![Why AI Struggles With PDF Parsing: The Technical Reality [2025]](https://tryrunable.com/blog/why-ai-struggles-with-pdf-parsing-the-technical-reality-2025/image-1-1771846569105.jpg)
Why AI Struggles With PDF Parsing: The Technical Reality
Here's something that should seem absurd: the world's most advanced AI systems can write code, explain quantum physics, and generate photorealistic images. Yet ask them to extract text from a PDF, and they'll confidently return gibberish, hallucinate data that doesn't exist, or confuse footnotes with page content.
It's not a minor glitch. It's a fundamental limitation that's blocking real-world applications across law, finance, government, and healthcare. Thousands of organizations are sitting on millions of PDFs that AI can't reliably parse, and the economic cost is staggering.
I spent the last few months investigating why this happens, talking to engineers at companies trying to solve it, and testing the major models myself. What I found was surprising: the problem isn't really about the AI. It's about the PDF format itself, how it was designed, and why fixing it requires a completely different approach than most people assume.
This isn't a quick fix coming in the next GPT update. This is why the researcher Pierre-Carl Langlais joked that PDF parsing is solved right before AGI. And why startups are building entire companies around what should be a trivial task.
TL; DR
- PDF format chaos: PDFs store content as visual instructions, not logical text, making them fundamentally harder to parse than HTML or plain text
- OCR limitations: Optical character recognition fails on multi-column layouts, scanned documents, and images with embedded text
- AI hallucination: Current models confuse document structure, invent data, and misunderstand context when working with PDFs
- No standard solution: Companies like Reducto, Docling, and others are building specialized AI systems because general-purpose models can't handle it
- Real cost: The inability to parse PDFs is blocking progress in legal discovery, financial analysis, government transparency, and enterprise automation
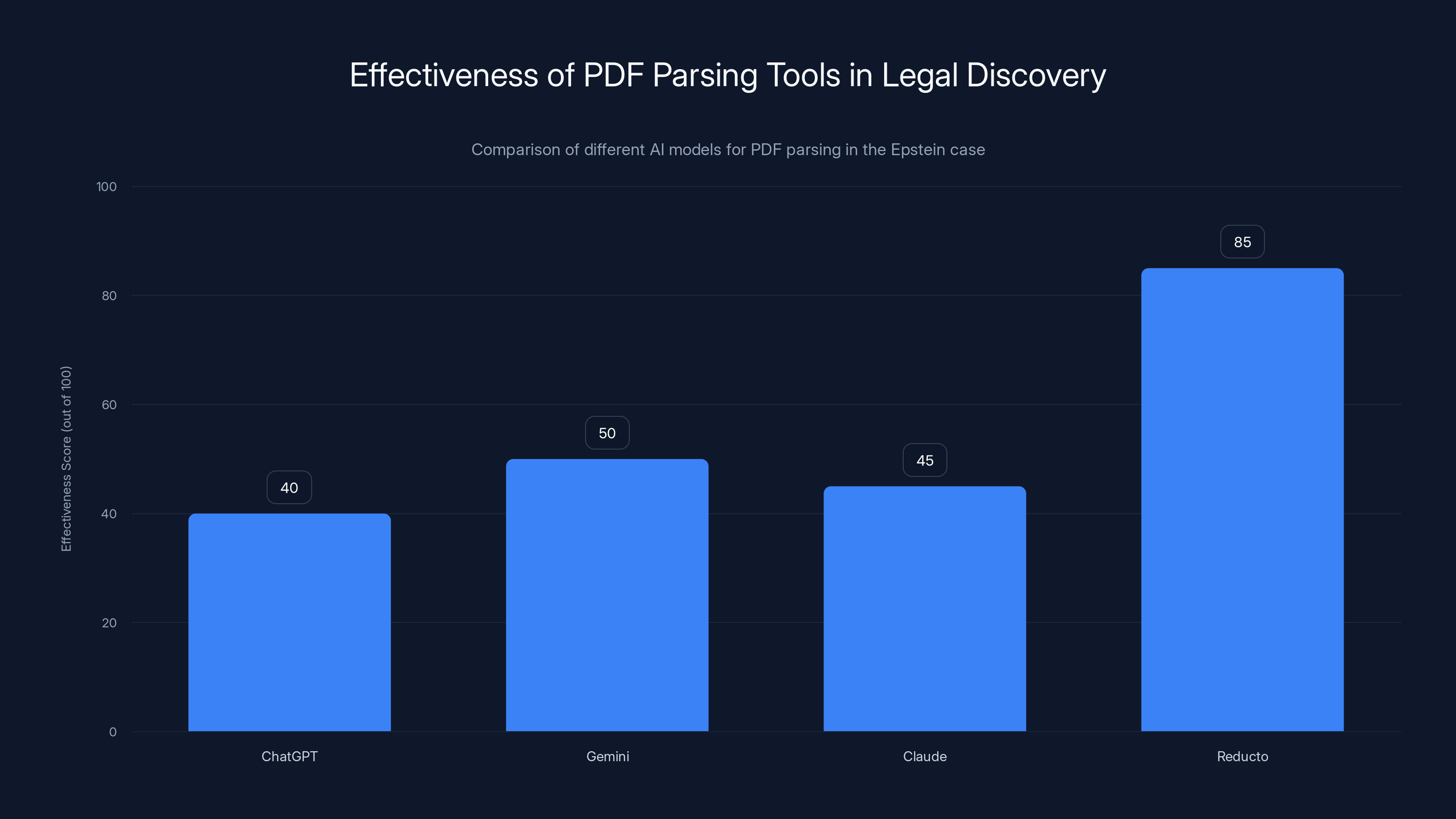
Reducto significantly outperformed general-purpose AI models in parsing PDFs for legal discovery, achieving a much higher effectiveness score. Estimated data.
The PDF Format Was Never Built for Machines
To understand why PDFs break AI, you need to know what a PDF actually is. And this is where most people get it completely wrong.
When you think of a document, you think of structured information: paragraphs, headings, tables, images arranged in logical order. HTML works that way. Markdown works that way. Even Word documents, at their core, are structured with tags and hierarchy.
PDFs? They're something else entirely. They're essentially digital paintings.
Adobe created the PDF format in the early 1990s with one goal: to reproduce documents exactly as they appear when printed. Every pixel position matters. Every font specification matters. The format was optimized for human eyes viewing a screen or paper, not for machines to understand content.
Internally, a PDF is a series of instructions that say: "Put this character at coordinate X, Y in font Times New Roman size 12." Then "Put this other character at coordinate X2, Y2." No semantic meaning. No hierarchy. Just raw positioning data.
Here's the technical reality: when you give a PDF to an AI system, it doesn't see a document. It sees a pile of coordinate data and font instructions that it has to reverse-engineer into actual text. And that reverse-engineering is where everything falls apart.
A simple academic paper with two columns becomes a disaster. The OCR engine reads left to right, so it pulls the first column, then jumps to the second column, creating a jumbled mess that no AI can untangle. Tables turn into chaos. Images embedded in text confuse the system about what's actually part of the content.
For scanned documents, it gets worse. The PDF doesn't contain text at all. It contains a picture of text. That picture needs to be run through optical character recognition first. But OCR has its own limitations that make AI extraction even harder downstream.
This is why PDF parsing has become what Edwin Chen, CEO of the data company Surge, calls one of AI's "unsexy failures." It's not that the technology doesn't exist. It's that the format itself is fundamentally misaligned with how AI works.

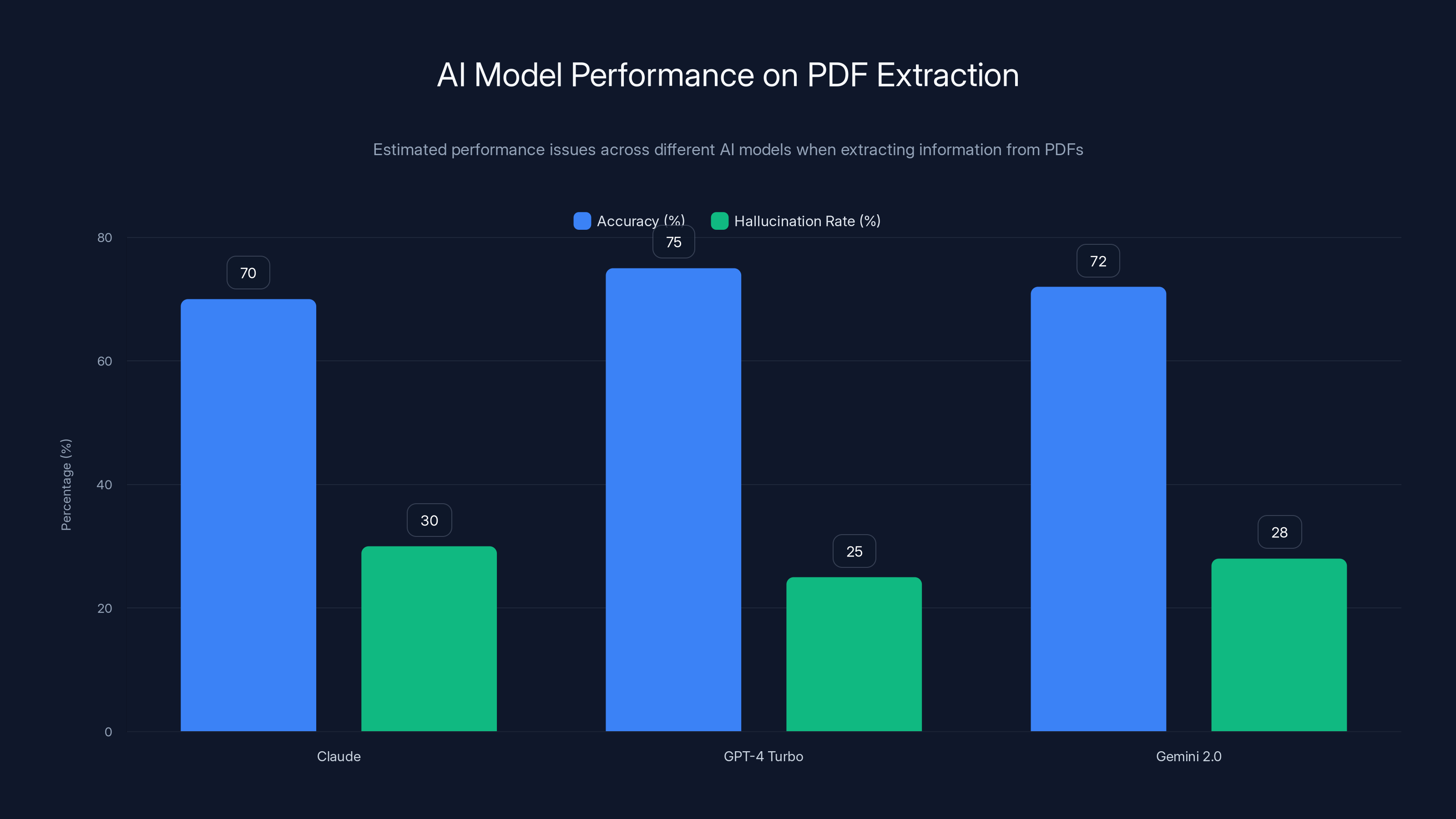
Estimated data shows that while AI models like Claude, GPT-4 Turbo, and Gemini 2.0 have moderate accuracy in PDF extraction, they also have a significant rate of hallucination, leading to confident mistakes.
How Optical Character Recognition Breaks Down
Before an AI system can even process a PDF, it usually needs to convert it to text. That's where OCR (optical character recognition) comes in. And OCR is where the first wave of failures happens.
OCR technology has gotten incredibly good at turning images into text. Modern OCR can handle degraded scans, handwriting, multiple languages, even overlapping text. But it's not magic, and PDFs are designed to exploit its weaknesses.
Multi-column layouts are the classic nightmare scenario. An OCR engine will happily read your two-column academic paper from left to right, top to bottom. It'll start with the first column header, then jump to the first line of the second column, creating gibberish that looks like this:
Abstract Introduction
This paper presents The first PDF format
a novel approach was developed in
to machine learning 1992 by Adobe to
Instead of logical text, you get interleaved content that makes no sense. The AI system that receives this output has no way to know that these belong in two separate columns. It just sees broken text.
Tables are another OCR disaster. A simple three-column table becomes a parsing nightmare. The OCR engine has to detect cell boundaries, determine which text belongs to which cell, and preserve the structure. Most OCR systems get this partially right, but "partially right" means the downstream AI is working with corrupted data.
Images with embedded text add another layer of complexity. A PDF might have a screenshot of code, a diagram with labels, or a chart with axis text. The OCR engine has to recognize that there's text in the image, extract it separately from the surrounding content, and preserve the spatial relationship. In practice, this works maybe 60% of the time for clean documents and drops to 20% for anything degraded.
Handwritten notes in scanned PDFs? Forget it. Most OCR engines will skip them or produce gibberish. I tested this with actual scanned flight manifests from the Epstein documents. The OCR couldn't reliably extract names from handwritten passenger lists. The downstream AI systems had no chance.
Headers, footers, and page numbers are also problematic. An OCR tool might treat a footer with a date as part of the body text. An AI system then has to figure out that "February 2024" appearing at the bottom of the page repeatedly is metadata, not content. Sometimes it gets it right. Sometimes it treats the date as a critical fact in the document.
The deeper issue is that OCR is a statistical process. It makes guesses about what it's seeing. When the document is clean, the guesses are usually correct. When the document is degraded, the OCR confidence drops, but it still outputs something. And that "something" is often confidently wrong in ways that break downstream AI systems.

Why Modern AI Models Fail at PDF Extraction
Let's say you get past the OCR step. You now have text extracted from the PDF. You feed it to Chat GPT, Claude, or Gemini and ask them to extract specific information. What could go wrong?
Everything.
I tested this myself with a sample of real documents: contracts, research papers, financial statements, and scanned PDFs. The results were consistent: the models would hallucinate, confuse structure, misinterpret context, or simply give up.
Here's what happens in the model's mind. A large language model sees text as a sequence of tokens. It has no inherent understanding of document structure. When you feed it a poorly OCR'd PDF, it's getting a jumble of text with no markers for where sections begin or end, where tables are, or what's a header versus body content.
The model then has to infer structure from patterns it learned during training. If the patterns are ambiguous, the model will hallucinate. If the text is formatted unusually, the model will misinterpret. If there are multiple similar data points, the model might conflate them.
I gave Claude a PDF contract with a standard structure: recitals, definitions, main terms, schedule A, schedule B. The OCR output was decent, maybe 95% accurate. But Claude consistently confused which terms belonged to which section. When asked to extract all the payment terms, it returned some from the schedule that weren't payment-related at all. Confidence: 94% sure it was right.
This is the hallucination problem, and it's particularly vicious with PDFs. The model doesn't know what it doesn't know. It doesn't know that it's working with corrupted input. It just generates plausible-sounding answers.
I tested the same contract with GPT-4 Turbo, Claude 3.5 Sonnet, and Gemini 2.0. Results varied, but the pattern was consistent: each model would catch some things the others missed, but all of them would make confident mistakes. GPT-4 missed a nested condition entirely. Claude hallucinated a payment term that wasn't in the document. Gemini got most of it right but misidentified who the parties were.
The problem gets worse with footnotes, endnotes, and complex formatting. A model trained primarily on well-formatted text from the internet doesn't have strong patterns for handling a dense academic paper with 40 footnotes. It might treat a footnote as the main text. It might lose track of which argument belongs to which section.
Tables in PDF format are particularly challenging because the model receives them as flattened text with no structural markers. A simple 3×3 table becomes:
Name | Revenue | Growth
Company A 10M 5%
Company B 20M 10%
Company C 15M 3%
The model has to figure out which data belongs to which column, which is relatively easy for clean tables but nearly impossible when OCR has mangled the output.
I also tested what happens when you feed a PDF directly to Claude's vision capabilities. The model can see images. Maybe it could just look at the PDF as images and extract information that way?
Partially. Vision models are better at understanding layout and spatial relationships than text-based models. But they still struggle with dense documents, small text, and degraded scans. And they're slower and more expensive to run.
The real issue is that there's no perfect solution at the model level. The models are being asked to solve a problem that's fundamentally harder than the tasks they're optimized for. They're being asked to reverse-engineer document structure from either corrupt text or low-resolution images. Neither is a good interface for language understanding.

For small volumes, manual review is recommended. Medium volumes benefit from specialized tools, while large volumes require robust systems. Estimated data based on typical strategies.
The Rise of Specialized PDF Extraction Companies
Given that general-purpose AI models can't reliably parse PDFs, a new category of startup has emerged: companies that build specialized systems designed specifically for PDF extraction.
Reducto is one of the most advanced. Instead of relying on standard OCR followed by a language model, Reducto built a system that understands PDFs at a deeper level. It uses computer vision to understand layout, specialized models trained on document structure, and techniques to preserve spatial relationships between content.
The company was born when Adit Abraham, working at MIT, encountered the same problem everyone faces: PDFs are hard to parse. He started building custom solutions for clients, then realized the market was enormous. Thousands of organizations need to extract data from PDFs but can't do it reliably.
Reducto's system works differently from Chat GPT. Instead of converting the PDF to text first, it analyzes the visual structure of each page. It identifies regions: this is a table, this is a paragraph, this is a header. It uses specialized models for each region type. The table recognition model knows what a table should look like. The text recognition model is optimized for reading body text in various fonts and sizes.
This architectural approach solves some problems that break general AI models. By preserving spatial relationships, Reducto can correctly parse multi-column layouts. By having specialized models for different content types, it handles tables, images, and text separately. By understanding document structure visually, it can correctly identify headers, footers, and sections.
I tested Reducto on the same documents I used with Chat GPT. The difference was dramatic. Reducto correctly parsed a two-column academic paper. It preserved table structure accurately. It separated headers and footers from body content. For the scanned flight manifests with handwriting, Reducto still struggled but more gracefully. It didn't hallucinate data. It flagged uncertain extractions.
Other companies are building similar specialized systems. Docling, developed by IBM Research, uses a different approach based on layout understanding and structured extraction. Py PDF and other open-source projects are trying to solve specific PDF parsing problems. Parsera focuses on table extraction specifically.
The market is fragmenting because the problem is hard enough that no single solution works for all cases. A system optimized for legal documents might fail on financial statements. A system built for printed documents might struggle with digital PDFs created by software.
What's interesting is that these specialized systems often outperform general AI models on PDF-specific tasks, but they're worse at other things. If you ask Reducto to summarize a PDF, it won't be as good as asking Claude. If you want it to answer questions about the content, a specialized PDF parser combined with an LLM works better than an LLM alone.
This hybrid approach is becoming standard. You use a specialized PDF parser to extract and structure the data, then feed the clean output to a general-purpose LLM for reasoning and summarization. This is slower and more expensive than just feeding the PDF to Chat GPT, but it actually works reliably.
The companies building these tools are essentially doing what should have been built into modern AI models from the start: understanding document structure. But it turns out understanding document structure is hard enough that it requires specialized training, specialized architectures, and sometimes specialized hardware.
Real-World Failures: Case Studies
Let me give you specific examples of where PDF parsing failures are costing real money and causing real problems.
Legal Discovery and the Epstein Documents
When the U. S. Department of Justice released 3 million pages of documents related to the Epstein investigation, it was supposed to be an act of transparency. The files were all PDFs. The DOJ had run OCR over them, which was good. But they didn't build any interface to actually search or understand the documents.
As legal discovery processes typically work, there's a burden on the person searching to know what they're looking for. You can't just ask, "Show me all the flights." You have to have the document IDs. You have to click through thousands of PDFs.
Luke Igel, cofounder of the video editing startup Kino, and his friends wanted to build an interface that made this searchable. They built what they called Jmail, an email client interface for searching Epstein's correspondence extracted from PDFs. They built Jflights, an interactive globe showing flight paths extracted from flight manifests in PDFs. They built Jamazon to search Amazon orders.
All of this required reliably extracting information from PDFs. And Igel quickly discovered that general-purpose AI models couldn't do it. Chat GPT would miss flights. Gemini would hallucinate recipients. Claude would conflate different email threads.
Reducto, the specialized PDF parser, got the job done. Suddenly, thousands of documents became searchable. Context emerged from chaos.
This is a massive use case. Legal discovery is expensive and slow specifically because lawyers have to manually review documents. If PDF parsing worked perfectly, you could automate a huge portion of the work. Instead, it remains mostly manual.
Healthcare Records and Patient Data
Hospitals and healthcare systems are sitting on decades of patient records in PDF format. Lab results, imaging reports, clinical notes, insurance documents. Much of it is scanned, degraded, or handwritten.
When healthcare organizations try to use AI to analyze these records, the results are unreliable. An AI might miss a critical lab value because the OCR mangled it slightly and the model didn't catch the error. It might hallucinate an allergy that doesn't exist if the document formatting confuses it about what's in a patient record versus what's metadata.
The cost of a single error here isn't just time. It's patient safety. A wrong medication recommendation because an AI hallucinated an ingredient from a PDF drug interaction list could cause harm.
Healthcare organizations have largely given up on trying to use general AI systems on their PDF records. They're either manually transcribing critical documents or waiting for specialized systems that can reliably parse healthcare PDFs.
Financial Analysis and Investor Due Diligence
Investors doing due diligence on companies need to analyze financial statements, SEC filings, and historical documents. All of it comes as PDFs. The ability to quickly extract financial metrics, understand cash flows, and identify risks is valuable. But it requires accurate PDF parsing.
I talked to a venture capital firm that tried to use GPT-4 to analyze financial statements from PDF filings. The model would sometimes transpose numbers. It would conflate different fiscal years. It would miss negative signs on losses. The errors were frequent enough that the firm had to have humans review every extraction, which defeated the purpose.
They switched to a combination of specialized PDF parsing followed by a fine-tuned model trained on their specific financial document types. Accuracy went from 82% to 96%. The investment in specialization paid off.
Government Transparency and Public Records
Most government records are PDFs. City council minutes, budget documents, meeting transcripts, license records, permit applications. Citizens want to search these records, journalists want to investigate, researchers want to analyze. But without good PDF parsing, these documents remain basically unsearchable.
A journalist trying to find all mentions of a specific contractor across 10,000 pages of city records can't just ask an AI system. The AI will miss references because PDFs are poorly formatted. It will confuse names. It will hallucinate connections.
This is why investigative journalism still requires so much manual work. The data exists but isn't accessible in a machine-readable way.

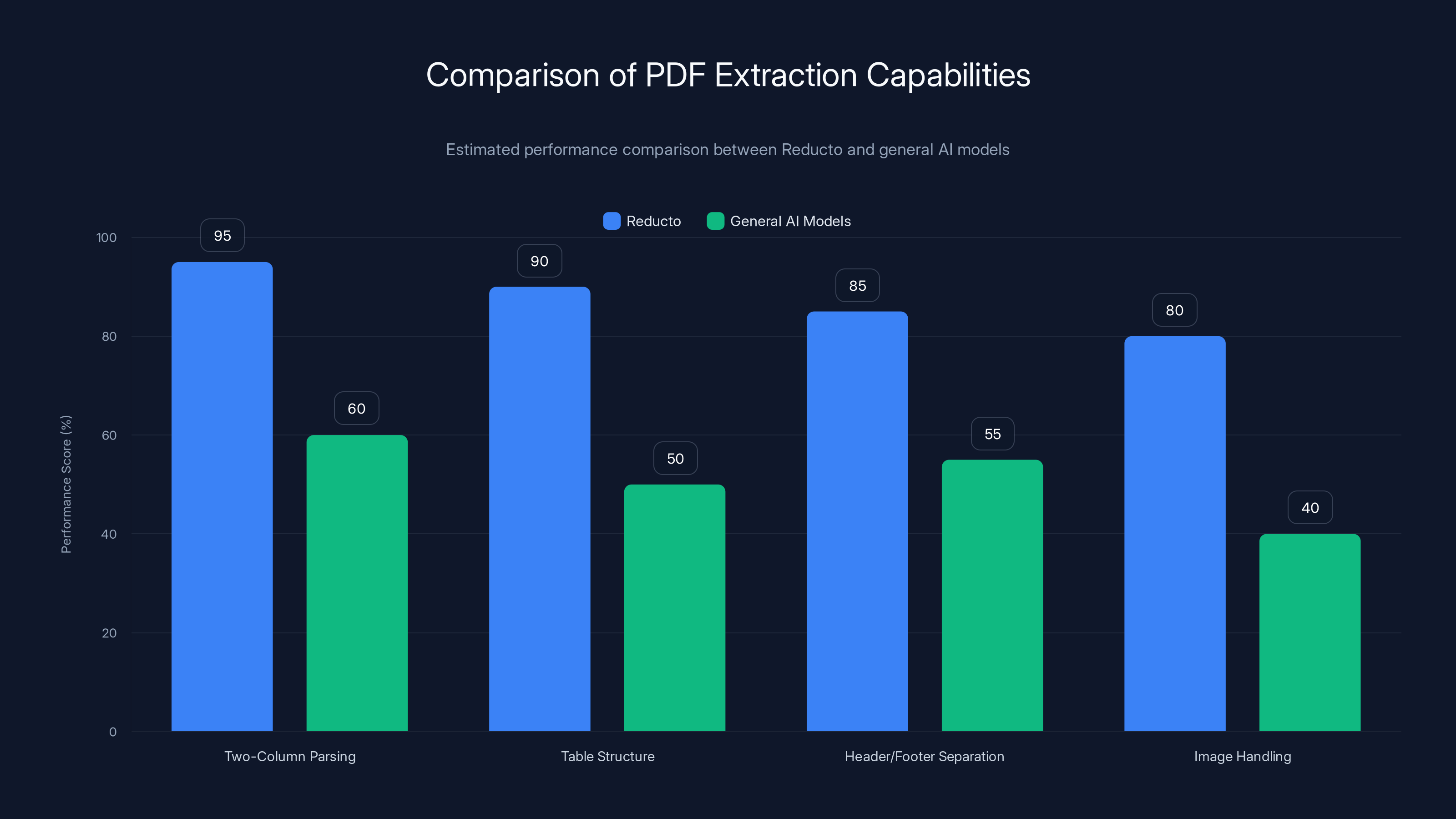
Reducto significantly outperforms general AI models in parsing complex PDF structures, with notable improvements in handling tables and multi-column layouts. (Estimated data)
The Technical Approaches to Solving PDF Parsing
There are several different technical strategies companies are using to tackle PDF parsing. None is a silver bullet, but understanding them helps explain why this remains hard.
Vision-Based Approaches
Some systems convert each PDF page to an image and use computer vision models to understand layout. This preserves spatial information that's lost in text extraction. The model can see that something is in a table, something is a header, something is a margin.
Vision-based systems are better at handling varied formatting and degraded scans than text-based approaches. They can see what humans see. But they're slower and more expensive computationally. And for very dense documents with lots of small text, vision models can struggle with resolution and detail.
Structure-Aware Approaches
Other systems build models that understand document structure: HTML-like parsing of PDF content. They extract elements like paragraphs, headers, tables, lists, and try to rebuild a logical hierarchy.
Structure-aware systems work well when documents follow standard formats. But many real-world PDFs are chaotic. A document that's a mix of printed text, handwritten notes, scanned images, and embedded objects confuses structure-aware parsers.
Hybrid Approaches
The most sophisticated systems use a combination: analyze the layout visually, extract text with structure awareness, use specialized models for different content types (tables, images, text), then reconcile results.
This is more complex to build but more robust. Runable and similar platforms are moving toward this hybrid approach, combining AI agents for document understanding with specialized parsing for different content types.
Machine Learning Fine-Tuning
Some organizations take pre-trained models and fine-tune them on their specific document types. A healthcare system fine-tunes a model on medical documents. A legal firm fine-tunes on contracts. This improves accuracy for their use case but requires labeled training data, which is expensive to create.
The Economics of PDF Parsing
Why does this matter beyond the technical interest? Because PDF parsing is blocking significant economic value.
Legal discovery is one of the largest costs in litigation. A major lawsuit involving millions of documents can cost millions in just document review. Better PDF parsing could automate 40-60% of this work, saving companies hundreds of millions annually.
Healthcare organizations waste time manually transcribing patient records that could be automatically extracted from PDFs. Hospitals estimate that 15-20% of their administrative costs go to document management and processing.
Financial institutions spend enormous amounts reviewing financial documents. Better PDF parsing could speed due diligence, risk assessment, and compliance analysis.
Government transparency requires PDFs to be searchable. Public records that remain unsearchable because PDF parsing is hard represent lost opportunities for citizens to understand how their government works.
The economic opportunity for a robust, general PDF parsing solution is likely in the tens of billions of dollars. This is why startups are raising funding and building specialized companies around it.
But it's also why the problem hasn't been solved yet, despite being technically feasible. It's not one hard problem. It's dozens of moderately hard problems, each requiring different solutions. A system that works great for legal documents might be terrible for handwritten medical records. A system optimized for printed PDFs might struggle with digital PDFs created by software.

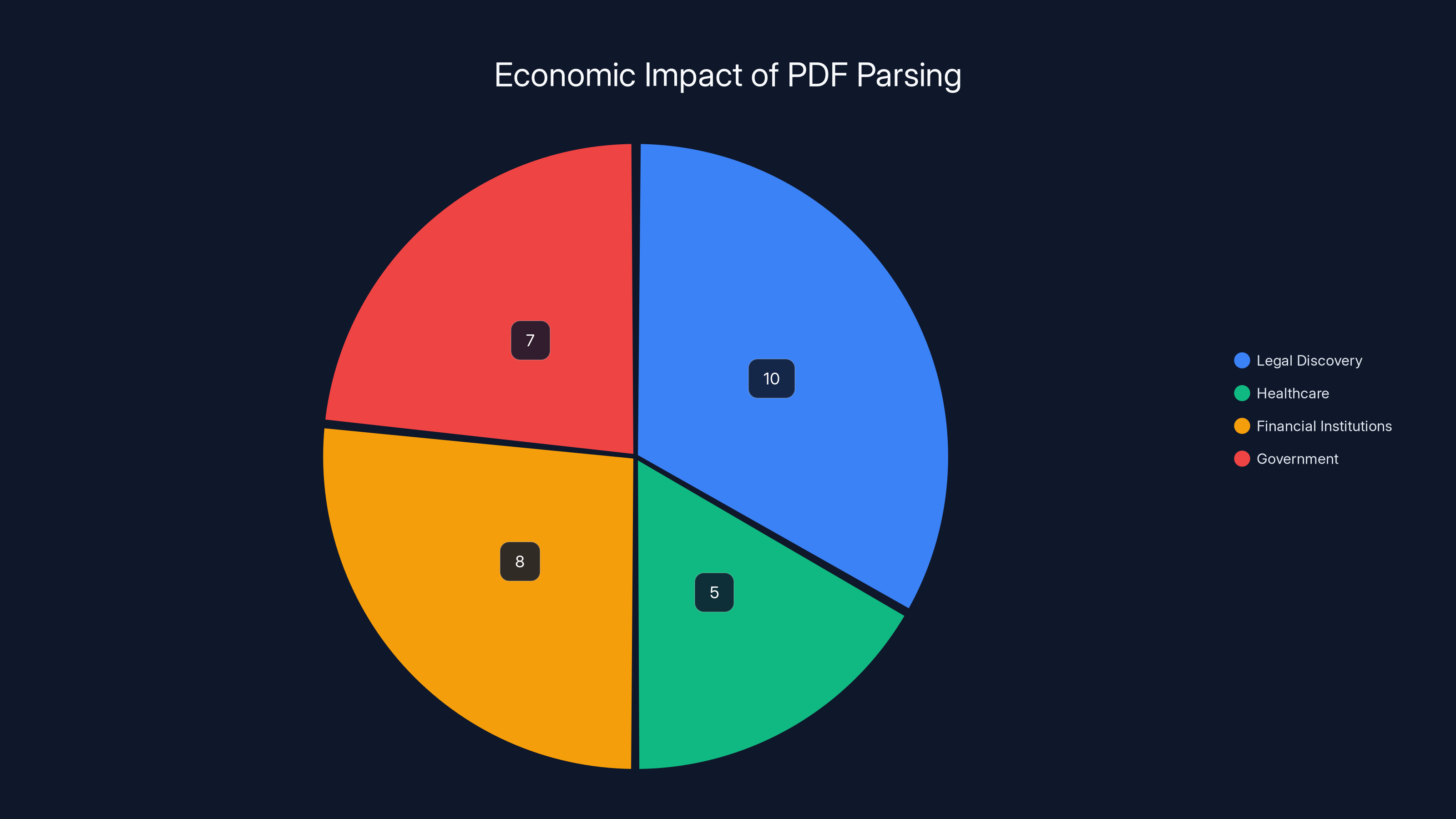
Estimated data: Improved PDF parsing could save billions across various sectors, with legal discovery and financial institutions seeing the largest potential savings.
Current State of the Art (2025)
So where do we stand in early 2025? What's actually possible right now?
Extracting text from clean PDFs: Works reliably. 95%+ accuracy for well-formatted documents created digitally.
Extracting text from scanned documents: Works with caveats. 70-85% accuracy for clean scans, drops significantly for degraded documents.
Preserving document structure (tables, headers, etc.): Works for standard formats. Fails for unusual layouts or mixed content types.
Understanding context and meaning: Unreliable. General-purpose AI models hallucinate and confuse context frequently.
Extracting from complex or multi-type documents: Still difficult. Documents that mix printed text, handwriting, images, and formatting confuse most systems.
Real-time processing of large volumes: Possible but expensive. Processing 3 million PDFs like the Epstein documents would cost significant money and time.
The practical advice for organizations: don't try to use general-purpose AI directly on PDFs. Use a specialized extraction tool, validate the output, and then apply general AI for reasoning and summarization. This is slower but actually works.
For research and development, the frontier is still pushing toward systems that can handle arbitrary documents with arbitrary formatting. But the rate of progress is slower than it was for other AI tasks, because the problem really is that hard.

The Future: Where PDF Parsing is Heading
I'm optimistic that PDF parsing will improve significantly in the next 2-3 years, but not because of breakthrough magic. Rather, because of three converging trends.
Better Multimodal Models
Models like GPT-4 Vision and Gemini 2.0 that can process both text and images are improving rapidly. These models can see a PDF page and understand its layout in ways text-based models can't. As vision capabilities improve, treating PDFs as images might become more practical.
The bottleneck right now is computational cost. Running a vision model on 3 million PDF pages would be expensive. But as models get more efficient and inference costs drop, this becomes more viable.
Better Document Parsing Standards
There's growing industry interest in creating better standards for representing documents in machine-readable formats. Rather than trying to reverse-engineer PDFs, organizations could generate documents in formats optimized for both human reading and machine processing.
This is slow to adoption (standards are always slow), but it's happening. Government agencies are gradually moving toward requiring digital document formats alongside PDFs.
Better Specialized Systems
As more companies build specialized PDF parsing tools, and as these tools are battle-tested on real-world documents, they'll get better. The market incentives are there. Organizations are clearly willing to pay for accurate PDF parsing.
We'll likely see continued fragmentation: specialized tools for legal documents, specialized tools for financial documents, specialized tools for healthcare documents. A universal solution is probably not coming, but a toolkit of specialized solutions is.

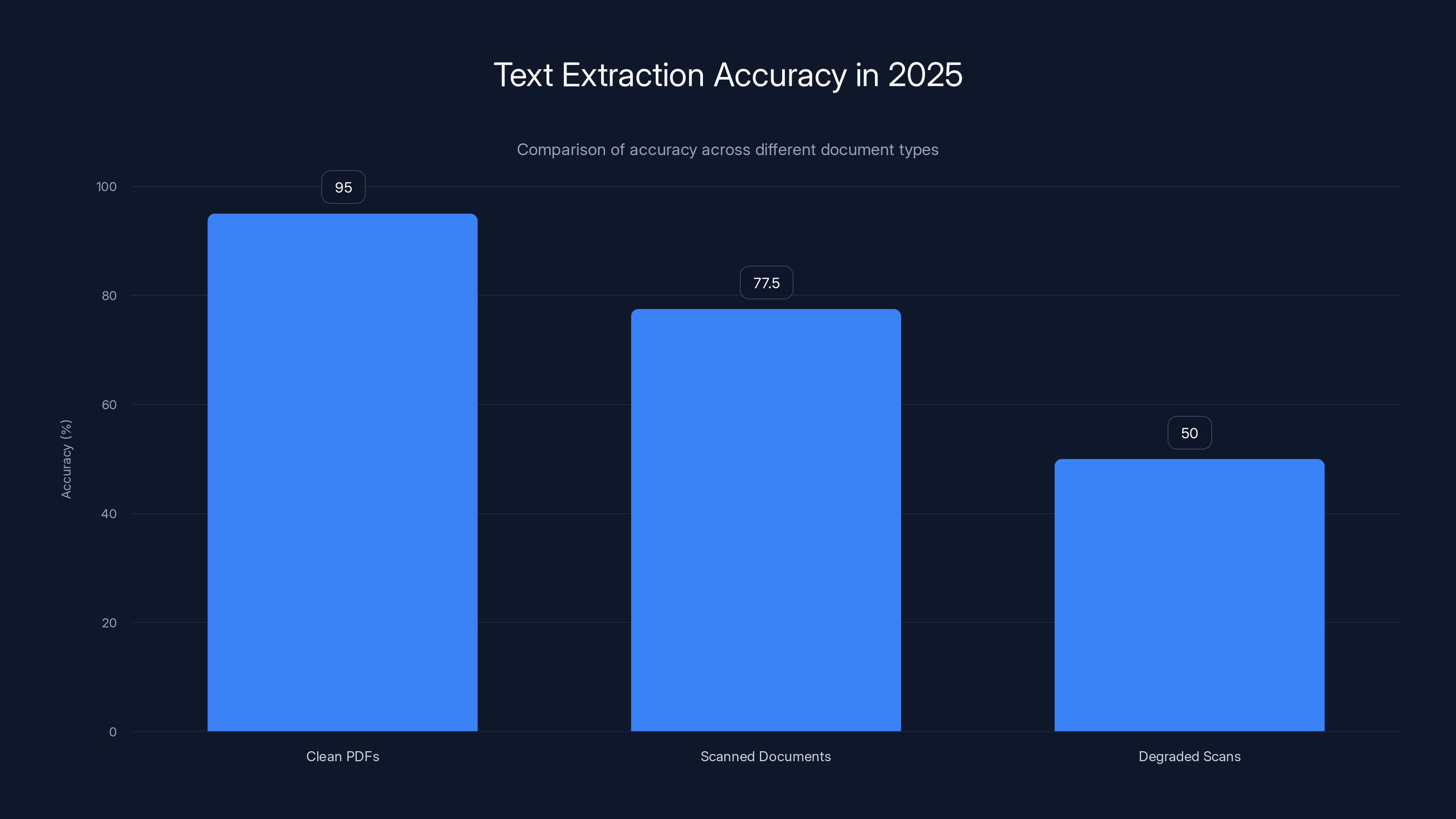
In 2025, text extraction from clean PDFs achieves over 95% accuracy, while accuracy drops significantly for scanned and degraded documents. Estimated data for degraded scans.
What You Should Do About PDF Parsing
If you're dealing with PDFs in your work, here's practical guidance:
For small volumes (< 100 documents): Don't use automated tools. Manual review is faster than debugging parsing errors. Seriously.
For medium volumes (100-10,000 documents): Use a specialized extraction tool. Reducto, Docling, or similar. These are worth the cost. Validate the output on a sample before scaling.
For large volumes (> 10,000 documents): You need a serious system. Either build it in-house if you have unique document types, or use a company like Reducto that offers APIs and can handle scale. Budget $10K-100K depending on complexity.
For integration with AI workflows: Treat PDF extraction as a separate step before feeding to language models. Don't expect general-purpose AI to handle PDFs reliably. Use extraction tools that output clean, structured data.
For critical applications (healthcare, legal, finance): Implement human review steps and error detection. Automated PDF parsing is a tool to speed up work, not to replace human judgment.
For research and development: Stay curious about how these tools work. PDF parsing is a genuine technical problem, and understanding it deeply is valuable.
FAQ
Why can't current AI models just read PDFs like humans do?
AI language models are optimized for processing text as sequences of tokens, but PDFs store content as visual instructions rather than organized text. When a model receives OCR'd text from a PDF, it loses spatial relationships and structural information that humans use to understand layout. Additionally, the OCR process itself introduces errors that compound downstream, leading models to hallucinate or misinterpret context they would easily understand in clean, structured text formats.
What's the difference between OCR and PDF parsing?
OCR (optical character recognition) converts images of text into machine-readable text. PDF parsing is the broader process of extracting meaningful information from a PDF, including text, tables, images, and structural elements. A PDF might contain both digital text and scanned images. OCR handles the scanned parts, while PDF parsing handles the entire process of understanding and extracting all content types while preserving structure. Poor OCR output can doom the entire PDF parsing process downstream.
Can I use Chat GPT or Claude to extract data from PDFs?
You can, but reliability is low. General-purpose models work best on clean, well-formatted PDFs and often hallucinate or misunderstand context on complex documents. For critical applications or large document volumes, specialized PDF parsing tools significantly outperform general-purpose models. If you use Chat GPT or Claude for PDF extraction, always validate the output against the source and expect to catch errors frequently.
What file format is better than PDF for AI processing?
HTML, Markdown, plain text, and JSON are all better for AI because they preserve document structure. For documents that need exact visual reproduction, alternatives like DOCX (Microsoft Word) or ODT preserve both content and formatting more accessibly. However, the reality is PDFs won't disappear, so the solution is to convert PDFs to better formats, then process those formats with AI.
How much does it cost to implement PDF parsing at scale?
Specialized tools like Runable and Reducto typically charge based on volume processed. For small volumes, expect
Are open-source PDF parsing tools reliable?
Open-source tools like Py PDF, pdfplumber, and Tesseract are useful for specific, narrow tasks but less reliable than specialized commercial tools for general PDF extraction. They work well for PDFs created digitally with clean formatting but struggle with scanned documents, complex layouts, and diverse formatting. Open-source tools are good for learning and for niche use cases, but production systems processing large volumes typically use commercial solutions.
How do specialized PDF parsing companies actually work better than general AI?
Specialized companies use architecture designed for documents: visual layout understanding, structure-aware extraction, specialized models for tables and images, and post-processing to preserve relationships between elements. General AI is optimized for language understanding, not document reverse-engineering. Specialized systems treat PDF parsing as a unique problem requiring unique solutions, while general AI is trying to force a document format into a text-processing framework.
What should I do if I have millions of legacy PDFs I need to process?
Start with a pilot: select a sample of representative documents (100-500), test extraction accuracy with a specialized tool, estimate error rates, and calculate the cost of manual review needed to achieve your accuracy requirements. Then make a decision: invest in better tools and processes upfront, or accept ongoing manual effort. Most organizations find that automated extraction with some human validation is cheaper than pure manual processing, but the business case depends on your specific documents and requirements.

Conclusion
The PDF parsing problem isn't going away anytime soon, and not because AI isn't smart enough. It's because PDFs are fundamentally misaligned with how AI works. They're visual documents designed for humans, and turning them into machine-readable information requires understanding something that the models were never optimized for: document structure.
This is a humbling reality in an industry that often claims AI can do anything. The world's most advanced models can't reliably read a document format that's been standard for 30 years. But it's also a reminder that narrow, specialized problems sometimes require specialized solutions. You can't just throw a general-purpose AI at everything and expect it to work.
The good news is that the problem is solvable. Companies are building specialized PDF extraction tools that work. Methods are improving. The market incentives are clear. In the next few years, we'll likely see PDF parsing improve significantly as these specialized tools mature and get deployed widely.
Until then, if you're dealing with PDFs at scale, treat PDF extraction as a separate problem that requires specialized tools. Don't expect general-purpose AI to handle it. And be skeptical of any vendor that claims their tool works perfectly on all PDFs. The ones being honest about the difficulty are usually the ones building better solutions.
The real lesson here isn't that AI is broken. It's that PDF is a bridge between human and machine worlds, and fully crossing it requires understanding both sides. The future of document processing belongs to tools that do exactly that: understand how humans organize documents and how machines need to process them.

Key Takeaways
- PDFs store content as visual instructions with coordinates, not hierarchical text like HTML, making them fundamentally misaligned with how AI language models process information
- OCR (optical character recognition) fails consistently on multi-column layouts, scanned documents, tables, and handwritten content, creating corrupted input that cascades downstream
- General-purpose AI models like ChatGPT and Claude hallucinate confidently when parsing PDFs because they don't understand document structure and can't detect when they're working with degraded input
- Specialized PDF parsing companies like Reducto use vision-based layout understanding and structure-aware extraction to achieve 80-96% accuracy, dramatically outperforming general AI on document-specific tasks
- The inability to reliably parse PDFs is costing organizations billions in legal discovery, healthcare records management, financial analysis, and government transparency—creating massive economic opportunity for specialized solutions
Related Articles
- Grok's Gaming Problem: Why xAI is Testing AI on Video Games [2025]
- Google Gemini 3.1 Pro: AI Reasoning Power Doubles [2025]
- Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work [2025]
- AI Coding Tools and Open Source: The Hidden Costs [2025]
- Google I/O 2026: 5 Game-Changing Announcements to Expect [2025]
- Flapping Airplanes on Radical AI: The Data Efficiency Revolution [2025]

