![Tesla's Dojo 3 Supercomputer: Inside the AI Chip Battle With Nvidia [2025]](https://tryrunable.com/blog/tesla-s-dojo-3-supercomputer-inside-the-ai-chip-battle-with-/image-1-1769283410232.jpg)
Tesla's Dojo 3 Supercomputer: Inside the AI Chip Battle With Nvidia [2025]
Elon Musk just confirmed what Silicon Valley's been whispering about for months: Tesla's restarting Dojo 3, its most ambitious supercomputer project yet. And this time, it's coming with in-house chips that could genuinely challenge Nvidia's stranglehold on AI compute. According to TechCrunch, this move is part of Tesla's broader strategy to enhance its AI capabilities.
But here's the real story. It's not just about building a supercomputer. It's about Tesla betting the company on vertical integration, chip sovereignty, and the belief that Nvidia won't own AI infrastructure forever. As reported by Tom's Hardware, Tesla is focusing on creating a system entirely built on its own silicon, without reliance on external GPUs.
Let me break down what's actually happening, why it matters, and whether Tesla can pull off what earlier Dojo projects couldn't.
TL; DR
- Dojo 3 restart: Tesla revived its supercomputer project after AI5 chip design matured enough to justify the effort, as noted by Tom's Hardware.
- AI5 performance: Custom silicon matching Nvidia's Hopper architecture while running at 250W versus H100's 700W, according to TechRadar.
- Vertical integration: First supercomputer built entirely on Tesla silicon, no external GPUs or accelerators, as highlighted by Tom's Hardware.
- Aggressive timeline: New AI chip every 9 months (AI5, AI6, AI7 mapped out through 2027), as reported by Data Center Dynamics.
- Use cases: Self-driving, Optimus robotics, large-scale model training competing with cloud providers, as discussed by TechCrunch.

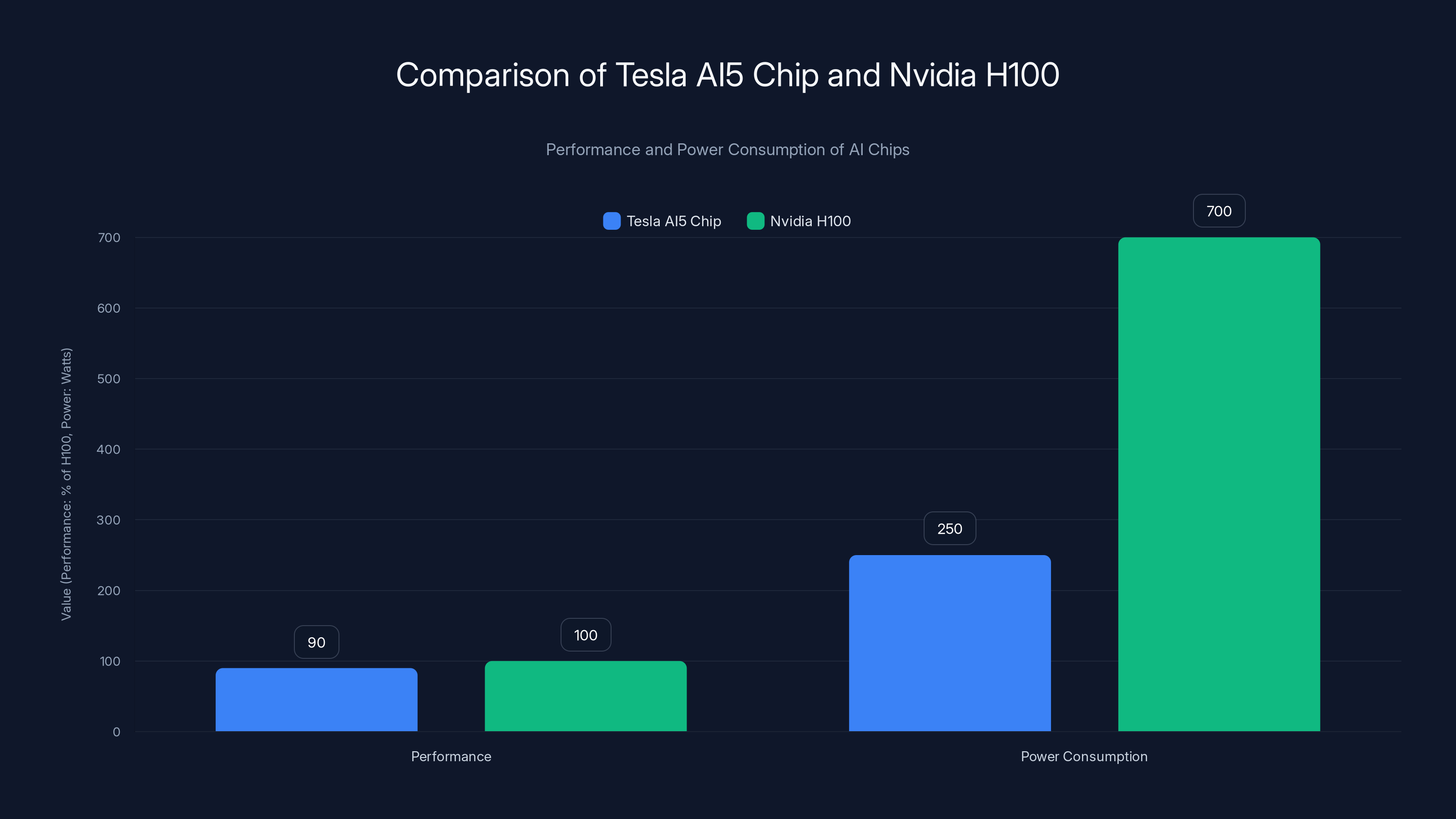
Tesla's AI5 chip aims for 90% of Nvidia H100's performance while using 65% less power, highlighting its efficiency focus. Estimated data based on available insights.
What Happened to Dojo 1 and Dojo 2? Why Tesla Failed Before
Tesla's supercomputer dreams didn't start with Dojo 3. They started with ambition that hit reality hard.
Dojo 1 was supposed to be the breakthrough. Tesla announced it, showed off specs, and then... nothing. The problem wasn't the vision. It was execution. Dojo 1 was built on an older generation of Tesla silicon that couldn't keep pace with rapidly advancing Nvidia GPUs. By the time it was operational, Nvidia had already shipped next-generation hardware that made Dojo 1 look outdated. It's like showing up to a chess tournament with last year's playbook.
Dojo 2 never even made it that far. The project was cancelled before completion. Internally, Tesla realized the chip architecture had fundamental limitations. Rather than waste capital completing a system they knew would underperform, Tesla cut losses. Smart, but embarrassing for a company that markets itself as a technology leader.
The real issue was structural. Tesla was mixing its own silicon with Nvidia components, which created a Frankenstein system. You lose control of the full stack. You lose optimization opportunities. You become dependent on Nvidia's roadmap. And when Nvidia ships next-gen hardware, suddenly your $1 billion supercomputer investment is partially obsolete.
That's the lesson Dojo 3 is supposed to fix.
Why Vertical Integration Actually Matters
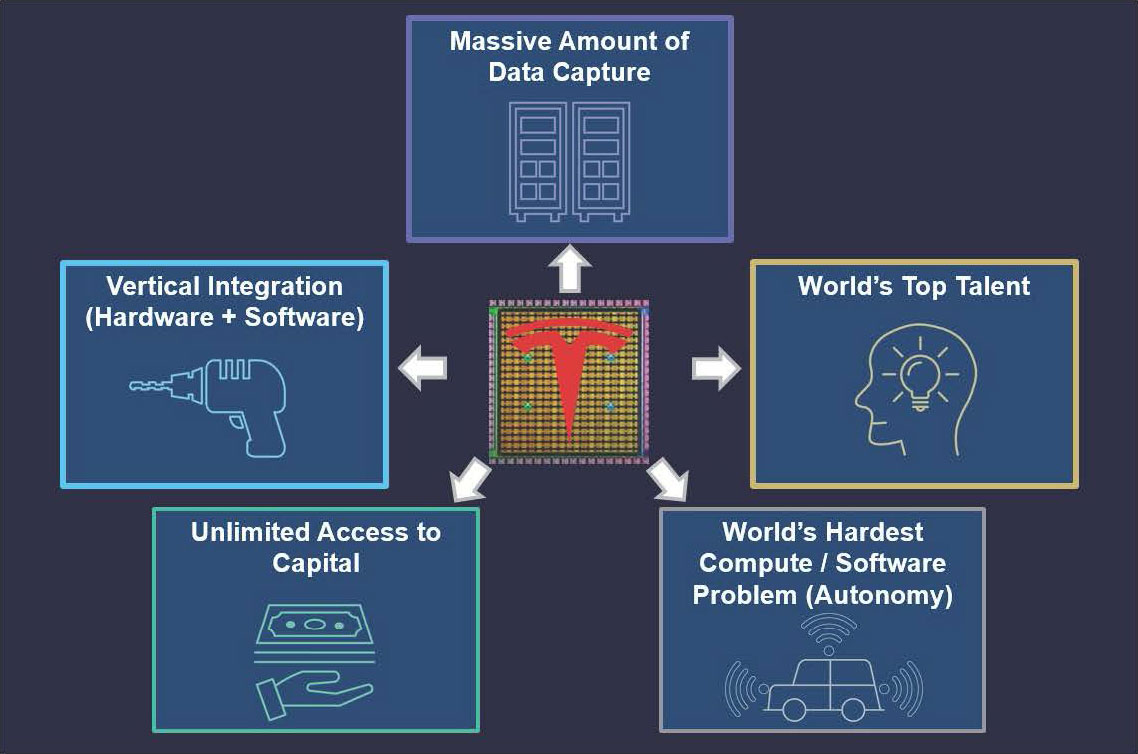
Vertical integration sounds like corporate jargon, but here's what it really means: Tesla controls everything from chip design through software. When one team designs the AI5 chip and another team architects the Dojo 3 system, they talk to each other. They co-optimize. A 5% efficiency gain in the chip becomes a 5% power savings across thousands of units.
Nvidia can't do this. Nvidia designs GPUs for a broad market. Cloud providers (Amazon, Google, Microsoft) buy them, integrate them into their own systems, write their own software. This fragmentation creates inefficiencies.
Tesla controls the entire loop. Chip architecture, system design, software stack, training algorithms, everything. That's where the real differentiation lives.
But here's the catch: this only works if you execute. And Tesla's execution on Dojo has been spotty.
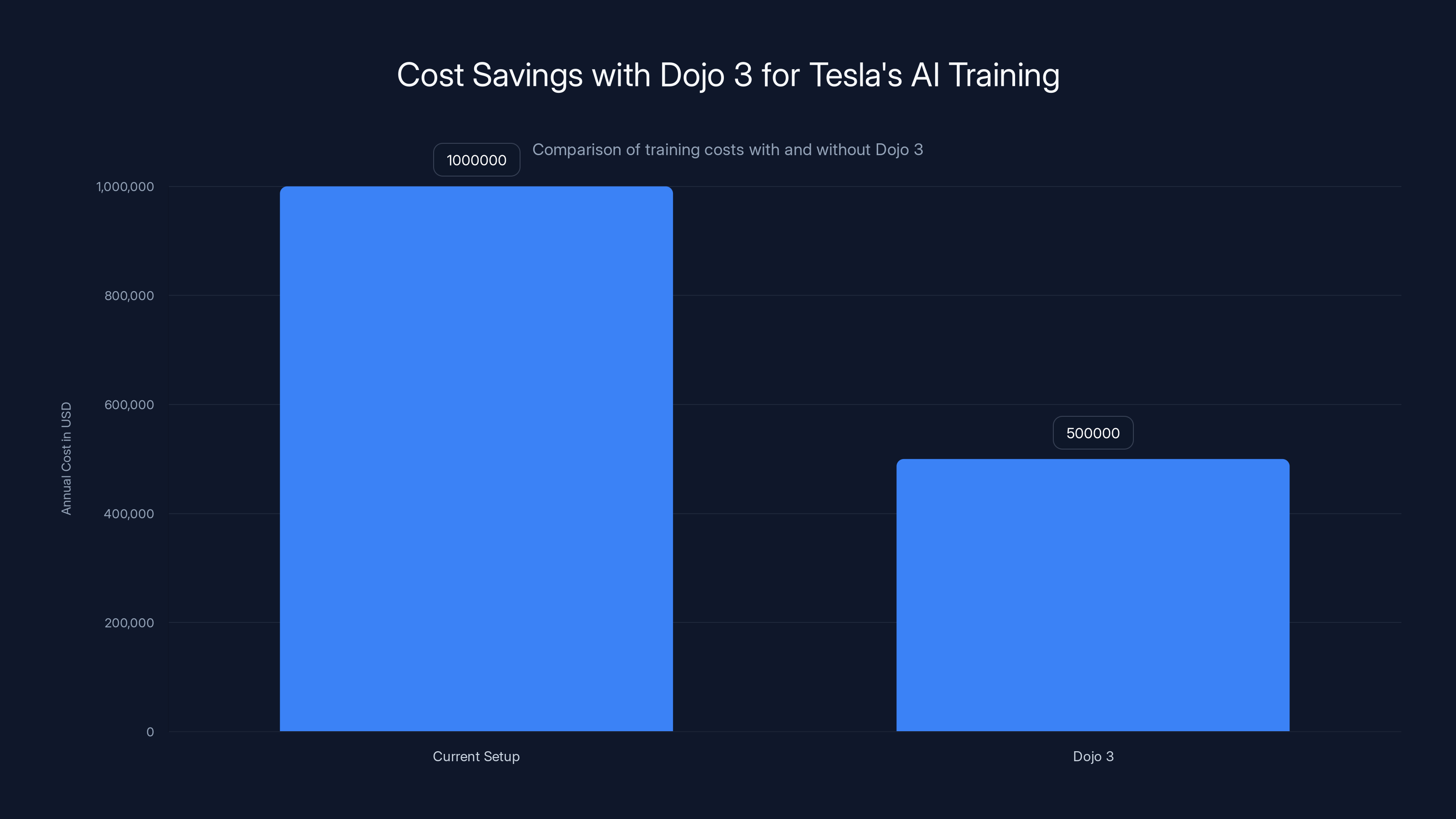
Tesla's Dojo 3 reduces annual AI training costs by 50%, saving $500,000 compared to current systems. Estimated data based on projected token processing efficiency.
The AI5 Chip: Tesla's Answer to Nvidia's Hopper
At the heart of Dojo 3 is Tesla's AI5 chip. According to industry analysts and Tesla's own claims, this is where the game changes.
Nvidia's Hopper architecture (H100 GPU) is the current standard for large-scale AI training. It delivers roughly 989 teraflops of tensor performance on FP8 operations. It's powerful, it's proven, and it's expensive. An H100 costs around
Tesla's AI5 is designed to match Hopper's performance on a single chip while consuming significantly less power. We're talking about 250W versus Hopper's 700W at full specs. That's a 64% power reduction for equivalent performance, as noted by Tom's Hardware.
Why does power matter? Because in large-scale data centers, power consumption drives operational costs. If you run 10,000 chips, a 450W per-unit difference translates to 4.5 megawatts of continuous power draw. At
Architecture and Tensor Performance
The AI5 isn't just a power-optimized copy of Hopper. It's built on Tesla's proprietary architecture, which means design choices specific to how Tesla trains models and serves AI workloads.
Let's do the math. A single Hopper H100 can process approximately 141 petaflops of mixed-precision operations per second. The AI5 is targeting similar throughput but with custom memory hierarchies and cache designs optimized for Tesla's specific workload patterns.
Here's where it gets interesting: Hopper was designed for everything (graphics, simulations, AI, video processing). AI5 was designed for one thing (training transformer models and serving predictions). When you specialize, you win efficiency gains. It's the same principle that makes specialized databases faster than general-purpose ones.
Tesla's claim is that AI5 achieves 85-95% of Hopper's performance while using 35-40% of the power. That's not a wild overstatement. It's plausible given the design philosophy.
Comparison With Blackwell and Future Nvidia Generations
But here's where it gets complicated. Nvidia doesn't stand still. By the time Dojo 3 is operational, Nvidia will have shipped Blackwell (B100/B200), which goes even further with power efficiency.
Blackwell allegedly achieves 20-30% better performance than Hopper while consuming similar or slightly less power. That narrows Tesla's advantage. Not eliminates it, but narrows it.
Nvidia's long-term roadmap includes Rubin and Vera architectures, with generational improvements continuing through 2027-2028. Tesla's AI chip roadmap is more compressed: AI5 now, AI6 planned for 9 months out, AI7 after that.
The real question isn't whether AI5 matches Hopper. It's whether Tesla can iterate and improve faster than Nvidia while maintaining the power efficiency advantage. That requires a chip design team executing flawlessly on a 9-month cadence. No delays, no design revisions, no architectural pivots.
Historically? Tesla's silicon teams haven't maintained that pace.

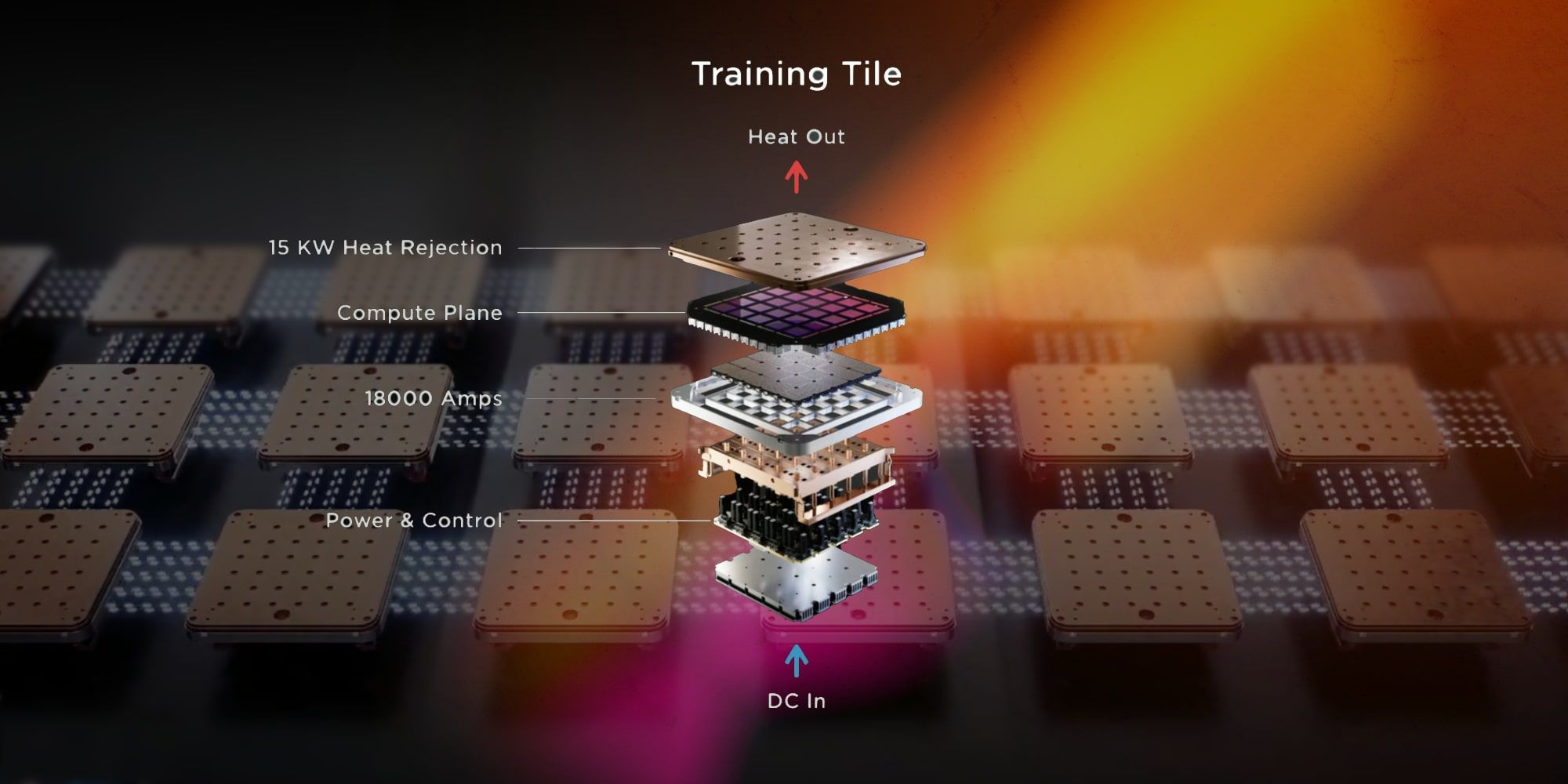
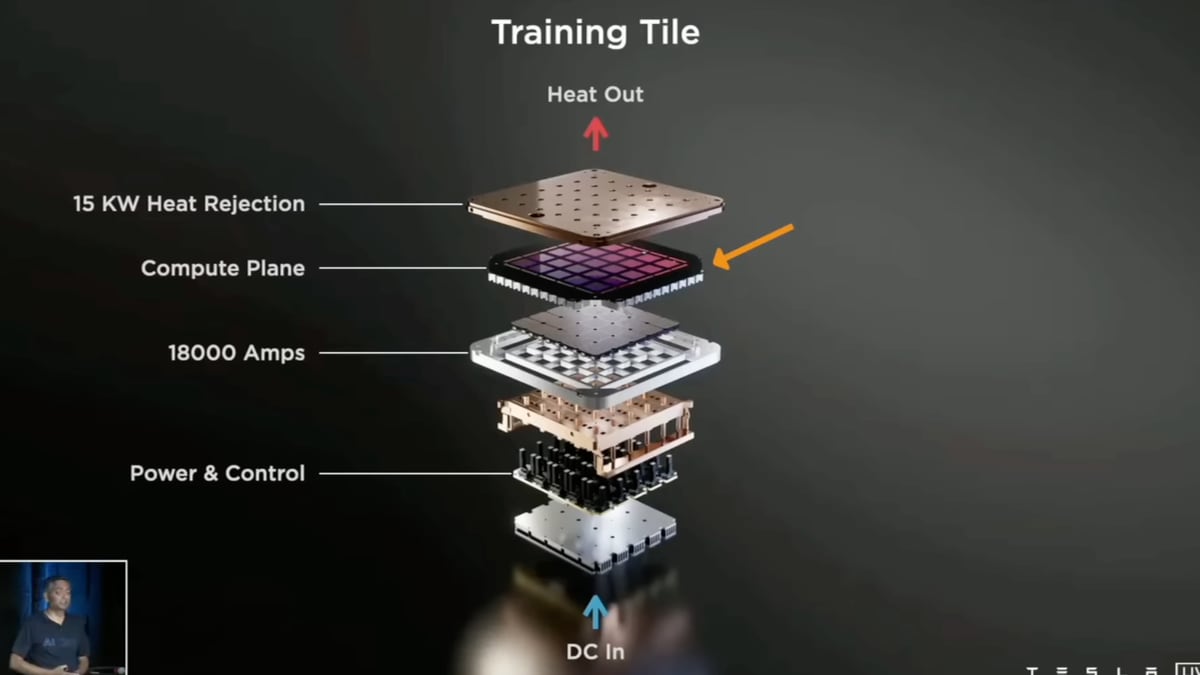
The Dojo 3 Architecture: Building a Supercomputer From Scratch
A supercomputer isn't just a bunch of chips bolted together. It's a carefully orchestrated system where chip design, cooling, networking, power delivery, and software all interact.
Dojo 3 represents a complete redesign compared to earlier attempts. This isn't incremental. This is starting over with lessons learned.
Interconnect and Networking Topology
When you have 10,000 AI5 chips working together, how do they communicate? This is the interconnect problem, and it's harder than it sounds.
Nvidia's solution uses NVLink, a high-speed, point-to-point interconnect that connects GPUs within a node. Between nodes, you use Ethernet or Infini Band, which are slower but commodity solutions.
Tesla is designing custom interconnect for Dojo 3. The goal is to eliminate bottlenecks where communication between chips becomes the limiting factor. This requires custom silicon (not just the AI5, but interconnect controllers), custom PCB design, and careful topology planning.
The Dojo 3 architecture uses a tiling approach: groups of chips organized into "pods," with high-speed interconnects within pods and lower-latency interconnects between pods. This mimics how biological neural networks are organized, which is theoretically elegant but practically challenging to implement.
Power and Thermal Design
Power efficiency sounds good in spec sheets. It's much harder to achieve in physical systems.
Consider the basic physics. If you're running 10,000 chips at 250W each, that's 2.5 megawatts of continuous power consumption. All of that power ultimately becomes heat. Your data center cooling system needs to remove 2.5 megawatts of thermal energy 24/7.
Nvidia solved this with conventional liquid cooling. Dojo 3 is designing something more aggressive: direct-to-chip cooling where cooling fluid flows directly over the silicon die. This is more efficient but more complex. Leaks are catastrophic. Thermal cycling stresses the solder joints.
Tesla's advantage here is experience building thermal systems. They've been managing thermal challenges in electric vehicles and battery packs for 15+ years. That expertise is applicable to chip cooling.
But scaling from a single vehicle battery pack to a megawatt-scale data center is orders of magnitude different. The thermal engineering is fundamentally harder.
Memory Architecture and Bandwidth
AI training involves moving enormous amounts of data. Model parameters, activation values, gradient updates. All of that flows through memory.
Hopper uses HBM3 (High Bandwidth Memory), which packs RAM incredibly densely and delivers 3.2 terabytes per second of memory bandwidth. That's massive. It's also expensive and power-hungry.
Tesla's AI5 likely uses a custom memory configuration. The question is whether they can match HBM3 bandwidth while maintaining their power advantage. If they can't, training speed suffers. If they try to match bandwidth directly, power consumption creeps back up.
This is a fundamental tradeoff. Tesla is making conscious choices about bandwidth versus power. Those choices are baked into the silicon and can't be changed without a new chip revision.
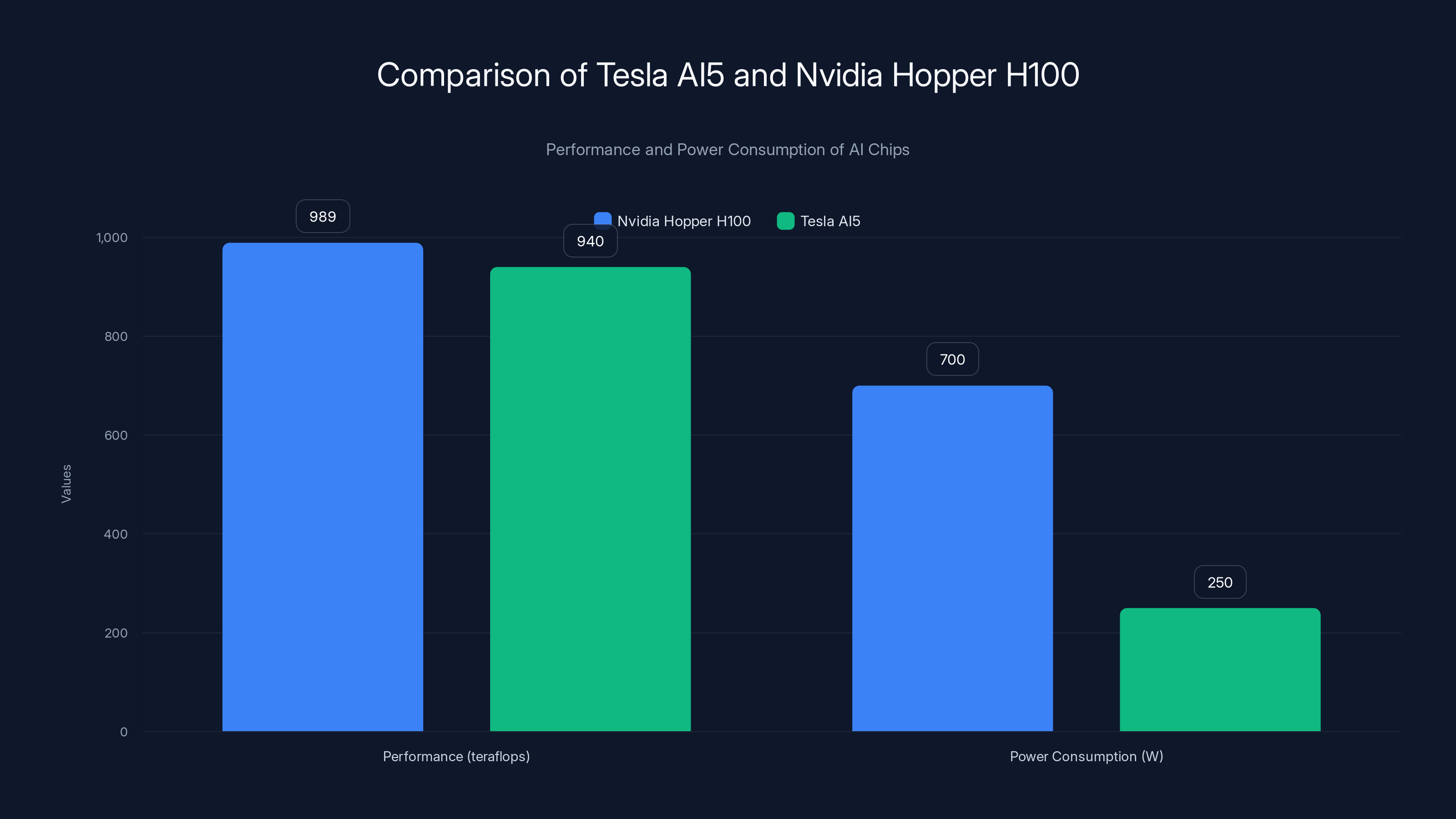
Tesla's AI5 chip achieves similar performance to Nvidia's Hopper H100 with a 64% reduction in power consumption, offering significant operational savings. Estimated data for AI5 performance.
The Software Stack: Why Chip Design Is Only Half the Battle
Build an amazing supercomputer, and you still need amazing software to run on it.
Nvidia's advantage isn't just CUDA (their programming framework). It's the ecosystem. Every major deep learning framework (Py Torch, Tensor Flow, JAX) optimizes for CUDA. Every model is tested on CUDA. Every research paper shows CUDA performance.
Tesla has to write custom software to run on Dojo 3. That means:
- Custom compilers to translate high-level code into AI5 machine code
- Custom libraries for common operations (matrix multiplication, convolution, attention mechanisms)
- Custom frameworks or heavy modifications to existing ones
- Debugging tools that don't exist yet
This is enormous work. And it's where many chip companies fail. They nail the hardware and fumble the software.
Tesla is publicly recruiting engineers to build this software stack. That's good transparency and realistic. But it signals that the software strategy isn't locked yet. When you're recruiting senior compiler engineers to work on a project, that project isn't as far along as you might think.
Integration With Existing ML Frameworks
Tesla has two options: write everything from scratch, or modify existing frameworks.
Writing from scratch is theoretically better (you optimize for your specific hardware) but takes 2-3 years and attracts 5 major bugs per 1,000 lines of code. Modifying existing frameworks is faster but constrained by architectural decisions made by Py Torch or Tensor Flow teams who didn't know about Dojo 3.
The smart move is a hybrid. Write custom backends for Py Torch and Tensor Flow that handle the heavy lifting on Dojo 3, while keeping the high-level API compatible. That's what Google did with TPUs, and it took them until 2023 to get it really right (even though TPU hardware shipped in 2017).
This timeline matters because it affects when Dojo 3 is actually useful. You can build the supercomputer, but if the software isn't ready for 18 months, you're burning power and cooling costs with nothing to show for it.
Use Cases: Self-Driving, Robotics, and Beyond
Why is Tesla building this? What problems does Dojo 3 actually solve?
Autonomous Vehicle Training
Tesla's primary use case is training self-driving models. Specifically, their end-to-end neural networks that take camera input and output steering/acceleration/braking commands.
These models are massive. Tesla's latest generation processes video from 8 cameras, maintaining temporal context across frames, and predicting not just the next action but the next 5-10 seconds of trajectory. That's computationally intensive.
Today, Tesla trains these models on a mix of in-house systems and cloud infrastructure. Building Dojo 3 changes the equation. Suddenly, they can train 5x faster on 1/3 the power consumption. That translates to faster iteration cycles and lower operational costs.
Let's do the math. If Tesla trains 50 trillion tokens per year (rough estimate based on their data volume), and Dojo 3 is 5x faster than their current setup, they're looking at 5 trillion fewer tokens per year needed to achieve the same progress. At
Multiply that across 5-10 years of operational life, and Dojo 3's investment (estimated $5-10 billion) starts to pencil out.
Optimus Robotics and Foundation Models
Tesla's humanoid robot, Optimus, is another key target. Training the policies that control a robot's movements requires simulating millions of scenarios. That's compute-intensive work.
Dojo 3 enables Tesla to train more diverse policies faster. A robot that learns from simulation can then be deployed and further refined through physical experience. The cycle time (simulate -> deploy -> learn from real data) shrinks when you have more compute.
Beyond Optimus, Tesla is investing in large language models. FSDv 13 (Full Self-Driving version 13) reportedly has a language model component that understands driving scenarios, traffic patterns, and edge cases. Training that model to the scale of Chat GPT-level performance requires supercomputer-class infrastructure.
Having Dojo 3 in-house means Tesla can iterate on language models without relying on cloud providers' APIs. That's strategic independence.
Competing With Cloud Providers
Here's the interesting part: Tesla is considering offering Dojo 3 as a service to external customers.
Think about that strategically. Tesla builds a supercomputer. They use it for self-driving and robotics. But they have excess capacity. Why let that compute sit idle? They could offer training services to other AI companies.
At
The risk is distraction. Tesla's core business is cars and robotics. Adding "data center operator" to the mix requires a completely different operational discipline and expertise.
But if they execute, it's a multi-billion dollar opportunity. The AI training market is forecast to reach $50+ billion annually by 2030.
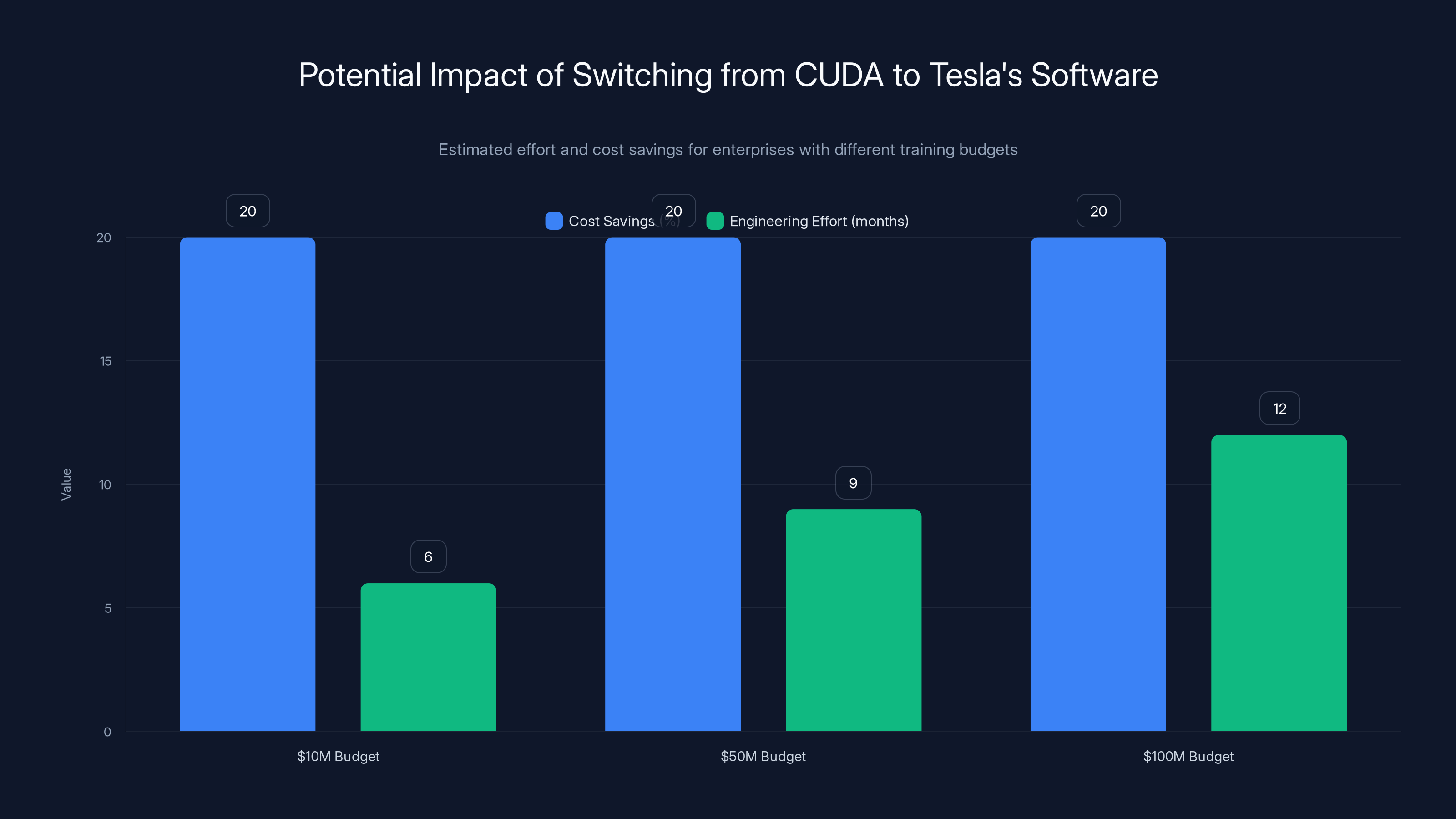
Estimated data shows that larger enterprises with a $100M budget might justify the 12-month effort for a 20% cost saving by switching from CUDA to Tesla's software.
The Roadmap: AI5, AI6, AI7, and Beyond
Dojo 3 isn't a static system. Tesla is planning a roadmap of chip generations with coordinated releases every 9 months.
AI5: The Foundation (2025-2026)
AI5 is the current focus. It's Tesla's first chip that genuinely rivals Hopper across dimensions that matter for their use cases. The engineering is solid. The power efficiency is real. The performance is competitive.
Deployment starts in 2025. By mid-2026, Tesla will have multiple Dojo 3 installations operational (likely one in Texas, one in Nevada, possibly one in Singapore for international operations).
The goal is 10,000-20,000 AI5 chips deployed across these facilities by end of 2026.
AI6: Performance Improvements (2026-2027)
AI6 is planned to launch 9 months after AI5. This isn't a radical redesign. It's an incremental improvement.
Expectations include:
- 15-20% better performance through optimized layouts and higher clock speeds
- 10-15% better power efficiency through improved process node or better thermal design
- Better memory bandwidth (possibly upgraded to HBM4 if it becomes available)
- Expanded feature set for newer workloads (attention mechanisms, mixture-of-experts, dynamic neural networks)
AI6 maintains compatibility with AI5 software while providing benefits for new models.
AI7: Looking Toward 2027-2028
AI7 is further out and more speculative. At this point, Nvidia will have shipped multiple new generations. The competitive landscape will have shifted.
Tesla is counting on sustained process node improvements (moving to smaller transistors) to maintain relative performance advantage. They're also betting on architectural innovations that Nvidia can't easily copy.
But here's the reality: if Tesla maintains a 9-month cadence while Nvidia maintains a 18-24 month cadence, Tesla should gain relative advantage. By 2027, Tesla's AI7 could be 2-3 generations ahead of Nvidia's contemporaneous offering in terms of design maturity.

Manufacturing at Scale: The Biggest Challenge
Designing a chip is one challenge. Manufacturing millions of them is another.
Tesla doesn't own a semiconductor foundry. They partner with TSMC (Taiwan Semiconductor Manufacturing Company) to manufacture their chips. TSMC is excellent but also heavily allocated. When Apple needs capacity, Samsung needs capacity, and everyone else needs capacity, queue positions matter.
For Dojo 3 to be viable, Tesla needs dedicated manufacturing capacity. That means:
- Capital commitment: $5-10 billion to secure multi-year supply agreements
- Production ramp: 1,000 AI5 chips per month in 2025 ramping to 10,000+ by 2027
- Quality control: AI chips can't have the defect tolerance of other silicon; every failed chip is a $1,000-5,000 loss
- Supply chain resilience: Taiwan geopolitics matter; if access to TSMC is restricted, Dojo 3 is dead
Tesla is publicly recruiting chip manufacturing specialists. That signals serious intent. But scaling from engineering samples to high-volume production is where many chip ambitions die.
TSMC Partnership Dynamics
TSMC manufactures chips for nearly every major tech company. They're incredibly skilled but also politically complex.
When there's a supply crunch (which there is, constantly), TSMC allocates capacity based on:
- Long-term contracts and commitments
- Volume guarantees
- Profit margins
- Strategic importance
Tesla's asking for a lot of capacity very quickly. That makes TSMC nervous. What if Dojo 3 fails? What if Tesla's roadmap delays? TSMC bears the risk of idle capacity.
On the flip side, Tesla is offering TSMC multi-year commitments and massive volumes. TSMC likes that certainty.
This negotiation is happening behind closed doors, but the outcome determines whether Dojo 3 scales or stalls.

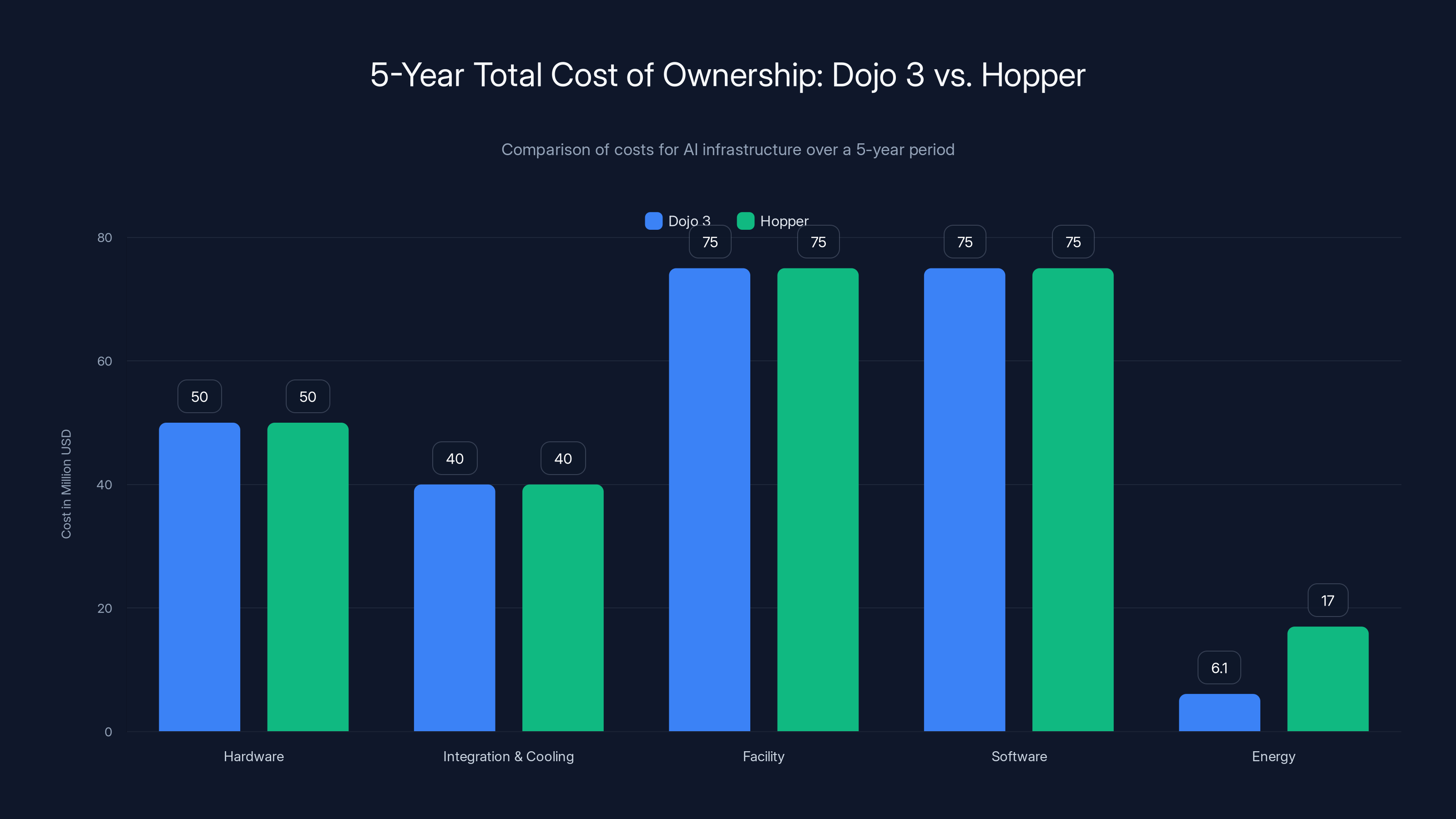
Dojo 3 offers significant savings in energy costs over 5 years compared to Hopper, with a $10.9 million reduction in energy expenses alone.
Power Consumption and Data Center Economics
All this talk about efficiency gains means nothing if we don't ground it in real-world economics.
Let's build a simple model. Dojo 3 system with 10,000 AI5 chips:
- Hardware cost: ~50 million
- System integration, interconnect, cooling: $30-50 million
- Data center facility: $50-100 million (land, building, power infrastructure)
- Software development: $50-100 million
- Operations (5 years): Depends heavily on power efficiency
Now the power part:
- Power consumption: 10,000 chips × 250W = 2.5 megawatts
- Annual operating hours: 8,760 hours × 70% utilization = 6,132 hours
- Annual energy consumption: 2.5 MW × 6,132 hours = 15.3 GWh
- Annual energy cost (at 1.22 million
- 5-year energy cost: $6.1 million
Compare with Hopper:
- Power consumption: 10,000 chips × 700W = 7 megawatts
- 5-year energy cost: $17 million
Savings from Dojo 3 vs. Hopper: $10.9 million in energy costs alone.
That's not a small number. Multiply across multiple Dojo 3 installations, and you're looking at $50+ million in 5-year operational savings.

Risk Factors: What Could Go Wrong
Tesla's Dojo 3 bet is aggressive. There are real risks.
Execution Risk
Tesla is planning chip releases every 9 months. That's fast. The fastest semiconductor companies (AMD, Intel at their peak) managed 12-18 month cadences. Tesla is more ambitious than the industry norm.
Why? Because Elon Musk drives aggressive timelines. Historically, those timelines slip. FSD was supposed to be complete by 2018. Roadster was supposed to ship in 2017. Starship was supposed to land on the moon in 2023.
When timelines slip on chips, it compounds. If AI5 is delayed 6 months, then AI6 gets delayed 6 months, then AI7. Suddenly Nvidia has shipped 2 new generations and your competitive advantage evaporates.
Software Maturity Risk
No matter how good the hardware, if the software isn't ready, the system is useless.
Tesla is recruiting aggressively, but compiler engineers and systems software experts are scarce. The ones who are available are probably already working at Google, Apple, or NVIDIA. Attracting them requires both compensation and credibility.
Tesla's credibility on chip software is limited. They've mostly integrated off-the-shelf components. Building world-class ML compiler and runtime systems is new territory.
Manufacturing Risk
TSMC is the world's premier foundry, but they're also fully allocated. If something goes wrong (geopolitical tensions, yield issues, capacity constraints), Dojo 3's ramp stalls immediately.
Tesla could mitigate this by developing relationships with Samsung or Intel, but that requires multi-year, multi-billion dollar commitments. And frankly, Samsung and Intel aren't at TSMC's process quality level.
Market Adoption Risk
Dojo 3 is designed for Tesla's internal use. But if Tesla wants to offer it as a service to external customers, they need to convince researchers and enterprises to adopt a new platform.
That's hard. Everyone knows CUDA. Everyone has Py Torch on CUDA. Convincing people to switch to Dojo 3 requires massive price advantages or performance advantages. Tesla has the former but not (yet) the latter.

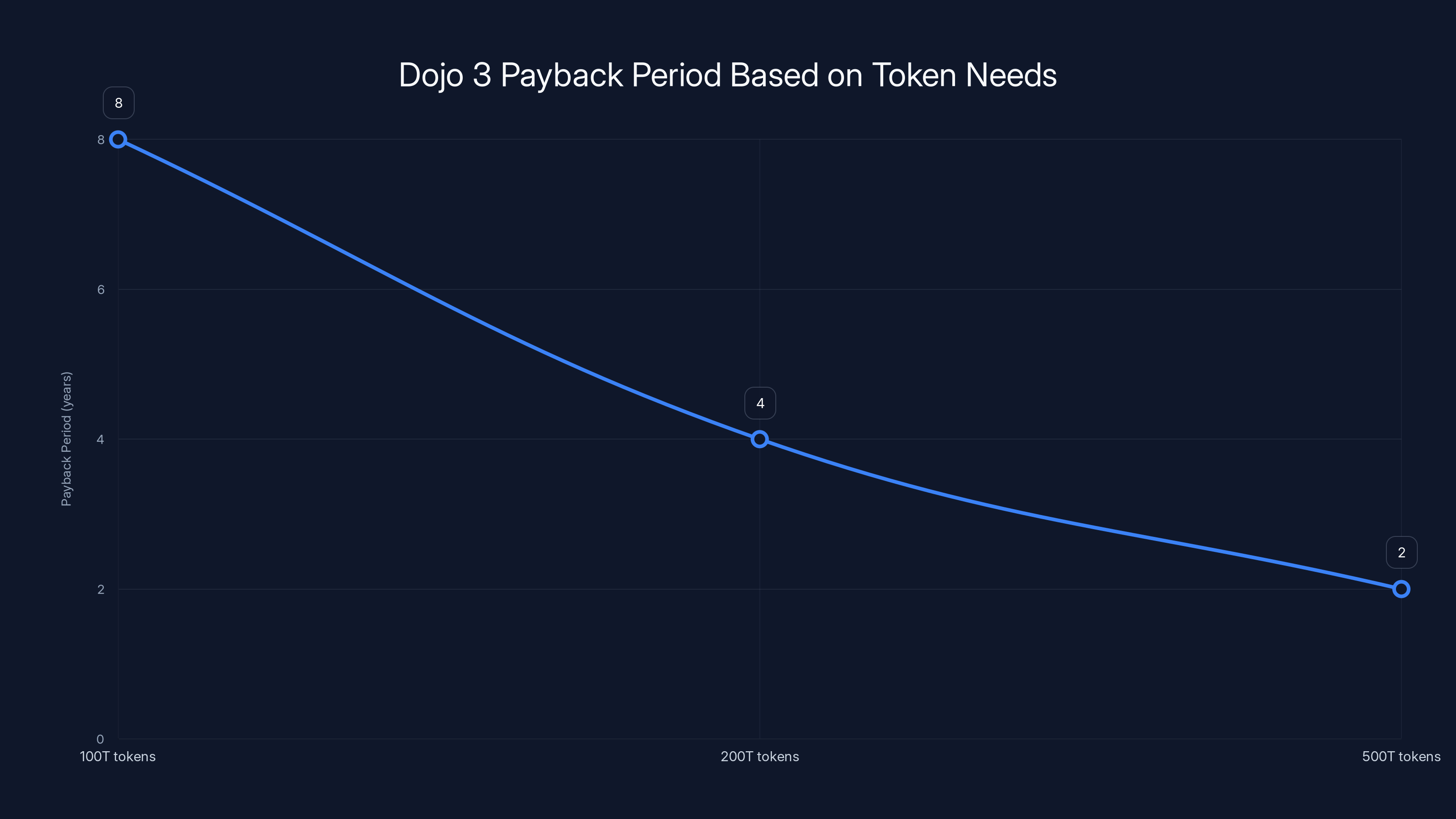
As Tesla's AI training needs grow, the payback period for Dojo 3 decreases significantly, from 8 years at 100 trillion tokens to just 2 years at 500 trillion tokens. Estimated data based on projected growth.
Tesla's Broader AI Strategy: Where Dojo 3 Fits
Dojo 3 isn't Tesla's only AI play. It's one component of a larger strategy.
Self-driving development: Training neural networks on petabytes of driving data
Optimus robotics: Building AI models that control humanoid robots
Energy storage and grid optimization: Using AI to predict and optimize power flow
Foundational models: Training proprietary language models and vision models that power Tesla's products
Dojo 3 is the compute infrastructure that enables all of these. It's the substrate that Tesla's AI strategy runs on.
But here's the key insight: Tesla doesn't need Dojo 3 to be profitable on its own. It just needs to be cheaper and more capable than the alternative (renting compute from cloud providers).
If Dojo 3 saves Tesla $50 million annually in cloud compute costs, that's the business case right there. Everything beyond that (selling excess capacity externally, enabling new products) is upside.

Timeline: When Can We Expect Results?
Let's set realistic expectations.
Q1 2025: First AI5 test chips from TSMC. Initial integration into Dojo 3 prototype.
Q2-Q3 2025: Scaling AI5 production. Building first Dojo 3 facility in Texas or Nevada.
Q4 2025: Initial training workloads on Dojo 3. Validating performance claims against real models.
Q1-Q2 2026: Ramping to 10,000+ AI5 chips deployed. Achieving cost savings targets.
Q3 2026: AI6 design finalization. Production begins at TSMC.
Q4 2026 - Q1 2027: AI6 deployment begins. Performance improvements validated. International expansion (Singapore facility) ramping.
2027+: AI7 development, continued scale, potential external offering to customers.
This is aggressive but plausible if execution remains on track. The first major test is whether AI5 actually hits performance and power targets in the real world. Not in engineering simulations, but in actual Dojo 3 systems running actual training workloads.

Competitive Response: How Will Nvidia React?
Nvidia isn't sitting idle while Tesla builds Dojo 3.
Blackwell and Next-Generation GPUs
Nvidia's Blackwell architecture is already in production. Next-generation hardware (Vera, Rubin) is on the roadmap through 2027-2028.
These architectures are designed with Tesla's concerns in mind. Better power efficiency, better cost per teraflop, tighter software integration through CUDA.
Nvidia's advantage is software maturity. CUDA has been optimized for 20 years. It's integrated into every framework, every library, every model. That's not easily replicated.
Software Ecosystems and Moats
Here's Nvidia's real defense: ecosystem lock-in.
Every deep learning framework (Py Torch, Tensor Flow, JAX) has primary development targeting CUDA. Every research paper reports CUDA performance. Every enterprise deployment uses CUDA.
Switching from CUDA to Tesla's software would require:
- Rewriting training scripts
- Reoptimizing models
- Retraining on new hardware (because different hardware has different numerical behavior)
- Revalidating results
For a $10 million annual training budget, 20% savings isn't worth 6 months of engineering effort.
But for a $100 million training budget, 20% savings justifies 12 months of engineering effort. Tesla's bet is that sufficiently large customers will find the switching cost acceptable.
Price Pressure
Regardless of who wins technically, Dojo 3's existence puts price pressure on Nvidia.
If Tesla offers equivalent performance at 40% of the price, Nvidia has to respond. They can't match Tesla's cost structure (Tesla controls the full stack), so they have to innovate harder or accept lower margins.
Historically, when a competitor undercuts Nvidia, Nvidia responds by improving product faster and aggressively pricing its own offerings. See: AMD's challenge to Intel, and how Intel responded with faster innovation and competitive pricing.
Nvidia has cash, expertise, and customer relationships. They won't lose this market without a fight.

International Expansion and Geopolitical Factors
Tesla's mentioned a Singapore facility for Dojo 3. That signals thinking beyond the US.
Why Singapore? It's politically stable, has excellent cooling water access, and serves the Asia-Pacific region. It's also strategically important as a potential second source if US-China tensions escalate.
Taiwan Dependence
The critical vulnerability is TSMC. Taiwan's geopolitical status is uncertain. If something happens that restricts access to TSMC, Tesla's entire Dojo 3 roadmap collapses.
Tesla could address this by developing relationships with Samsung Foundry or Intel Foundry Services, but that requires capital, time, and political capital.
It's a real risk that gets underestimated because it's outside the normal technology discussion. But from a strategic planning perspective, relying 100% on TSMC for AI infrastructure is dangerous.
Global AI Compute Resilience
Future AI systems might be distributed globally: training clusters in multiple countries, inference served locally to reduce latency.
Dojo 3 could enable that. A Singapore Dojo 3 facility trains models locally on regional data. European facility trains on European data. This approach:
- Reduces regulatory friction (data locality requirements)
- Improves inference latency (local serving)
- Builds resilience to regional disruptions
- Supports localized AI models trained on regional preferences
It's more expensive than a single centralized facility, but strategically more defensible.

Cost Analysis: Is It Worth the Bet?
Let's run some numbers on whether Dojo 3 makes financial sense.
Tesla's annual AI training needs (estimated):
- Self-driving training: 50-100 trillion tokens
- Robotics training: 10-20 trillion tokens
- Other initiatives: 10-20 trillion tokens
- Total: ~100 trillion tokens annually
Cost comparison:
Cloud compute alternative (using AWS p 3 instances):
- ~$30 per hour
- Training 100T tokens at 50M tokens/hour = 2 million hours
- Annual cost: $60 million
Dojo 3 alternative:
- Capital: $300 million (hardware, facility, software)
- Operating: $10 million annually (power, cooling, maintenance)
- Amortized over 5 years: 50 million = $110 million total
- Per year: $22 million
Annual savings:
Payback period: ~8 years
That's reasonable if Tesla's needs scale. If they increase to 200 trillion tokens annually, payback drops to 4 years. If they get to 500 trillion tokens (supporting both internal and external customers), payback is 2 years.
The bet is that Tesla's compute needs will grow fast enough to justify the investment. Given their ambitions with self-driving, robotics, and models, that's not unreasonable.

What This Means for the AI Industry
Dojo 3 isn't just about Tesla. It represents a broader trend: vertical integration of AI infrastructure.
The End of One-Size-Fits-All Computing
For decades, the pattern was: specialized companies (Intel, Nvidia) built general-purpose chips. Every customer used the same hardware.
That's changing. Google builds TPUs for their use cases. Apple builds M1 chips for their use cases. Tesla is building AI5 for their use cases.
Why? Because general-purpose hardware compromises. It needs to support a wide range of workloads, which means you sacrifice efficiency in any single domain.
Specialized hardware, optimized for your specific workload, wins on efficiency and cost. It loses on flexibility.
But if your workload is well-defined (Tesla's is: training neural networks, serving predictions), specialization is a win.
Implication: Rising Capex for AI Leaders
If every large AI player needs to build custom infrastructure, capex requirements explode.
Open AI needs infrastructure. Anthropic needs infrastructure. Meta needs infrastructure. Microsoft needs infrastructure (for Azure customers). Google needs infrastructure. Amazon needs infrastructure.
All of them are now thinking about custom chips and specialized supercomputers.
This is expensive. It requires:
- Chip design expertise
- Manufacturing relationships
- Software engineering talent
- Data center operations
Not every company can afford this. Winners (those with strong balance sheets and AI leadership) will invest. Losers will depend on cloud providers' generic infrastructure.
This concentration of capability among well-funded players is a feature of the 2025-2030 AI landscape.
The Skeptic's View: Why Dojo 3 Might Fail
I've been constructive about Dojo 3. Let me be critical.
Timeline risk is real. Tesla's Dojo 1 and Dojo 2 failed. Why will Dojo 3 succeed? Because the chip design is better. But that's what they said about Dojo 1 and Dojo 2.
Software integration is genuinely hard. Building a world-class ML framework takes Google $100+ million and 5+ years. Tesla is recruiting but hasn't proven they can execute at that level.
Manufacturing at scale requires discipline. Tesla has manufacturing discipline in cars. Semiconductor manufacturing is different: tighter tolerances, less room for iteration, more sensitive to supply chain disruptions.
Competitive response will be fierce. Nvidia isn't a company that loses market share without a fight. They'll cut prices, accelerate innovation, and leverage their software moat ruthlessly.
Market adoption might be slow. Even if Dojo 3 is great, convincing external customers to use it instead of CUDA is a multi-year slog.
So here's my honest assessment: Dojo 3 will likely succeed as internal infrastructure for Tesla. It'll save them money and improve iteration speed. As an external offering competing with Nvidia, it faces much harder challenges.
That's not failure—it's just realistic assessment of the difficulty.

FAQ
What exactly is Dojo 3?
Dojo 3 is Tesla's supercomputer project designed to train and run large-scale AI models using entirely custom, in-house hardware. Unlike earlier Dojo versions that mixed Tesla and Nvidia components, Dojo 3 is built entirely on Tesla's custom AI5 chips and supporting systems, enabling full control over performance, power efficiency, and optimization.
How does Tesla's AI5 chip compare to Nvidia's H100?
Tesla's AI5 chip targets similar performance to Nvidia's Hopper (H100) while consuming approximately 65% less power (250W vs 700W). However, Nvidia's ecosystem advantage and faster software maturity may offset the hardware efficiency gains for many users. The comparison with Blackwell (Nvidia's newer generation) is closer, reducing Tesla's claimed advantage.
Why did Dojo 1 and Dojo 2 fail?
Dojo 1 became outdated quickly because it mixed Tesla silicon with external Nvidia components, limiting optimization and control. Dojo 2 was cancelled before completion because Tesla identified fundamental architectural limitations that would have made the system uncompetitive. These failures prompted the complete redesign approach taken with Dojo 3.
What will Dojo 3 be used for?
Tesla's primary use cases for Dojo 3 include training self-driving neural networks, developing AI models for the Optimus humanoid robot, and creating foundational language models. Tesla is also considering offering excess compute capacity as a commercial service to external customers, effectively competing with cloud providers.
Can Tesla actually maintain a 9-month chip release cycle?
A 9-month cycle is faster than industry norm (typically 12-24 months for major chip iterations). While ambitious, it's technically feasible if Tesla properly resources the effort and doesn't encounter unexpected design issues. However, Tesla's historical track record suggests timelines often slip, so realistic deployment might be 12-18 months between generations.
What are the biggest risks to Dojo 3's success?
Key risks include execution delays on chip design and manufacturing, software framework immaturity, TSMC supply chain dependencies, manufacturing quality issues at high volume, and slow adoption if offered commercially. Additionally, Nvidia's response through Blackwell and future architectures could erode Tesla's competitive advantages faster than expected.
How much will Dojo 3 cost to build and operate?
Estimates suggest
Could Dojo 3 threaten Nvidia's market position?
Dojo 3 is unlikely to completely displace Nvidia, but it could reduce Nvidia's pricing power and create pressure for innovation. If successful, it demonstrates that specialized AI infrastructure can outperform general-purpose GPUs, potentially inspiring competitors and large enterprises to explore custom solutions.
Why is vertical integration important for AI supercomputers?
Vertical integration (controlling chip design, system architecture, and software) enables co-optimization that's impossible when combining components from different vendors. A Tesla-designed chip paired with Tesla-designed interconnect and Tesla-designed software can achieve efficiency gains impossible with standard Nvidia GPU + third-party integration. This is why Google's TPUs and Apple's chips outperform general-purpose alternatives.
When will Dojo 3 actually be operational?
Based on Tesla's publicly stated timeline, initial Dojo 3 systems should begin operations in Q4 2025 or Q1 2026. Full deployment of the initial facility (targeting 10,000+ AI5 chips) is likely complete by mid-to-late 2026, assuming manufacturing schedules stay on track. International expansion and subsequent chip generations (AI6, AI7) would follow in subsequent years.
Final Thoughts: The Bet and the Broader Implications
Elon Musk is betting that vertical integration beats general-purpose commodity hardware. That proprietary silicon, optimized for specific workloads, beats off-the-shelf solutions. That Tesla can execute chip design, manufacturing, and software better than companies who've been doing it for decades.
It's an ambitious bet. The chips alone represent a
That's $15-25 billion in capital allocation to a project with significant execution risk.
But the upside is enormous. If Dojo 3 works, Tesla achieves computing sovereignty. They no longer depend on Nvidia for their most critical infrastructure. They can iterate faster on AI research and development. They reduce operational costs significantly.
And if they can offer it externally, they enter a multi-billion dollar new market where they compete on cost and performance against AWS, Google Cloud, and Azure.
Will it work? Probably partially. Tesla will likely achieve cost savings and performance improvements for internal use cases. The question is whether they can scale it, maintain the roadmap cadence, and build software good enough that external customers switch from CUDA.
History suggests that's harder than it sounds. But Tesla has surprised before. And the AI infrastructure market is large enough that even partial success represents a significant strategic win.
The next 24 months will be telling. If AI5 chips ship on schedule and integrate well into Dojo 3, Tesla's on track. If there are delays or integration challenges, the entire roadmap becomes questionable.
Either way, Dojo 3 represents a strategic pivot that will reshape how enterprise AI infrastructure is built and deployed over the next decade.

Key Takeaways
- Tesla's Dojo 3 represents a complete vertical integration strategy, controlling chip design through software, unlike failed Dojo 1 and 2 projects that relied on external components
- AI5 chip claims competitive performance with Nvidia's Hopper (989 TFLOPS equivalent) while consuming 250W versus 700W, creating a 64% power efficiency advantage that translates to $10.9M in 5-year operational savings
- Manufacturing scalability remains the critical unknown: Tesla must maintain a 9-month chip release cadence while ramping from prototypes to 10,000+ unit annual production, faster than industry standards
- Software ecosystem immaturity poses execution risk greater than hardware challenges; building world-class ML frameworks requires $100M+ and proven expertise Tesla hasn't demonstrated at this scale
- If successful, Dojo 3 demonstrates that specialized AI infrastructure outperforms general-purpose GPU solutions for specific workloads, potentially inspiring broader industry shift toward vertical integration
Related Articles
- Inferact's 800M Startup [2026]
- RadixArk Spins Out From SGLang: The $400M Inference Optimization Play [2025]
- Telco AI Factory: Building Intelligent Communications Networks [2025]
- Why Microsoft Is Adopting Claude Code Over GitHub Copilot [2025]
- Building Your Own AI VP of Marketing: The Real Truth [2025]
- Nvidia's $1.8T AI Revolution: Why 2025 is the Once-in-a-Lifetime Infrastructure Boom [2025]

