing is comparable to GPT-5.2-Thinking:
- Input tokens: ~$0.02-0.03 per 1K tokens
- Output tokens: ~$0.08-0.12 per 1K tokens
Google positions somewhat lower pricing than OpenAI, likely as a competitive strategy.
Cost-Benefit Analysis for Different Use Cases
High-volume reasoning tasks (thousands of requests daily): Qwen 3-Max-Thinking offers substantial cost advantages. Cost per request is 60-70% lower than OpenAI or Google, creating potential annual savings of six figures for enterprises.
Mission-critical, low-volume tasks: Where accuracy matters more than cost (1-10 requests daily), the pricing difference becomes less important than performance guarantees and support quality.
Mixed workloads: Organizations handling both routine and critical reasoning tasks might use Qwen 3-Max-Thinking for standard analysis and GPT-5.2-Thinking for the most sensitive decisions, optimizing cost while ensuring top performance where it matters most.
Inference latency sensitivity: If your use case requires sub-5-second response times, traditional models (not reasoning models) remain necessary. If you're building research tools, analytical dashboards, or automated decision-support systems where 10-30 second latency is acceptable, reasoning models add genuine value.
Technical Integration and Developer Experience
API Design and Usability
Qwen 3-Max-Thinking is accessible through Alibaba Cloud's API, with Open API specifications similar to other major AI providers. The primary developer friction point is that Alibaba's documentation is primarily in Chinese, though English translations exist for critical sections.
GPT-5.2-Thinking integrates directly into OpenAI's standard API with consistent patterns familiar to anyone who's used GPT-4 or earlier models. The learning curve is minimal for existing OpenAI users.
Gemini 3 Pro integrates into Google's Vertex AI platform, which emphasizes enterprise features like audit logging, access controls, and model evaluation tools.
Controlling Inference-Time Thinking
A practical consideration when deploying reasoning models is controlling how much thinking the model performs. More thinking improves accuracy but increases latency and cost.
Qwen 3-Max-Thinking:
- Standard mode: moderate thinking, lower latency
- Heavy mode: maximum thinking, higher latency but better accuracy
- Configurable thinking budget: specify max thinking tokens or latency threshold
GPT-5.2-Thinking:
- Budget parameters control thinking depth (conceptually similar to Qwen, though implementation differs)
- Temperature and other parameters still apply to reasoning process
Gemini 3 Pro:
- Similar thinking budget controls
- Emphasizes multimodal reasoning, so thinking applies across all modalities
Error Handling and Robustness
All three models require careful error handling when deployed in production:
-
Timeout management: Reasoning models require longer processing times. Systems must be configured to wait appropriately (15-30 seconds minimum) rather than timing out prematurely.
-
Failure modes: Reasoning models occasionally "think themselves into a corner"—they explore logical pathways that lead nowhere and need to backtrack. Systems should be prepared for occasional latency spikes when this occurs.
-
Token consumption: Thinking tokens are significantly cheaper than output tokens but still add to API costs. Systems should monitor and cap thinking depth if costs become concerning.

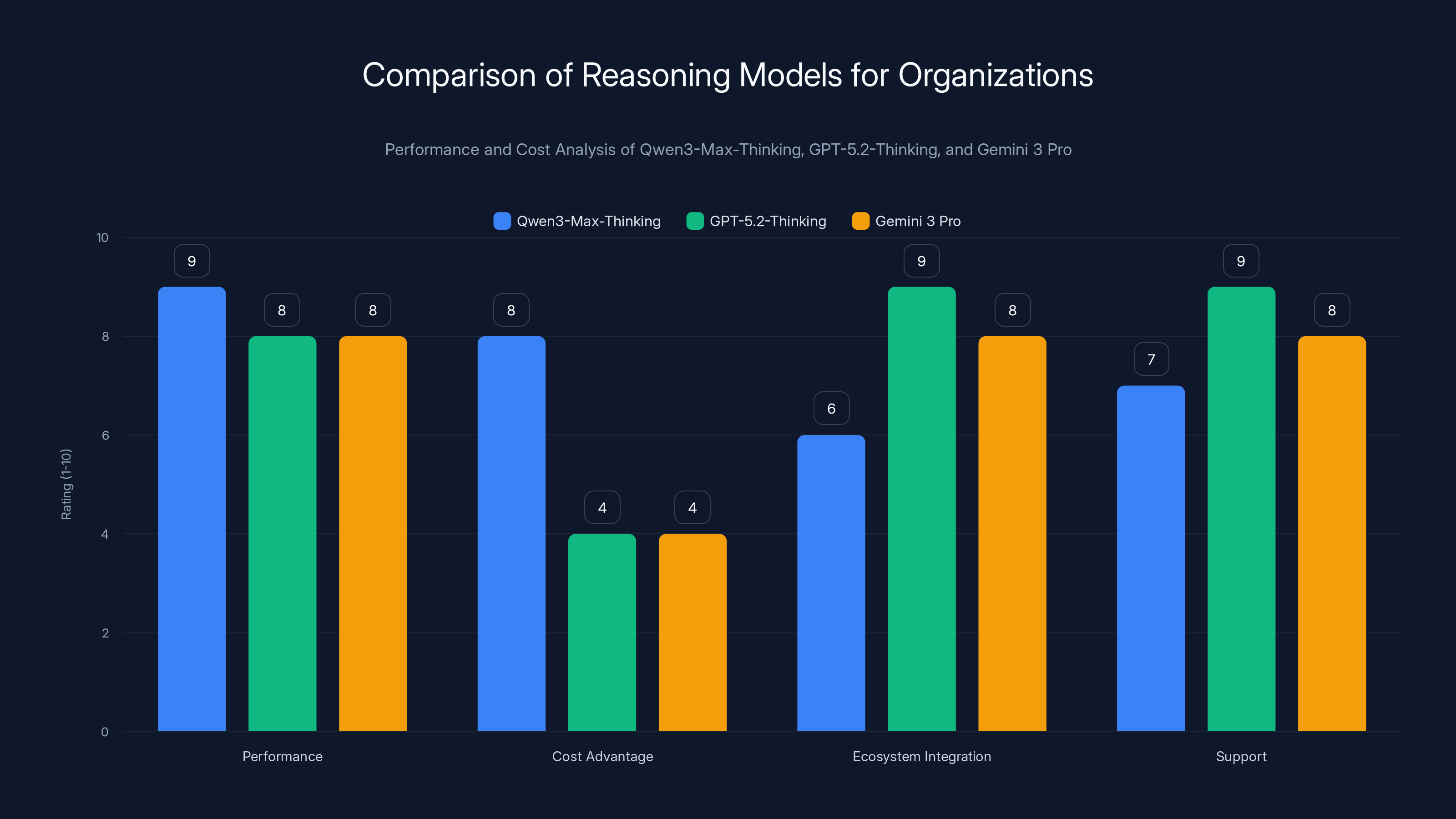
Qwen3-Max-Thinking offers superior performance and cost advantages, while GPT-5.2-Thinking and Gemini 3 Pro excel in ecosystem integration and support. Estimated data based on narrative insights.
Security, Governance, and Responsible AI Considerations
Data Residency and Privacy
A critical consideration for enterprises, especially those handling regulated data:
Qwen 3-Max-Thinking is operated by Alibaba Cloud, a Chinese company. Organizations with strict US data residency requirements or concerns about Chinese government access may face policy constraints. However, for organizations without such constraints, Qwen offers cost advantages without privacy trade-offs.
GPT-5.2-Thinking is operated by OpenAI (US company). Data residency can be controlled through contract terms, though this may involve additional costs.
Gemini 3 Pro is operated by Google (US company). Vertex AI offers data residency controls for Google Cloud regions.
For regulated industries (financial services, healthcare, government), data residency requirements should be the first screening criterion when selecting reasoning models.
Bias and Fairness Implications
Reasoning models amplify whatever biases exist in training data. A model that engages in iterative reasoning might actually entrench biases more deeply because it has more computational capacity to rationalize biased conclusions.
All three models require evaluation across demographic groups to identify disparate performance. The reasoning capabilities don't inherently solve fairness challenges; they create new responsibilities for bias assessment.
Transparency and Explainability
A selling point of reasoning models is explainability: the model's thinking process is theoretically transparent. However, implementation differs:
- Qwen's architecture surfaces more explicit reasoning steps
- OpenAI provides reasoning access but with some opacity
- Google emphasizes end-to-end transparency with multimodal reasoning
For regulated applications requiring audit trails and decision explanations, the ability to access and document the model's reasoning process is valuable.
Comparative Strengths and Weaknesses
Qwen 3-Max-Thinking: Advantages and Limitations
Advantages:
- Superior performance on web-augmented reasoning (49.8 on Humanity's Last Exam vs 45.5-45.8 for competitors)
- Cost efficiency: 60-70% lower pricing than OpenAI/Google
- Adaptive tool integration: Autonomous selection of search, code execution, and memory without explicit prompting
- Experience-cumulative reasoning: More efficient thinking process requiring fewer total iterations
Limitations:
- Vendor concentration risk: Alibaba is the sole provider, with limited redundancy/alternative sources
- Data residency concerns: Chinese company may violate policies for regulated industries
- Documentation accessibility: Primarily Chinese, requiring translation for English-speaking teams
- Regional latency: Infrastructure optimized for Asia may have higher latency for North American or European users
- Less established ecosystem: Fewer integrations with enterprise tools compared to OpenAI or Google
GPT-5.2-Thinking: Advantages and Limitations
Advantages:
- Established ecosystem: Deep integrations with existing tools, libraries, and platforms
- Multimodal capabilities: Native image understanding combined with reasoning
- Proven reliability: Long operational history managing similar workloads
- Strong support: Comprehensive documentation and dedicated support teams
- Trust and adoption: Already used in production by thousands of enterprises
Limitations:
- Higher pricing: 3-4x cost compared to Qwen 3-Max-Thinking
- Lower performance on specific benchmarks: Underperformed Qwen on Humanity's Last Exam (9.2% lower)
- Limited reasoning transparency: Internal reasoning tokens less accessible than Qwen's approach
- Single vendor dependence: OpenAI is sole source, creating supply risk
Gemini 3 Pro: Advantages and Limitations
Advantages:
- Native multimodality: Reasoning across images, text, video simultaneously
- Enterprise integration: Vertex AI provides comprehensive enterprise features
- Competitive pricing: Slightly lower than OpenAI
- Google's infrastructure: Leverages Google Cloud's reliability
Limitations:
- Generalist positioning: No specific benchmark where it dramatically outperforms
- Multimodal complexity: Added complexity if you don't need cross-modal reasoning
- Smaller adoption: Less production deployment than OpenAI, fewer documented use cases
- Google's strategic uncertainty: History of discontinuing AI products creates long-term vendor risk
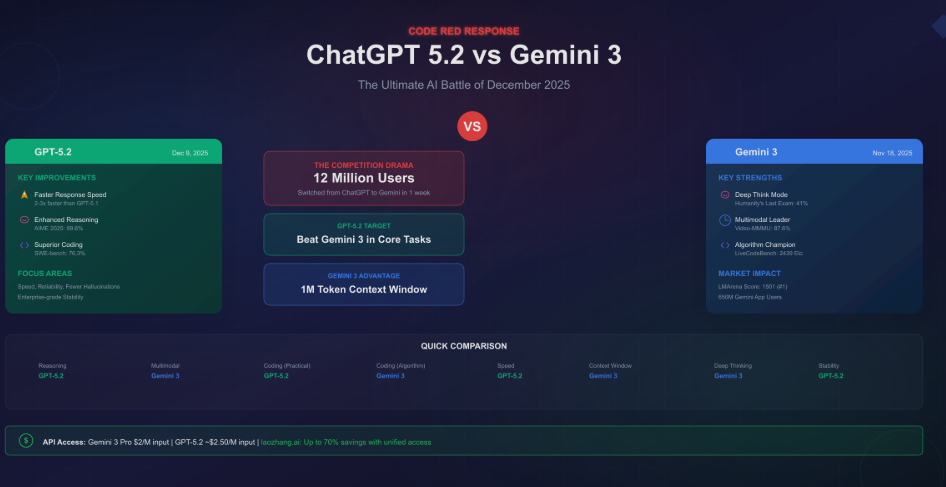
Competitive Landscape and Market Implications
The Fragmentation of AI Model Leadership
For nearly a decade, Western AI labs held a decisive advantage in large language models. The emergence of competitive reasoning models from Alibaba Cloud marks the first significant challenge to this dominance.
This fragmentation has several implications:
First, it creates genuine vendor optionality. Organizations are no longer restricted to choosing between OpenAI, Google, and Anthropic. Competitive pricing and performance from Qwen creates real alternatives.
Second, it accelerates capability democratization. When a single company dominates a capability space, they can charge monopoly prices and limit access. When multiple vendors offer similar capabilities, prices drop and access expands. We're already seeing this with reasoning model pricing moderating as competition increases.
Third, it signals that reasoning models are becoming standard infrastructure rather than novelty capabilities. Similar to how distributed computing, cloud infrastructure, and containerization became standard industry tools, reasoning models are likely heading in this direction.
Future Competitive Dynamics
Several patterns suggest how the competitive landscape will evolve:
1. Capability parity is becoming the baseline. If Qwen achieved comparable or superior reasoning performance to OpenAI/Google, other labs will likely achieve similar parity within 6-12 months. This means competitive differentiation must shift beyond pure benchmarks toward integration, reliability, ecosystem, and pricing.
2. Specialization will increase. Rather than building generalist reasoning models, vendors will develop specialized variants: models optimized for coding, medical reasoning, mathematical reasoning, etc. This mirrors how the GPU market evolved—initially dominated by NVIDIA, but now with competition from AMD and others, differentiation comes through specialized product lines.
3. Inference-time scaling will become commoditized. The architectural innovation driving reasoning models will eventually become standard. The next frontier of differentiation will be efficiency (lower-cost thinking), latency (faster reasoning), and integration (seamless tool use).
4. Open-source reasoning models will emerge. Meta, Mistral, and other open-source AI companies will likely develop open-source reasoning models. These won't match proprietary models initially but will create an alternative for organizations prioritizing control and customization over capability.
The timeline shows the progression from GPT-o1 to GPT-5.2-Thinking, highlighting the evolution of reasoning capabilities in OpenAI's models. Estimated data based on typical release patterns.
Choosing the Right Model: Decision Framework
Decision Matrix for Model Selection
Selecting between Qwen 3-Max-Thinking, GPT-5.2-Thinking, and Gemini 3 Pro requires evaluating multiple dimensions:
Cost sensitivity:
- High cost sensitivity → Qwen 3-Max-Thinking
- Moderate cost sensitivity → Gemini 3 Pro
- Cost insensitive → GPT-5.2-Thinking
Performance requirements:
- Maximum reasoning performance on web-augmented tasks → Qwen 3-Max-Thinking
- Broad reasoning capability → Gemini 3 Pro or GPT-5.2-Thinking
- Specialized domains (coding, math) → Benchmark-specific evaluation
Data governance:
- US data residency required → GPT-5.2-Thinking or Gemini 3 Pro
- Flexible residency → Qwen 3-Max-Thinking
- Highest privacy → Self-hosted open models (future option)
Ecosystem integration:
- Heavy OpenAI dependence → GPT-5.2-Thinking
- Google Cloud investment → Gemini 3 Pro
- New vendor integration → Qwen 3-Max-Thinking
Use case specificity:
- Multimodal reasoning → Gemini 3 Pro
- Web-augmented reasoning → Qwen 3-Max-Thinking
- General-purpose → Any of the three
Implementation Scenarios
Scenario 1: Research Institution with Budget Constraints
- Choice: Qwen 3-Max-Thinking
- Rationale: Superior reasoning performance + lowest cost enables supporting more research projects with same budget
- Implementation: Deploy via Alibaba Cloud API, potentially with on-premises gateway for data sovereignty
Scenario 2: Financial Services Firm with Regulatory Requirements
- Choice: GPT-5.2-Thinking (if US data residency required) or Gemini 3 Pro
- Rationale: US vendor required for compliance, established enterprise support, audit logging
- Implementation: Deploy through VPC endpoint, implement access controls, audit all requests
Scenario 3: Software Development Company Integrating AI into Products
- Choice: GPT-5.2-Thinking or Qwen 3-Max-Thinking depending on customer base
- Rationale: If serving US/regulated customers, GPT-5.2; if serving global market with cost sensitivity, Qwen 3
- Implementation: Build API abstraction layer enabling vendor switching without application changes
Scenario 4: Content Organization with Multimodal Assets
- Choice: Gemini 3 Pro
- Rationale: Native multimodal reasoning handles images, PDFs, videos simultaneously
- Implementation: Deploy through Vertex AI, integrate with existing Google Cloud infrastructure
Emerging Alternatives and Future Directions
Open-Source Reasoning Model Development
While proprietary models currently lead on benchmarks, the open-source community is actively developing reasoning capabilities. Projects like Deep Seek (which achieved 92.5 on HMMT, competitive with other models) demonstrate that open approaches can achieve strong performance.
The trajectory suggests that within 12-18 months, viable open-source reasoning models will exist. Organizations prioritizing control, customization, and avoiding vendor lock-in should monitor these developments.
Inference-Time Scaling Improvements
The current generation of reasoning models allocates thinking compute somewhat inefficiently—models think more than necessary for many problems. Future improvements will likely enable:
- Adaptive thinking budget: Models that determine optimal thinking depth for each problem rather than using fixed budgets
- Hierarchical reasoning: Multi-level reasoning where initial passes identify promising directions, subsequent passes deepen analysis of those directions
- Distributed thinking: Parallel reasoning pathways that explore multiple approaches simultaneously
These innovations could deliver similar reasoning quality at 30-50% lower computational cost.
Specialized Reasoning Models
Benchmark-dominated competition is forcing vendors toward generalist models. Future competition will emphasize specialization:
- Medical reasoning models optimized for diagnostic reasoning in healthcare
- Code reasoning models specialized for software development and debugging
- Financial reasoning models optimized for quantitative analysis and risk assessment
- Scientific reasoning models specialized for research and discovery
Specialized models won't replace general-purpose reasoning models, but they'll provide options for domain-critical applications.
Best Practices for Deploying Reasoning Models
Latency Management and User Experience
Reasoning models introduce latency that users must learn to expect. Best practices for managing this:
-
Set appropriate client timeouts: Configure application timeouts for 30-60 seconds rather than 5-10 seconds used for standard models
-
Implement progressive disclosure: Show users that thinking is in progress ("Analyzing...", "Reasoning through...") rather than silent loading
-
Cache successful results: If the same reasoning task is requested multiple times, cache results rather than re-reasoning
-
Offer async execution: For batch reasoning tasks, implement asynchronous execution rather than blocking on individual requests
-
Measure latency impact: Track how much of total latency comes from thinking vs. final output generation to identify optimization opportunities
Cost Optimization Strategies
Reasoning models' cost structure differs from standard models, requiring different optimization strategies:
-
Thinking budget configuration: Explicitly limit thinking depth based on use case. Medical diagnosis might require maximum thinking; routine FAQ answers might require minimal thinking.
-
Batch processing: Group reasoning tasks together and process in batches rather than individually, improving infrastructure utilization
-
Hybrid approaches: Use standard models for initial triage/filtering, then apply reasoning models only to cases requiring deep analysis
-
Caching and memoization: Cache answers to common reasoning tasks to avoid redundant computation
-
Monitoring and alerting: Track cost per request and implement alerts if costs exceed expected ranges, catching problems early
Monitoring and Reliability
Production reasoning models require sophisticated monitoring:
-
Latency monitoring: Track both thinking time and output generation time separately to identify performance degradation
-
Quality validation: Implement downstream validation of reasoning outputs. Medical recommendations should be validated by specialists; financial analyses should be spot-checked; code outputs should be tested.
-
Cost tracking: Monitor thinking token consumption as a separate metric from output tokens, since they have different cost profiles
-
Fallback strategies: Configure fallback to non-reasoning models if latency becomes unacceptable, ensuring graceful degradation
-
Reasoning transparency: Log reasoning steps where possible to enable debugging and improvement of reasoning quality
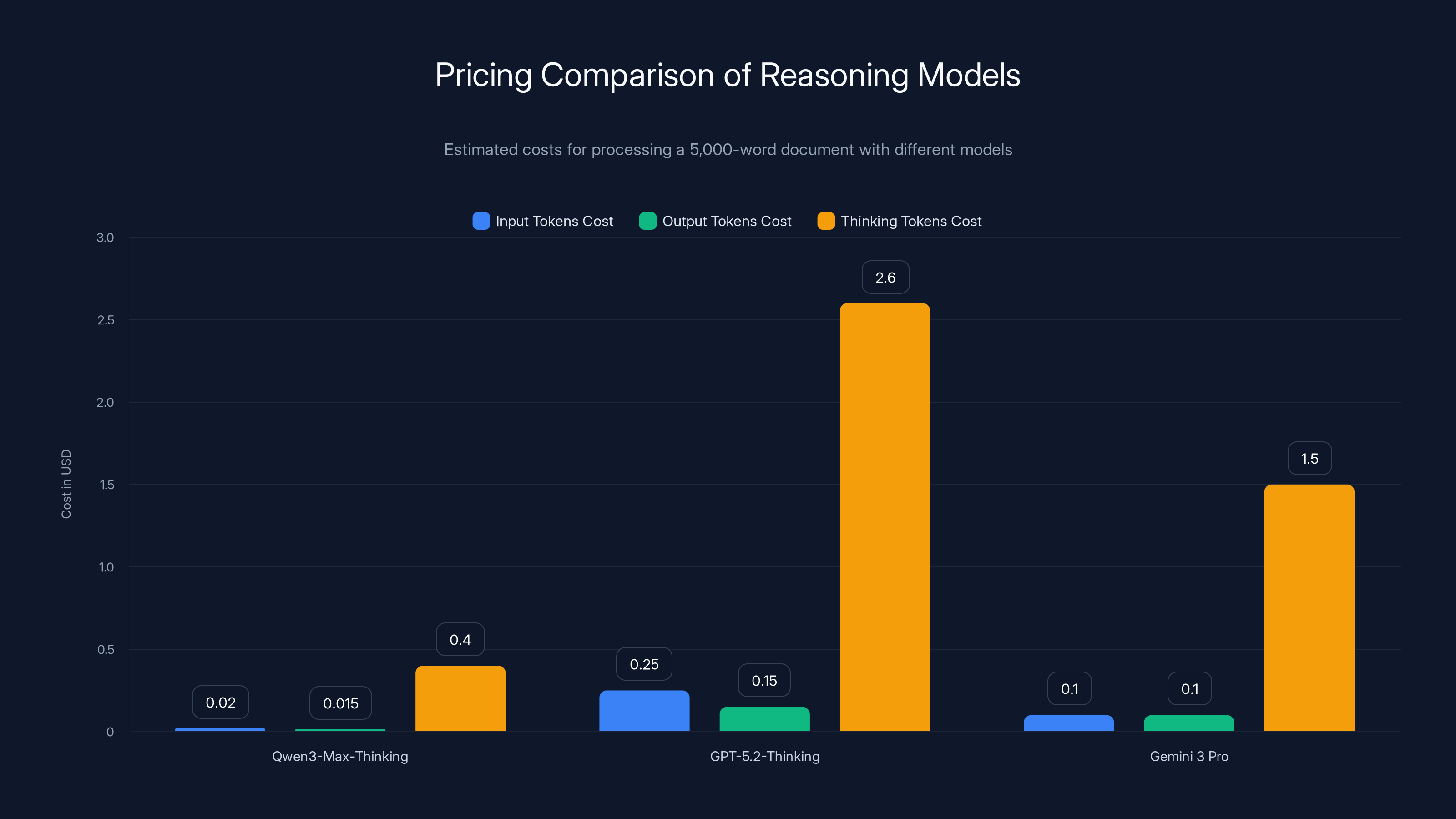
Qwen3-Max-Thinking offers the most cost-effective solution for processing a 5,000-word document, with costs significantly lower than GPT-5.2-Thinking and Gemini 3 Pro. Estimated data based on typical pricing structures.
Industry Expert Perspectives and Research Findings
Academic Research on Reasoning Models
Recent academic work on reasoning models highlights several important findings:
Chain-of-thought reasoning improves accuracy across benchmark tasks. Research from university AI labs confirms that reasoning—whether implemented through explicit chain-of-thought tokens or implicit thinking processes—consistently improves performance on complex tasks by 5-25% depending on task difficulty.
Inference-time scaling has fundamental limits. Computational complexity theory suggests that infinite thinking time cannot solve all problems—some problems remain intractable. The practical implication is that reasoning models will reliably solve problems requiring roughly polynomial-time computation, but NP-hard problems may remain challenging even with unlimited thinking time.
Thinking transparency affects human trust. User studies show that models providing explicit reasoning steps are perceived as more trustworthy and reliable than black-box models achieving identical accuracy. This has important implications for regulated industries where explainability matters.
Enterprise Adoption Patterns
Based on early enterprise deployments:
Early adopters focus on high-value, asynchronous applications. Medical diagnosis support, financial analysis, and research assistance—where accuracy matters more than speed—represent the initial deployment wave.
Cost constraints are shaping hybrid strategies. Rather than replacing all model calls with reasoning models, enterprises are implementing hybrid approaches: standard models for initial triage, reasoning models for complex cases.
Integration complexity is underestimated. Reasoning models introduce architectural complexity (thinking budget management, latency handling, cost monitoring) that early adopters initially underestimated.
Migration Strategies for Existing Deployments
From Standard to Reasoning Models
For teams currently using GPT-4o, Gemini 2, or other non-reasoning models, migration to reasoning models requires planning:
Phase 1: Evaluation (1-2 weeks)
- Identify use cases where reasoning provides value (complex analysis, high-accuracy requirements)
- Evaluate each reasoning model on your specific use cases (don't rely solely on public benchmarks)
- Establish cost baseline and project reasoning model costs
Phase 2: Pilot (2-4 weeks)
- Select 1-2 high-impact use cases for pilot deployment
- Implement alongside existing solution, comparing results
- Gather user feedback on latency, quality, and cost trade-offs
Phase 3: Gradual rollout (1-3 months)
- Expand reasoning model deployment to additional use cases
- Implement monitoring and cost controls
- Maintain fallback to standard models during transition
Phase 4: Optimization (ongoing)
- Refine thinking budget configuration based on actual usage
- Implement caching and other cost optimization strategies
- Monitor for opportunities to add reasoning to new use cases
Managing Multiple Models
For organizations using multiple reasoning models (e.g., Qwen for cost-sensitive applications, OpenAI for mission-critical ones):
-
Implement abstraction layer: Build API wrapper that routes requests to appropriate model based on configured rules
-
Standardize monitoring: Use unified logging and metrics across models, enabling fair performance comparison
-
Version control configurations: Track thinking budget, timeout, and other settings for each model to enable reproducibility
-
Regular benchmarking: Periodically evaluate all models on your actual use cases (not just public benchmarks) to detect performance changes
Alternative Tools and Complementary Solutions
When Reasoning Models Aren't the Answer
While reasoning models offer impressive capabilities, they're not the right solution for all problems:
Real-time applications (trading systems, live customer service) may find 10-30 second latency unacceptable. Standard models remain necessary for these use cases.
High-frequency API calls (thousands per second) may exceed cost budgets. Standard models or open-source alternatives provide more cost-effective solutions.
Simple retrieval tasks (answering factual questions with web search) don't benefit from reasoning capabilities. Web search + summarization tools are more efficient.
Complementary Tools
Reasoning models work best as part of broader AI systems:
Vector databases and semantic search enable reasoning models to access relevant context efficiently, improving reasoning quality.
Code execution environments let reasoning models verify their logic through actual computation rather than theoretical reasoning.
Specialized extractors for structured data (entity extraction, relationship mapping) can preprocess information for reasoning models.
Chain-of-thought prompting works with standard models and can achieve 70-80% of reasoning model performance on some tasks at significantly lower cost.
Looking Ahead: The 2025-2026 Outlook
Market Trends
Commoditization of reasoning capabilities: Reasoning will shift from premium feature to standard offering. By late 2025, most major AI providers will offer reasoning models at competitive pricing.
Vendor consolidation risk: The high R&D cost of maintaining competitive reasoning models may consolidate the market. Expect 2-3 major providers to dominate by end of 2026.
Specialist vendors emerging: Real value creation will shift toward specialized models for specific domains, vertically-integrated solutions for particular industries, and open-source alternatives for cost-sensitive applications.
Capability Expectations
Reasoning speed improvement: Expect 2-3x latency reduction through architectural efficiency improvements, making reasoning models viable for more applications.
Cost reduction: As reasoning models commoditize and infrastructure optimizes, expect 50% cost reduction over 2 years.
Reasoning transparency: Better tools for understanding model reasoning will emerge, improving explainability and trust.
Specialization: Reasoning models optimized for specific domains (medical, financial, legal) will emerge alongside generalist models.
Conclusion: Making the Right Choice for Your Organization
The emergence of Qwen 3-Max-Thinking as a competitive reasoning model marks a significant inflection point in AI infrastructure. For the first time, organizations have genuine choice in reasoning model providers, with meaningfully different trade-offs in performance, cost, ecosystem, and governance.
Qwen 3-Max-Thinking delivers superior performance on web-augmented reasoning tasks while offering 60-70% cost advantages over OpenAI and Google. For organizations where cost matters and data residency isn't constrained, Qwen 3-Max-Thinking represents compelling value.
GPT-5.2-Thinking and Gemini 3 Pro remain strong choices for organizations already invested in those ecosystems, with strong ecosystem integration, proven reliability, and comprehensive support. The higher cost is justified if you prioritize vendor ecosystem, regulatory requirements, or specialized capabilities.
The broader message is clear: reasoning models are rapidly becoming standard AI infrastructure. Organizations need to evaluate which reasoning models align with their specific use cases, technical requirements, and business constraints. The decision isn't about choosing the "best" model universally—it's about choosing the model that best serves your specific context.
For teams currently evaluating reasoning models:
-
Identify your specific use cases where reasoning provides genuine value (typically complex analysis, high-accuracy requirements, multi-step problems)
-
Benchmark models on your actual problems, not just public benchmarks. Real-world performance may differ from academic benchmarks.
-
Calculate true cost of ownership, including latency impacts, integration complexity, and ecosystem costs, not just API pricing.
-
Plan for migration, starting with low-risk pilots before broader deployment.
-
Monitor competitive developments—the landscape is rapidly evolving, with new models and capabilities emerging continuously.
The most important takeaway: reasoning models are no longer novelty features—they're becoming essential infrastructure. Organizations serious about AI adoption in 2025 must understand reasoning model capabilities, trade-offs, and implementation requirements. Qwen 3-Max-Thinking's emergence signals that this infrastructure is becoming competitive and accessible, not just available to organizations with unlimited budgets.
The choice between models ultimately depends on your specific context. But having genuine choice—a competitive market rather than a vendor-dominated monopoly—is unambiguously positive for organizations building AI-powered systems.
FAQ
What is a reasoning model and how does it differ from standard language models?
Reasoning models allocate additional computational resources during inference (when users query the model) to "think through" complex problems step-by-step, similar to how humans work through challenging problems. Standard language models generate output token-by-token without this reflective process. The practical difference is substantial: on graduate-level science questions (GPQA), standard models achieve ~80-85% accuracy while reasoning models achieve 92-95% accuracy. Reasoning models trade faster response times for improved accuracy, typically requiring 10-30 seconds instead of 1-2 seconds for similar problems.
How does Qwen 3-Max-Thinking's "experience-cumulative" approach differ from other reasoning architectures?
Qwen 3-Max-Thinking uses an iterative refinement strategy where each reasoning round learns insights from previous rounds, rather than independently generating multiple solutions and selecting the best one. This means the model becomes progressively more intelligent about a problem as it reasons, identifying and avoiding dead-end reasoning paths early. This approach improves efficiency—achieving strong performance with fewer total thinking iterations—compared to simpler methods that reduplicate reasoning effort across multiple attempts.
What does the "Humanity's Last Exam" benchmark measure and why is it significant?
Humanity's Last Exam (HLE) comprises 3,000 "Google-proof" questions from professional exams, graduate courses, and specialized certifications across mathematics, science, engineering, humanities, and computer science. These questions cannot be solved through simple web search or pattern matching—they require genuine reasoning and concept application. It's significant because Qwen 3-Max-Thinking achieved 49.8 on HLE with web search (vs Gemini 3 Pro's 45.8 and GPT-5.2's 45.5), demonstrating genuine reasoning superiority, not just benchmark gaming.
What are the main cost differences between Qwen 3-Max-Thinking, GPT-5.2-Thinking, and Gemini 3 Pro?
Qwen 3-Max-Thinking costs approximately
Should I migrate my existing applications to reasoning models?
Migration makes sense if your use cases involve complex analysis, accuracy requirements exceeding what standard models provide, or problem-solving tasks requiring multiple reasoning steps. Applications like scientific research support, financial analysis, code review, and diagnostic assistance benefit substantially from reasoning. However, simple retrieval tasks, content generation, and real-time applications with strict latency requirements (< 5 seconds) are better served by standard models. A hybrid approach—using standard models for initial triage and reasoning models only for complex cases—often provides optimal cost-performance.
How do I choose between Qwen 3-Max-Thinking and OpenAI's GPT-5.2-Thinking?
Choose Qwen 3-Max-Thinking if cost efficiency and superior performance on web-augmented reasoning tasks are priorities, and if you have flexibility on data residency (Alibaba is Chinese company). Choose GPT-5.2-Thinking if you have US data residency requirements, need enterprise support, or are deeply integrated into OpenAI's ecosystem. For most organizations, the decision hinges on: (1) data governance requirements, (2) cost sensitivity, and (3) existing infrastructure investments. For new deployments without vendor lock-in, Qwen's cost advantages often justify the vendor switching.
What latency should I expect from reasoning models?
Expect 10-30 seconds for standard reasoning depth, with the time breakdown roughly: 70% spent in thinking/reasoning, 30% in final output generation. This varies by problem complexity and thinking budget configuration. Simple problems might complete in 5-8 seconds; complex problems might require 30-45 seconds. This latency is acceptable for asynchronous applications (research, analysis, medical decision support) but problematic for real-time applications (customer service, live trading). Configure client timeouts for 30-60 seconds rather than typical 5-10 second settings.
How do reasoning models handle hallucinations and factual accuracy?
Reasoning models improve accuracy through explicit verification: they can cross-check calculations, verify logical consistency, and use web search to ground reasoning in verifiable facts rather than relying solely on training data. On GPQA (graduate-level science questions), reasoning models achieve 92%+ accuracy compared to 80% for standard models, partly because they explicitly verify reasoning steps. However, they don't completely eliminate hallucinations—they reduce them through verification. For applications requiring highest accuracy, implement additional downstream validation of model outputs.
Can reasoning models replace human experts in specialized domains like medicine or law?
No. Reasoning models are expert-support tools, not expert replacements. In medicine, they can assist diagnostic reasoning by analyzing symptoms and suggesting conditions to consider, but diagnosis and treatment decisions require human physicians. In law, they can analyze case law and legal reasoning but cannot replace lawyers' judgment and professional responsibility. The value proposition is dramatically reducing the time experts spend on reasoning-intensive research work, not eliminating the need for expert judgment. Always maintain human oversight, especially in regulated industries.
What's the expected trajectory of reasoning model capabilities and pricing over 2025-2026?
Expect reasoning model capabilities to commoditize—becoming standard offerings across major AI platforms rather than premium features. Pricing will likely decline 30-50% as competitive pressure increases and vendors optimize infrastructure efficiency. Latency will improve 2-3x through architectural innovations. Specialization will increase, with reasoning models optimized for specific domains (medical, financial, legal) emerging alongside generalist models. Open-source reasoning models will achieve viability, creating alternatives for cost-sensitive or privacy-conscious organizations. By 2026, reasoning models should be as ubiquitous as GPT-4 is today.
Are there open-source alternatives to proprietary reasoning models?
As of early 2025, open-source reasoning models are emerging but don't yet match proprietary model performance. Deep Seek has released competitive models (achieving 92.5 on HMMT mathematics), and Meta, Mistral, and other organizations are researching reasoning capabilities. For current production deployments, proprietary models (Qwen, OpenAI, Google) remain superior. However, organizations prioritizing control, customization, and avoiding vendor lock-in should monitor open-source developments. Within 12-18 months, production-viable open-source alternatives likely will exist, creating a third option alongside proprietary models.

Integrating Reasoning Models into Your Workflow: Practical Implementation
For teams evaluating reasoning models for practical deployment, understanding how to integrate them into existing workflows is essential. Rather than treating reasoning models as drop-in replacements for standard models, successful implementations view them as specialized tools for specific high-value problems.
A practical implementation pattern involves developing what we might call a "reasoning pipeline": incoming requests are initially assessed for complexity and accuracy requirements. Simple queries that can be answered directly route to fast, cost-effective standard models. Complex queries requiring deep analysis route to reasoning models, but only after initial triage confirms that reasoning is necessary.
This hybrid approach typically delivers 80-90% of reasoning model quality (for the problems that actually benefit from reasoning) at 30-40% of the cost of using reasoning models universally. Implementation requires thoughtful API abstraction layers that hide model selection from application code, enabling shifts in routing logic without application changes.
Beyond Benchmarks: Real-World Reasoning Model Performance
Public benchmarks, while valuable, don't always correlate perfectly with real-world performance. Qwen 3-Max-Thinking might achieve 92.8% on GPQA but perform differently on your organization's specific scientific questions. GPT-5.2-Thinking might excel at reasoning problems involving text but perform worse on problems involving numbers and calculations.
Successful organizations implementing reasoning models follow a pattern of "benchmark evaluation, then real-world validation." They start by running models against public benchmarks to get directional guidance, then implement small-scale pilots on actual use cases to measure real-world performance. Only after confirming that reasoning models provide genuine value on their actual problems do they commit to broader deployment.
This validation process typically reveals that reasoning models provide different performance profiles than benchmarks suggest. Sometimes they exceed expectations; sometimes they underperform on specific problems. Learning these real-world performance characteristics before committing to large-scale deployment prevents costly mistakes.

Key Takeaways
- Qwen3-Max-Thinking achieves 49.8 on Humanity's Last Exam, surpassing Gemini 3 Pro (45.8) and GPT-5.2-Thinking (45.5) by 8-9%
- Qwen's experience-cumulative reasoning architecture learns from previous iterations, enabling more efficient problem-solving than competing approaches
- Pricing is 60-70% lower for Qwen3-Max-Thinking compared to OpenAI and Google, creating major cost advantages for high-volume reasoning applications
- Reasoning models trade latency for accuracy: expect 10-30 second response times for superior performance on complex analysis tasks
- Model selection depends on balancing cost sensitivity, performance requirements, data governance constraints, and existing ecosystem investments
- Hybrid deployment strategies—using standard models for simple queries and reasoning models for complex problems—optimize cost-performance trade-offs
- Competitive reasoning models are rapidly commoditizing; by 2026 expect 50% cost reductions and 2-3x latency improvements
Related Articles
- From AI Hype to Real ROI: Enterprise Implementation Guide [2025]
- AI Failover Systems: Enterprise Reliability in 2025 [Guide]
- Google Gemini vs OpenAI: Who's Winning the AI Race in 2025?
- AI Gross Margins & Compute Costs: The Real Math Behind 70% Margins
- Nvidia's $2B CoreWeave Investment: AI Infrastructure Strategy Explained
- Intent-First Architecture: Why Conversational AI Fails [2025]

