![Flapping Airplanes on Radical AI: The Data Efficiency Revolution [2025]](https://tryrunable.com/blog/flapping-airplanes-on-radical-ai-the-data-efficiency-revolut/image-1-1771252818345.jpg)
Flapping Airplanes on Radical AI: The Data Efficiency Revolution [2025]
There's a quiet revolution happening in AI labs right now, and it has nothing to do with making models bigger or throwing more compute at the problem. Instead, a new generation of researchers is asking a fundamentally different question: what if we trained AI systems to learn like humans do instead of like current transformers?
Flapping Airplanes is at the center of this shift. With $180 million in seed funding and three young founders who aren't afraid to challenge orthodoxy, the lab is betting big that data efficiency—not raw scale—is the next frontier in AI development. This is important because it represents a philosophical departure from the playbook that's defined AI for the last five years.
When you talk to the founding team—brothers Ben and Asher Spector, and Aidan Smith (who comes from Neuralink)—what strikes you immediately is how thoughtfully they've framed the problem. They're not trying to out-Open AI Open AI or build a bigger model than what exists. They're asking: what if there's an entirely different set of tradeoffs worth exploring?
This article dives deep into what Flapping Airplanes is actually building, why data efficiency matters more than people realize, and what the broader implications are for AI development in the next decade. If you care about where AI is actually headed—not just what the headlines say—this is worth your time.
TL; DR
- Data efficiency is the real bottleneck: Current frontier models train on humanity's entire recorded knowledge, while humans learn orders of magnitude more efficiently with vastly less data
- Neuromorphic inspiration without neuromorphic constraints: The Flapping Airplanes team draws lessons from how brains work but isn't trying to replicate them exactly—they're building something fundamentally different
- New tradeoffs enable new applications: Ultra-efficient models could unlock AI in robotics, scientific discovery, and enterprise applications where data scarcity is the limiting factor
- Young, creative teams can see differently: The founders believe that inexperienced teams can approach foundational problems fresh, unburdened by years of transformer-centric thinking
- The next 5 years will test this bet: With $180M in runway, Flapping Airplanes has resources to either prove data efficiency is the key unlock or demonstrate that scaling remains dominant

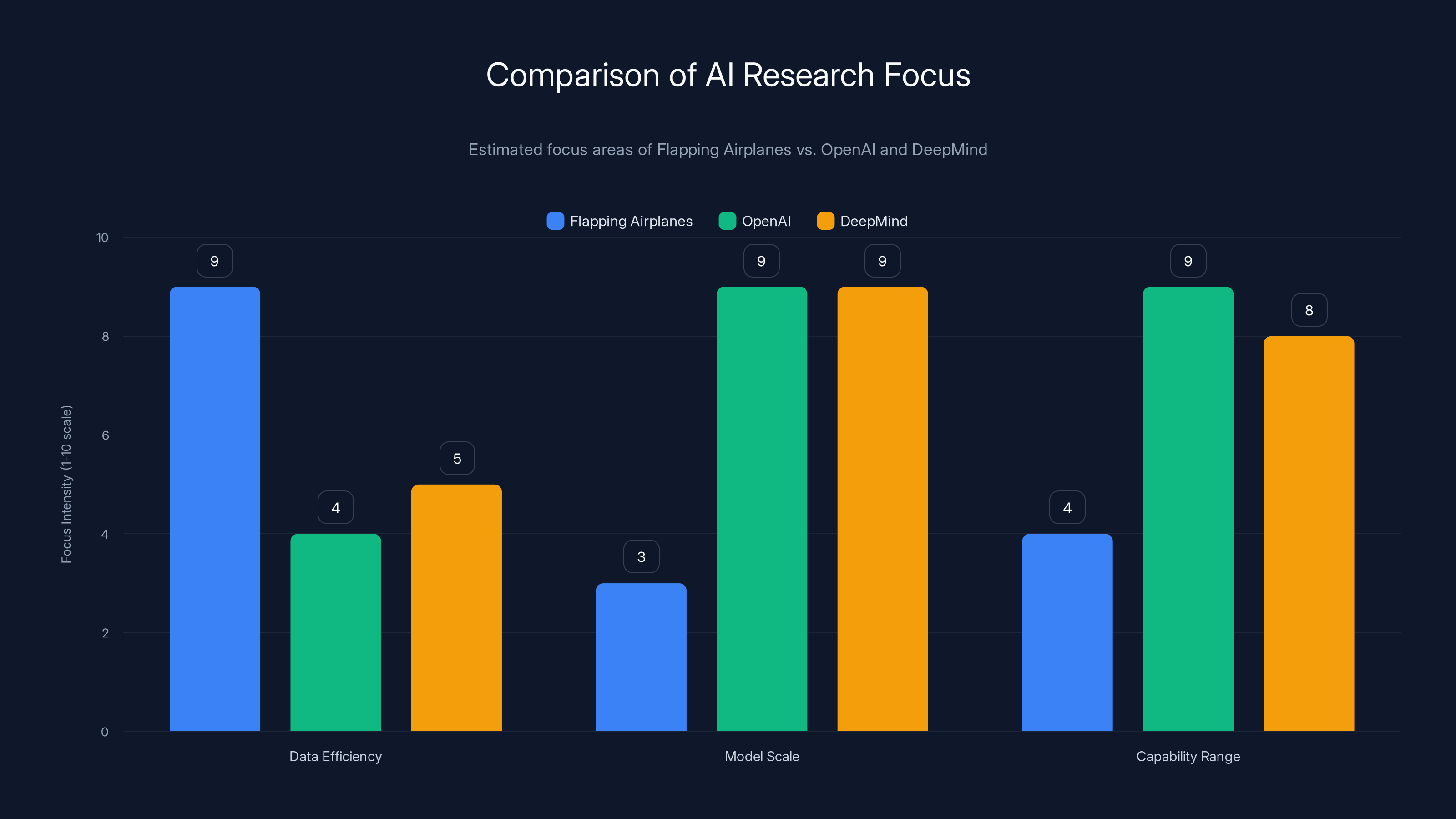
Flapping Airplanes prioritizes data efficiency over model scale and capability range, unlike OpenAI and DeepMind which focus more on scale and capability. Estimated data based on described focus areas.
Why Now: The Timing of a New Lab in Crowded AI
The natural response to Flapping Airplanes' launch was skepticism. Why start a new foundation model company when Open AI, Deep Mind, Anthropic, and others have already invested tens of billions of dollars in scaling approaches? The compute barriers are extreme. The talent pool is finite. The competition seems impossible.
Ben Spector's answer is disarmingly simple: there's just a lot more to do.
The advances in AI over the past five to ten years have been objectively spectacular. These tools work. Engineers use them daily. But the founders looked at this progress and asked a critical follow-up question: is this the entire universe of what needs to happen?
Their answer was no—and more specifically, they identified what they believe is the bottleneck everyone else is overlooking.
The Data Efficiency Gap: The Problem Everyone's Missing
Here's the core insight: current frontier models train on essentially the sum totality of human knowledge available online. And yet humans—actual human brains—make do with vastly, incomparably less data.
Think about what a child learns in five years versus what a language model needs to see to predict text competently. A child learns language, physics, social norms, problem-solving, and countless other skills from a combination of direct experience, observation, and interaction. An LLM needs to ingest billions of tokens of human-generated text.
There's a massive efficiency gap between human learning and machine learning. And that gap isn't just intellectually interesting—it's commercially critical.
Why does this matter beyond academic interest? Because data efficiency directly translates to economic value. If you can build a system that's orders of magnitude more data-efficient than current approaches, you can deploy AI in entirely new domains where training data is scarce or prohibitively expensive to generate.
The Concentrated Bet: Three Specific Theses
Flapping Airplanes' strategy isn't vague. The team is making three very specific bets.
First, they're betting that the data efficiency problem is actually important and solvable—that it's a real direction where meaningful progress can happen, not just a research dead-end.
Second, they're betting this will be commercially valuable. They believe data efficiency improvements will make AI systems substantially easier to deploy in the real economy, creating value that justifies the research investment.
Third, and this is the part that distinguishes them: they're betting that a young, creative, even somewhat inexperienced team is the right fit to tackle these problems. They're explicitly not trying to poach Open AI's entire technical staff. They're building a new research culture.
This last bet is fascinating because it cuts against conventional wisdom in deep tech. Usually, the narrative goes: hire the most experienced people, give them massive resources, and trust that experience will guide you. Flapping Airplanes is saying something different: sometimes the most experienced people are so embedded in existing approaches that they can't see alternatives. Fresh eyes can matter.
Aidan Smith, who comes from Neuralink, brings credibility in neuroscience and brain-computer interfaces. But he's not a 20-year veteran of transformer architecture. Ben and Asher Spector are young researchers comfortable thinking at fundamental levels. This composition matters.
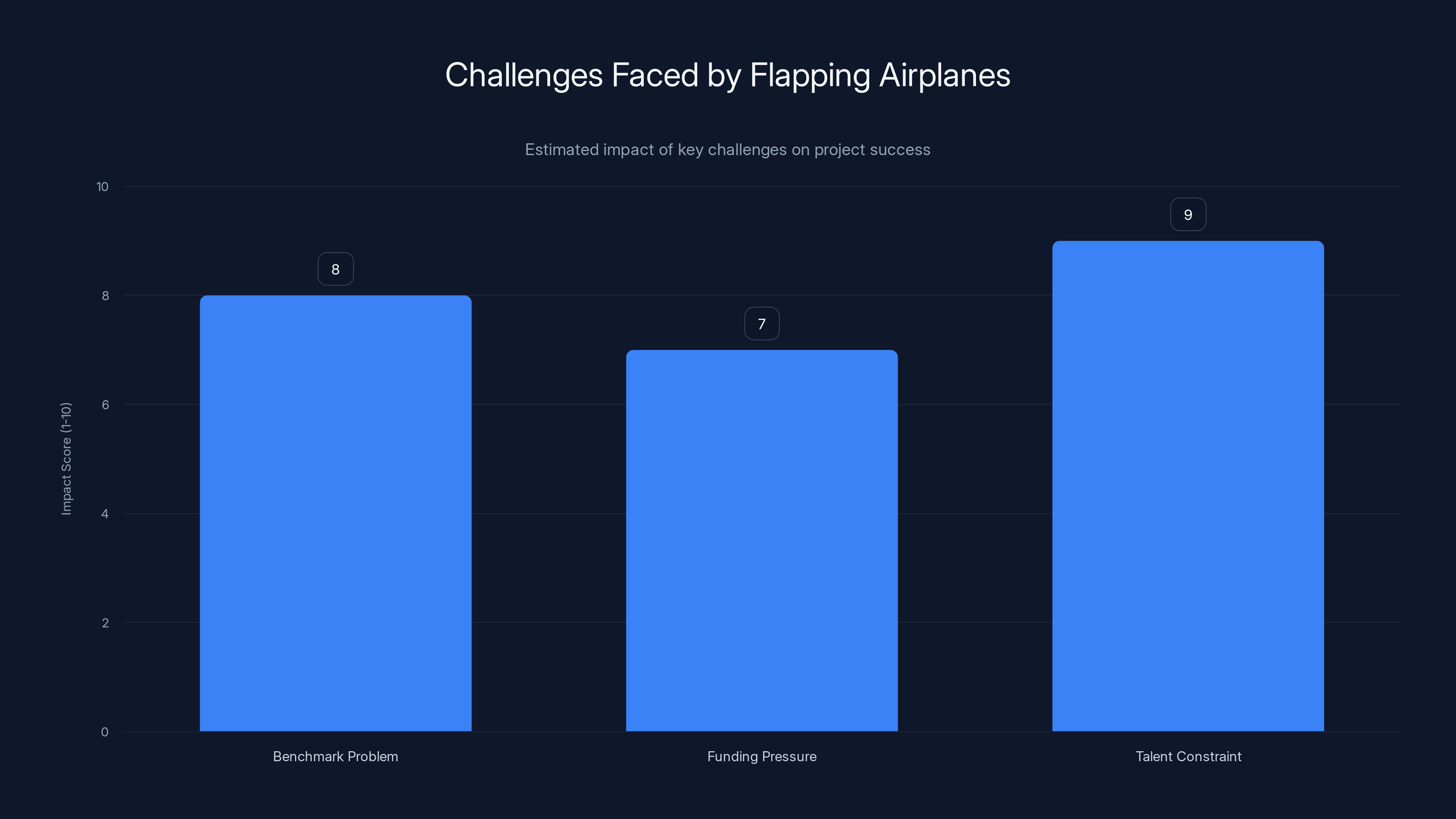
The Talent Constraint poses the greatest challenge with an estimated impact score of 9, followed by the Benchmark Problem and Funding Pressure. (Estimated data)
The Fundamental Problem with Current AI: Different Problems, Different Tradeoffs
Before diving into what Flapping Airplanes is building, it's worth understanding what they see as broken about current approaches.
Aidan frames it clearly: if you look at how the human mind learns versus how transformers learn, they're fundamentally different. Not just in details—in core algorithms.
What Transformers Do Incredibly Well (And Their Cost)
Large language models are genuinely impressive at certain things. They have an almost magical ability to memorize and draw on vast breadth of knowledge. Ask a modern LLM a question about obscure historical facts, and it will surprise you. Show it a concept it never explicitly trained on and it can often reason through the solution.
This breadth comes directly from scale. Transformer architecture combined with massive datasets creates systems that can hold and access enormous amounts of learned patterns.
But this strength comes with a major cost: they're terrible at learning new skills quickly. Adapt a pre-trained model to a new task, and you typically need rivers of data. Fine-tuning on a few examples often fails. The model needs to be shown the pattern hundreds or thousands of times before it incorporates the new behavior.
Humans do the opposite. A person can learn a new skill from a handful of examples. Show someone five chess positions with expert annotations and they can start understanding strategy. Show an LLM five chess positions and it will produce plausible-sounding text about chess without actually understanding the game.
This isn't a flaw in transformer architecture per se. It's a tradeoff. You get breadth and pattern-matching ability. You lose sample efficiency and learning speed.
The Neuroscience Perspective: The Brain as Existence Proof
Aidan's perspective on neuroscience is pragmatic rather than fundamentalist. He doesn't believe the goal is to replicate the brain—that's both impractical and probably unnecessary. Instead, he sees the brain as an existence proof that different algorithms are possible.
The brain operates under wild constraints. Neurons fire action potentials in about a millisecond. In that same millisecond, a modern GPU can perform billions of operations. Yet the brain somehow does something we still can't replicate at scale.
This means there must be algorithms fundamentally different from backpropagation and gradient descent that can solve intelligence problems. The brain clearly isn't using the mathematical machinery that powers modern deep learning, yet it learns, reasons, and adapts.
What are those alternative algorithms? That's the central question Flapping Airplanes is trying to answer.
The Metaphor: Why It's Called Flapping Airplanes
Ben Spector explains the name with a precise metaphor that reveals the team's philosophy about AI development.
Think of current large language models—the frontier models like GPT-4, Claude, Gemini—as Boeing 787s. They're massive, complicated, heavily engineered machines that require enormous infrastructure to operate. They're powerful for specific tasks, but they're not designed for flexibility or efficiency.
Flapping Airplanes isn't trying to build birds. That's the trap of naive biomimicry—trying to replicate biology exactly. Birds are impressively efficient, but the goal isn't to literally copy their physics. The goal is to find what's learnable from the observation that completely different design principles can achieve flight.
What Flapping Airplanes is actually building is something like a flapping airplane. Not a bird. Not a 787. Something that uses principles (some inspired by biological systems, some perhaps entirely novel) that are radically different from current approaches while still being actually implementable and practical.
This framing is important because it explains why the team isn't worried about looking "wrong" in the short term. If you're pursuing genuinely different approaches, you'll necessarily look wrong compared to incumbents optimized for the current setup. That's not a bug. That's the point.
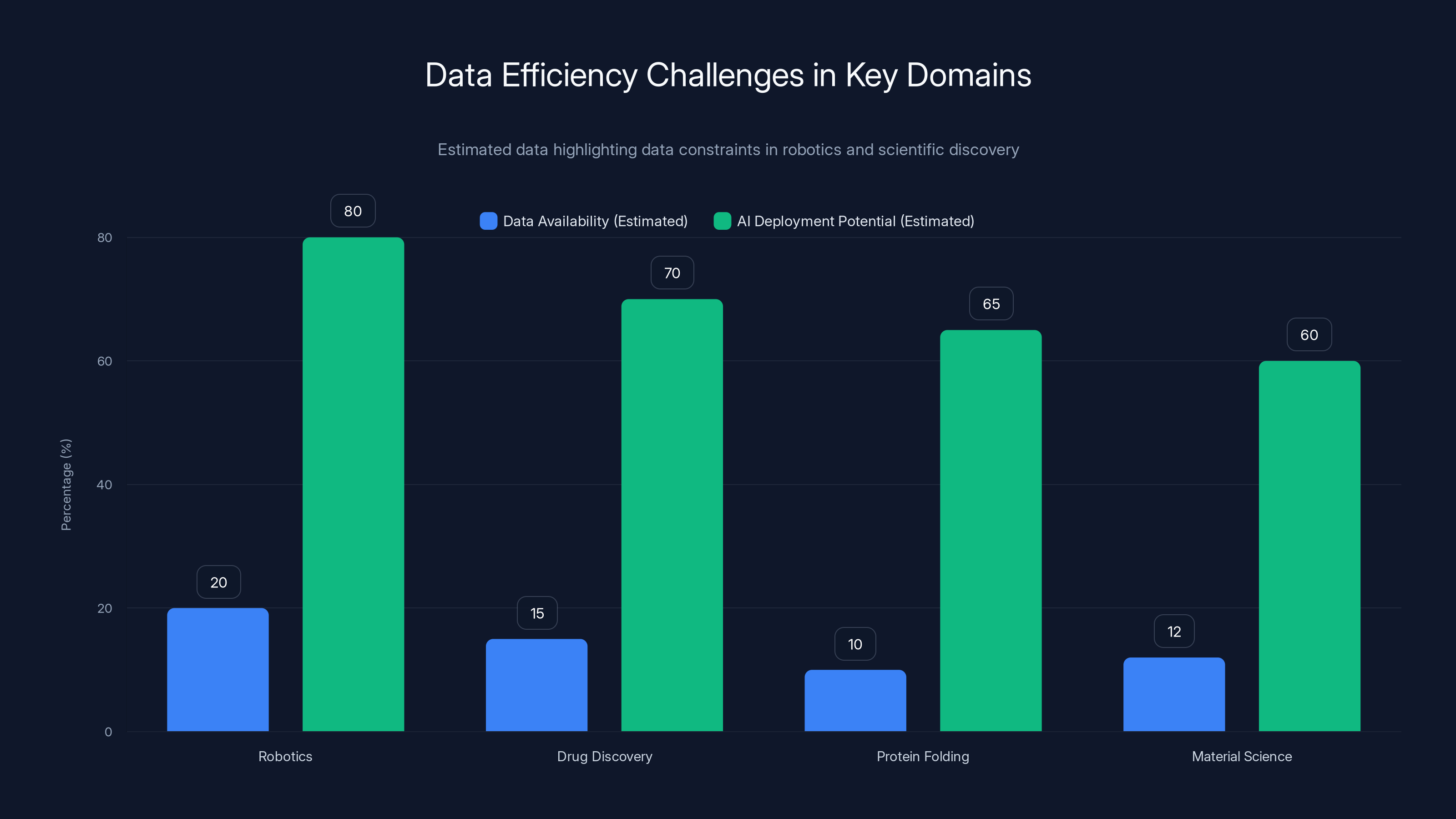
Robotics and scientific discovery domains face significant data constraints, limiting AI deployment potential. Estimated data shows robotics has higher AI deployment potential despite data scarcity.
Data Efficiency in Practice: Where It Matters Most
Data efficiency might sound like an academic concern, but there are concrete domains where it's the critical bottleneck preventing AI deployment entirely.
Robotics: The Data Scarcity Problem at Scale
Robotics is the clearest example. A humanoid robot needs to learn to manipulate objects, navigate environments, and respond to instructions. This requires enormous amounts of real-world data from physical systems.
You can't easily scale training by just running more simulations. Sim-to-real transfer is still incredibly hard. A robot trained entirely in simulation often fails in the real world because the physics don't transfer perfectly. So you need real-world training data.
But generating real-world robot training data is expensive. You need actual hardware, actual operations, actual ground truth labeling. You can't generate synthetic data at internet scale like you can with images or text.
Current approaches try to make up for limited data by using pre-trained models and fine-tuning. But this still requires scaling the pre-training, which requires enormous compute and data in non-robotics domains. If you could build systems that learn robotics tasks with dramatically less data, you could deploy robots far more cheaply and quickly.
Scientific Discovery: The Data Constraint as a Feature
Scientific discovery domains face similar constraints but for different reasons. In drug discovery, protein folding, material science, or fundamental physics, the data is limited by the rate at which you can run experiments.
You can't generate 1 billion labeled examples of protein structures or drug efficacy. You can run hundreds or thousands of experiments, but scaling to internet-scale data is fundamentally impossible. Yet these domains could benefit enormously from AI assistance—predicting which compounds to test, suggesting experimental designs, interpreting results.
AI systems optimized purely for scale and breadth of training data are a poor fit for these problems. An ultra-efficient model trained on available experimental data could be far more useful than a massive model fine-tuned on synthetic or proxy data.
Enterprise Applications: The Hidden Data Efficiency Opportunity
At a smaller scale, enterprise applications often have modest amounts of proprietary data—customer information, internal processes, domain-specific patterns—that are valuable but not internet-scale.
A company with 50,000 customer support tickets wants to automate routing and response suggestions. They have good data for their domain, but it's not remotely enough to train a foundation model from scratch. Current approaches require either expensive data annotation for fine-tuning or accepting reduced performance.
If models could be built that learn effectively from 50,000 examples instead of 50 million, the economics of enterprise AI deployment would shift dramatically. You wouldn't need to rely on massive pre-trained models for every application. You could build task-specific systems efficiently.
The Research Approach: Different Problems Require Different Methods
What's interesting about Flapping Airplanes' positioning is that they're explicitly not trying to solve the same problems as Open AI or Deep Mike. They're not trying to build the next GPT. They're asking different questions, which means they're probably measuring success differently.
The Frontier vs. The Frontier Differently
When Open AI, Deep Mind, or Anthropic talk about frontier models, they mean state-of-the-art performance on benchmark tests. Can a system write code? Reason through complex problems? Pass academic exams? These benchmarks have become the de facto measure of progress.
Flapping Airplanes is asking: what if you constrained the model to learn from radically less data? How well could it perform? Could you get to 80% of frontier performance using 1% of the training data?
If yes, that's a massive win—not on traditional benchmarks, but on practical deployment and economics.
If no, the failure is still interesting because it tells you something fundamental about intelligence and data requirements.
This framing means Flapping Airplanes isn't really in competition with Open AI for the same measure of success. They're playing a different game with different rules. This actually makes it harder to dismiss them because they're not trying to beat the incumbents at what the incumbents optimize for.
Neuromorphic Inspiration Without Neuromorphic Constraints
One area where the team's nuance really shows is how they think about neuroscience inspiration.
There's a long history of neuromorphic computing—actually building AI systems designed to mimic biological neural structure. The problem is that brains operate under constraints (energy efficiency, real-time response, evolutionary history) that don't necessarily make sense for artificial systems with different deployment requirements.
Aidan's framing is much more pragmatic: the brain is interesting because it proves alternative algorithms exist. But you probably don't want to be constrained by trying to perfectly replicate biological systems.
So Flapping Airplanes is likely to draw inspiration from neuroscience insights—about how sparse activation works, about learning rules beyond backpropagation, about meta-learning and transfer—without necessarily building something you'd call neuromorphic.
The goal is probably something more like: identify principles from neuroscience that could be adapted to artificial systems, then explore whether those principles could lead to more efficient learning without accepting all the constraints biology imposes.
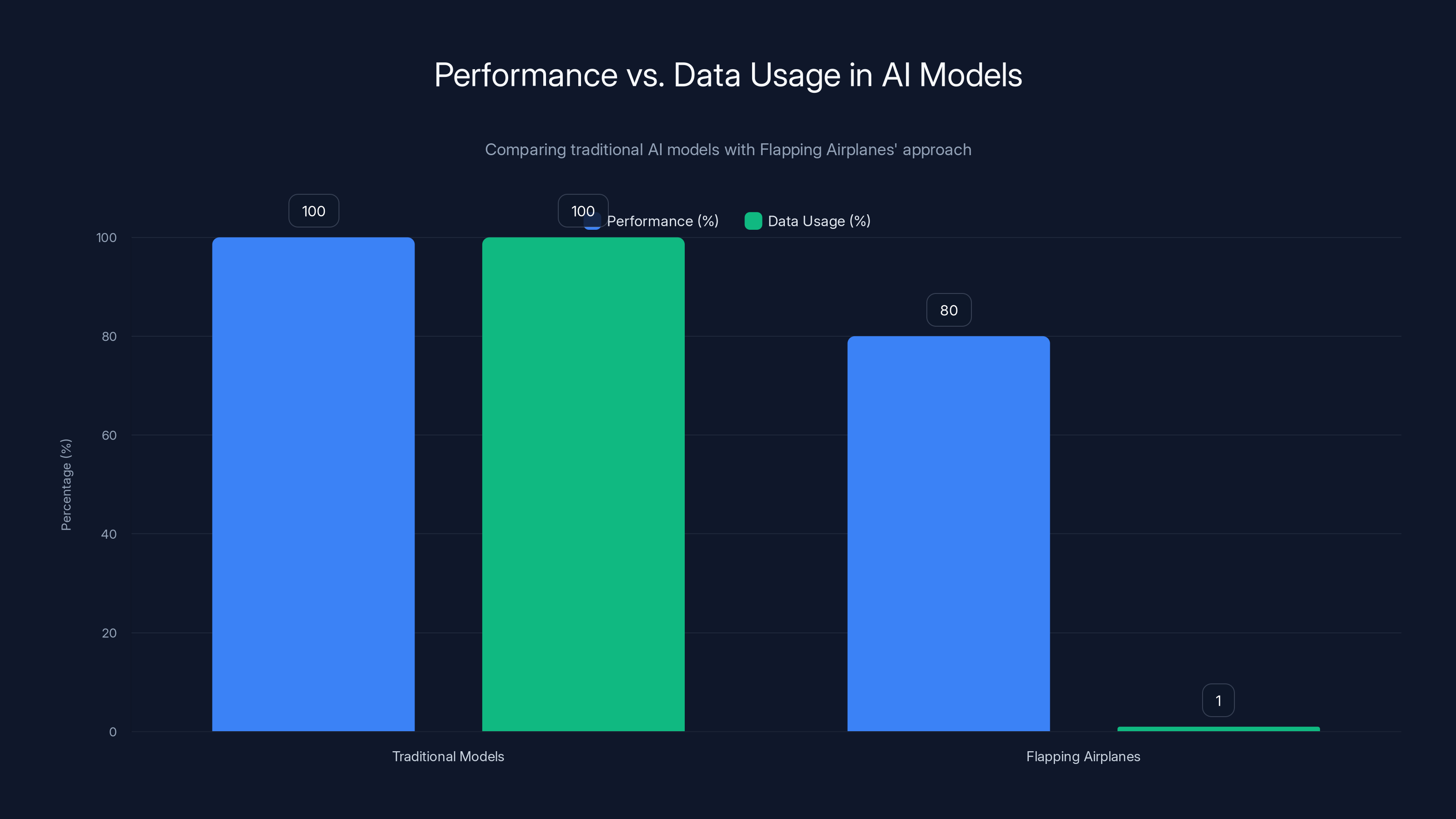
Flapping Airplanes aims to achieve 80% of traditional AI performance using only 1% of the data, highlighting a focus on efficiency over traditional benchmarks. Estimated data.
The Competitive Landscape: A Subtle Positioning
Flapping Airplanes' position relative to other AI labs and companies is genuinely interesting because it's deliberately orthogonal.
Not Fighting Open AI: Complementary Bets
The team is clear they don't see themselves as competing with Open AI, Deep Mind, or other large labs. This isn't false humility. It's a strategic observation that Flapping Airplanes is making different bets.
Open AI is optimizing for frontier capability and broad knowledge. They want to build systems that work well across the widest possible range of tasks. This drives scaling approaches.
Flapping Airplanes is optimizing for data efficiency. They want to build systems that work brilliantly in data-constrained regimes. This drives entirely different architectural and algorithmic approaches.
These aren't mutually exclusive. You could eventually combine insights from both approaches. But in the near term, they're exploring genuinely different territory.
Where the Pressure Points Are
That said, if Flapping Airplanes succeeds at building ultra-data-efficient models, there are some areas where this directly challenges incumbent approaches.
Custom model training: if you can build domain-specific models efficiently from modest amounts of data, that reduces the need to pay for access to massive pre-trained models via API.
Privacy-sensitive applications: in domains where you can't easily share training data, efficient learning from private data becomes suddenly valuable.
Edge deployment: models that learn from less data can be smaller, which makes edge deployment (on phones, devices, embedded systems) more feasible.
None of these are existential threats to Open AI's business model tomorrow. But they represent areas where the current frontier model paradigm is suboptimal.

The Founding Team: Why Youth and Inexperience Matter Here
The composition of Flapping Airplanes' founding team reveals something about why this moment is right for the company.
Ben and Asher Spector are brothers—a structure that implies deep collaboration and shared intellectual DNA. Aidan Smith comes from Neuralink, which is notable because it's an organization that openly questions conventional wisdom about how to approach complex systems.
None of them are veterans of Open AI or Deep Mind with decades of transformer experience. This is presented as a feature, not a bug.
The Benefit of Not Knowing Better
There's genuine research on the benefit of "naive" approaches to solving established problems. When you've spent years solving a class of problems one way, your thinking gets constrained. You start treating certain approaches as foundational because they've always worked.
A team that hasn't invested five years in transformer architecture might be faster to consider alternatives that an expert would dismiss as unpromising.
This doesn't mean inexperience is universally better. It means for this specific problem—finding alternative approaches to learning algorithms—the absence of deep transformer expertise might actually be an advantage.
Building a Research Culture
What's also interesting is that the team is explicitly building a new research culture rather than trying to replicate the playbook of existing labs.
Open AI and Deep Mind have specific ways of organizing research, recruiting talent, and evaluating progress. These approaches have worked. But they're optimized for the problems those labs have been solving.
Flapping Airplanes is starting from scratch on research culture, which means they can potentially make choices better suited to exploring data efficiency specifically—different metrics, different collaboration structures, different hiring criteria.
This is speculative, but it suggests the team understands they're not just doing different research. They're probably organizing research differently.
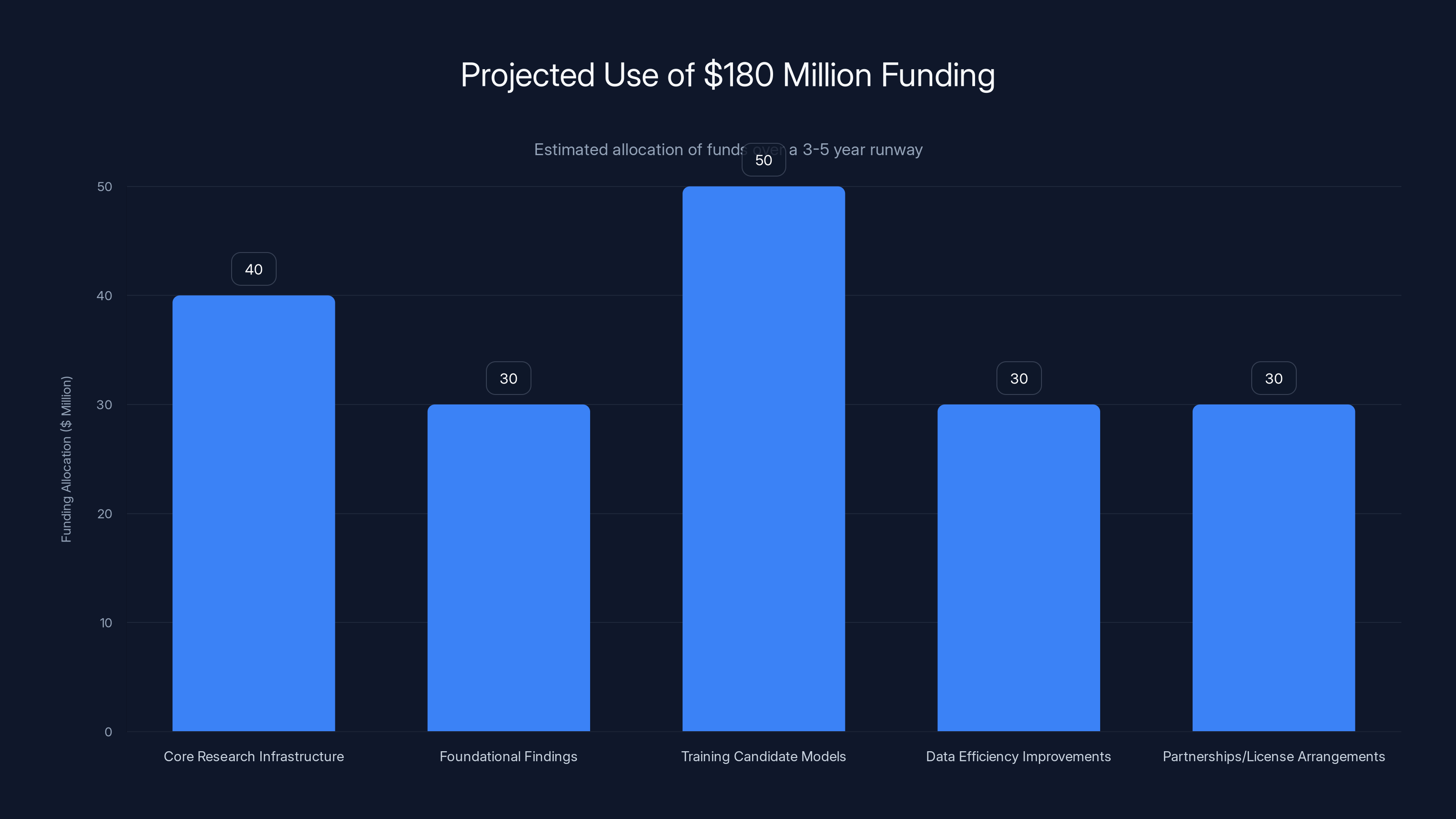
Estimated data suggests that Flapping Airplanes will allocate their $180 million funding across key research and development areas over a 3-5 year period, focusing heavily on training models and building research infrastructure.
The $180 Million Question: How Much Runway Do You Need?
Flapping Airplanes closed seed funding of $180 million. This is substantial and raises an obvious question: is that enough?
The Economics of AI Research
The compute costs for training frontier models have increased exponentially. Open AI's latest training runs cost tens of millions. Large-scale experiments at Deep Mind or Meta cost similarly.
But Flapping Airplanes probably doesn't need to match this spending dollar-for-dollar because they're not trying to build the same kind of model.
If your hypothesis is that you can achieve compelling results with far less data, you might also be able to achieve them with far less compute. The two constraints are related but not identical.
A model trained on 10 billion tokens instead of 1 trillion tokens needs less compute, even if the per-token compute remains similar.
The Runway Calculus
With $180 million, if the team is spending conservatively on compute while maintaining a growing research team, they have probably 3-5 years of runway before needing to demonstrate commercial viability or raise more funding.
That's enough time to:
- Build core research infrastructure
- Publish foundational findings
- Train multiple candidate models with different architectural approaches
- Generate preliminary evidence that data efficiency improvements are achievable
- Begin partnerships or licensing arrangements
It's probably not enough time to:
- Build a consumer-facing product
- Achieve clear commercial dominance in any single domain
- Demonstrate that they've fundamentally changed the AI landscape
The funding level signals confidence from investors but also sets real time constraints. This isn't a "research forever" lab. It's a company that needs to demonstrate something meaningful within 3-5 years.
The Broader Implications: What Success Would Mean
If Flapping Airplanes succeeds—if they really do figure out how to build ultra-data-efficient AI systems—the implications extend far beyond their company.
A Shift in AI Strategy Across the Industry
Currently, the playbook for building capable AI systems is: get compute, get data, scale everything up. This works but has constraints.
If data efficiency becomes the frontier instead of scale, the entire industry's research priorities could shift. You'd see investment flowing toward different kinds of research, different kinds of talent, different kinds of companies.
Regulation might shift too. If you could train capable AI models on smaller datasets, privacy concerns and data-sourcing ethics could become more tractable.
New Markets and Applications Become Viable
Domains currently impossible to deploy AI in become viable. Robotics companies could train robots more efficiently. Scientific labs could get AI assistance suited to their specific needs. Enterprises could build task-specific systems cost-effectively.
This isn't revolutionary change in the sense of superintelligence or AGI. It's incremental change in terms of economic structure: AI deployment becomes cheaper, faster, and more flexible for a broader range of organizations.
The Questions That Get Asked
Successful research doesn't just provide answers. It changes which questions get asked.
If Flapping Airplanes demonstrates that current scaling approaches are hitting diminishing returns and that data efficiency is more important, the field's research direction changes. More labs start investigating alternative learning algorithms. More papers get published on sample efficiency. Benchmark design potentially shifts.
Even if Flapping Airplanes itself doesn't become the biggest AI company, they might reshape what the field is investigating for the next decade.
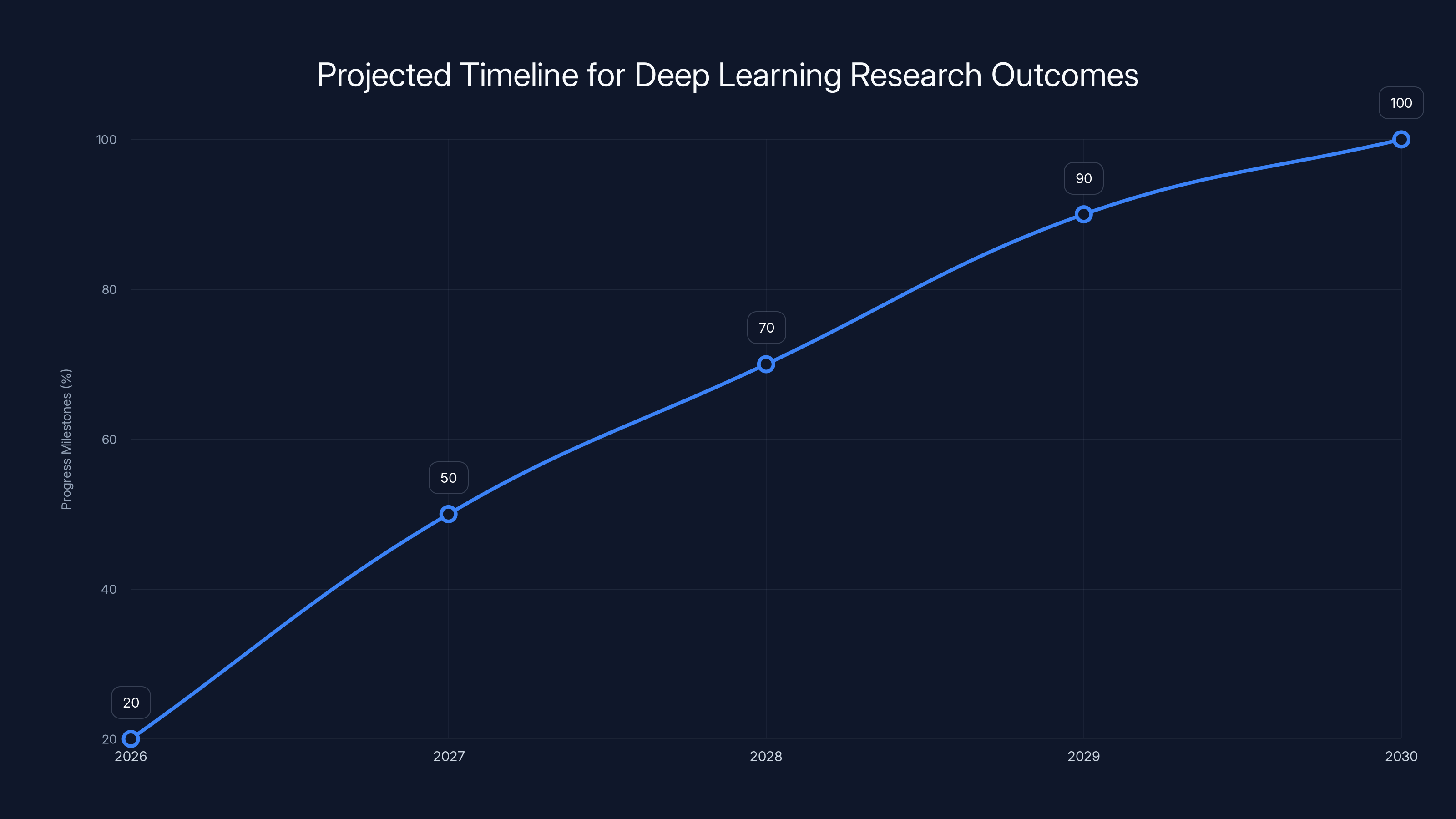
Estimated data shows key milestones in deep learning research, with significant progress expected by Year 3 (2028).
Challenges Ahead: The Hardest Parts
For all the promise of this approach, there are significant challenges the team will face.
The Benchmark Problem
Current AI benchmarks are optimized for measuring frontier capability and breadth of knowledge. A model that's incredibly data-efficient but performs at 85% of frontier levels on traditional benchmarks might actually represent more impressive research, but it looks worse on the metrics everyone currently cares about.
Flapping Airplanes will need to either convince the field to value different metrics or achieve such clear practical advantages that different metrics become obviously necessary.
Neither is guaranteed. Scientific fields are conservative about what counts as progress.
The Funding Pressure
With $180 million in seed funding, there's implicit pressure to demonstrate value within a specific timeframe. This might push the team toward publishable results over deeper exploration, or toward demonstrating commercial applications over foundational research.
Fundamental questions about learning algorithms take time to answer. The funding timeline might not align perfectly with research timelines.
The Talent Constraint
Build a new lab requires recruiting top researchers away from established organizations. Flapping Airplanes has funding, but Open AI, Deep Mind, and Anthropic have brand, proven success, and often higher compensation packages.
The team's advantage here is novelty and autonomy. But attracting world-class talent to explore unproven approaches is harder than attracting talent to labs with demonstrated success.

The Timelines: When Should We Expect Results?
This is speculative, but based on research timelines in deep learning, here's a plausible progression.
Year 1 (2026): Infrastructure building, team assembly, preliminary experiments on alternative learning rules and data efficiency techniques.
Year 2 (2027): First significant findings published, proof-of-concept models demonstrating 50-100x better data efficiency on specific tasks, initial partnerships with robotics or scientific discovery organizations.
Year 3 (2028): Broader architectural approaches validated across multiple domains, early commercial deployment in robotics or enterprise applications, potential Series A fundraising.
Year 4-5 (2029-2030): Scaling to show whether data-efficient approaches can eventually match frontier performance with dramatically less training data, clearer market positioning.
These timelines are guesses based on how long similar research programs take. Actual progress could be faster or slower depending on whether their initial hypotheses are correct.
The key threshold is probably Year 2-3: can they demonstrate credible evidence that their approach is fundamentally different and better at something meaningful?
How This Connects to Broader AI Development Trends
Flapping Airplanes exists within a moment where several trends are converging.
First, there's growing skepticism about pure scaling approaches. As models get larger, the cost curve is flattening. Getting to 2x better performance might require 10x more compute, which becomes uneconomical.
Second, there's renewed interest in biological inspiration and alternative learning paradigms, driven partly by limitations of current approaches becoming more obvious.
Third, there's capital availability for AI research at an unprecedented scale, which means high-risk bets become fundable.
Flapping Airplanes sits at the intersection of these trends. They're funding research that most major labs deprioritize (because it requires admitting current approaches might be suboptimal). They're exploring problems that are increasingly urgent (scaling economics). And they're doing it with a team that thinks differently.

The Philosophical Stakes: More Than Just Better Models
What makes Flapping Airplanes interesting isn't just the technical research. It's what success or failure would tell us about intelligence, learning, and the path to AI capability.
What Current Success Proves
The success of transformer-based scaling has created a narrative: intelligence emerges from scale plus data plus compute. You get smarter systems by making them larger and feeding them more information.
This narrative has been remarkably productive. It's generated incredible capabilities. But it's also become somewhat dogmatic—assumed rather than questioned.
What Different Success Would Prove
If Flapping Airplanes or similar efforts demonstrate that radically different learning algorithms can be far more data-efficient without sacrificing capability, that proves something different.
It would prove that the current path to AI isn't the only path. That intelligence doesn't necessarily require the scale we've been assuming. That there are algorithmic insights we've missed by focusing on scale.
This might sound abstract, but it has real implications for how we think about AI development, safety, and the future of the field.
The Uncertainty is the Point
Honestly, it's unclear whether Flapping Airplanes will succeed. Their bet might prove correct, or it might demonstrate that scaling is actually the right approach and data efficiency improvements have limited returns.
Both outcomes would be valuable. The field needs to explore alternative approaches to develop informed positions about what actually matters for building capable AI systems.
Practical Takeaways for AI Practitioners and Organizations
Even if you're not directly involved in foundation model research, Flapping Airplanes' work has implications worth considering.
For AI Researchers
If you're doing research in machine learning, the existence of serious resources being directed toward data efficiency and alternative learning approaches suggests this is a worthwhile direction to explore. It's not a niche problem—it's becoming mainstream.
For Organizations Building AI Products
If you're building AI applications, pay attention to data efficiency in your own systems. As capabilities level off for large models, efficiency becomes a legitimate competitive advantage. Companies optimizing for efficient learning might outcompete those that just scale existing approaches.
For Enterprises Considering AI Deployment
If you have proprietary data but limited labeled data for training, the emergence of more data-efficient approaches is directly relevant to your planning. In 3-5 years, your options for building custom AI systems might expand significantly.
For Venture Capitalists and Investors
Flapping Airplanes' funding represents a bet that there are alternative paths to AI capability creation beyond pure scaling. This is a strategic bet on what becomes valuable over a 5-10 year horizon. Whether or not Flapping Airplanes specifically succeeds, the category of efficiency-focused AI research probably represents real opportunity.
Looking Ahead: The Next Phase of AI Development
The AI field is at an inflection point. The narrative that scaling is everything has proven incredibly productive, but it's also showing limits. Training costs are becoming prohibitive. Data quality matters more than scale alone. New approaches are being funded.
Flapping Airplanes is one expression of this shift. There will be others—other labs, other companies, other research directions exploring whether there are alternatives to the current path.
The outcome of these explorations will shape AI development for years. If scaling remains clearly dominant, the field will continue concentrating compute and data. If data efficiency becomes viable, the field becomes more distributed and diverse.
Neither outcome is predetermined. The bet is real. The stakes are real. And the team making the bet has the resources to actually pursue it.
That's what makes this moment genuinely interesting for anyone following AI development.
FAQ
What is Flapping Airplanes and what are they building?
Flapping Airplanes is a newly-funded AI research lab founded by brothers Ben and Asher Spector and Aidan Smith (formerly of Neuralink). The team is focused on building foundation models that are orders of magnitude more data-efficient than current approaches. Rather than trying to compete with Open AI or Deep Mind on raw scale and capability, they're exploring fundamentally different learning algorithms inspired by how brains work—but not constrained by biological replication.
Why does data efficiency matter more than model scale?
Current frontier models require training on humanity's entire recorded knowledge—trillions of tokens of text and other data. Humans achieve comparable or superior learning with vastly less data. This efficiency gap means that if you can crack ultra-efficient learning, you unlock AI deployment in domains where training data is scarce (robotics, scientific discovery, enterprise applications). It also reduces training costs dramatically and makes custom model development more economically viable.
How is Flapping Airplanes different from Open AI or Deep Mind?
Open AI and Deep Mind are optimizing for frontier capability—building the most capable systems across the broadest range of tasks. Flapping Airplanes is explicitly not competing on that metric. They're optimizing for data efficiency instead. This means they're asking different research questions, likely pursuing different architectural approaches, and measuring progress differently. They've explicitly stated they don't see themselves as competing with larger labs—they're exploring territory those labs aren't prioritizing.
What does the name "Flapping Airplanes" actually mean?
Ben Spector explains it as follows: current large language models are like Boeing 787s—massive, heavily engineered machines optimized for scale. Flapping Airplanes isn't trying to build birds (that would be naive biomimicry). Instead, they're trying to build something like a flapping airplane—a system using radically different principles from current approaches while remaining practical and deployable. The metaphor captures the idea that you don't need to replicate biology exactly to learn from how biology solves similar problems.
What would success for Flapping Airplanes actually look like?
Success would probably look like demonstrating models that achieve significant capability (70-90% of frontier model performance) while requiring 1-10% of the training data or compute currently required. This might initially happen on specific domains (robotics, scientific discovery, enterprise tasks) before generalizing. They'd need to show this isn't just algorithmic cleverness on benchmarks but actual practical advantage in real-world deployment scenarios.
How much funding does Flapping Airplanes have and how long will it last?
Flapping Airplanes closed a $180 million seed funding round. At typical AI research burn rates (compute costs, researcher salaries, infrastructure), this provides roughly 3-5 years of runway before requiring either commercial traction, licensing deals, or additional funding. This timeline puts real pressure on the team to demonstrate meaningful progress—they're not a "research forever" lab, they're a company that needs to validate their approach within a specific window.
Why would the founders' relative inexperience be an advantage?
The team is positioning inexperience as a feature because deep expertise in transformers can create cognitive constraints. Researchers who've spent years making transformers work are invested in that approach and might miss alternatives. A young team without those constraints might be faster to consider approaches an experienced transformer expert would dismiss. Additionally, building a new research culture rather than copying existing labs' playbooks might lead to better results for this specific problem.
What are the biggest challenges Flapping Airplanes faces?
They face several challenges: (1) benchmark problems—traditional AI metrics measure breadth of knowledge, not data efficiency, so their results might look less impressive on standard benchmarks even if they're fundamentally superior; (2) funding pressure to demonstrate value within a timeframe that might not align with research timelines; (3) talent competition with established labs that have proven success and stronger brand recognition; and (4) the possibility that their core hypothesis is wrong and scaling really is the optimal path, which would invalidate the entire research direction.
Which industries would benefit most from more data-efficient AI?
Robotics would benefit enormously because physical training data is expensive and scarce. Scientific discovery domains (drug discovery, materials science, protein engineering) would benefit because experimental data is limited. Enterprise applications would benefit because companies have proprietary data but usually not internet-scale labeled training sets. Edge deployment on phones and devices would benefit because smaller, more efficient models are easier to deploy locally. Medical applications would benefit because data privacy constraints make training data scarce.
Is Flapping Airplanes in direct competition with other AI labs?
Not in the way people typically think about competition. Flapping Airplanes isn't trying to be better than Open AI at GPT tasks. It's exploring different problems entirely. That said, if they succeed at data efficiency, there are areas where this creates pressure on incumbent approaches—custom model training (reducing API dependency), privacy-sensitive applications (where you can't share data for training), and edge deployment. But these are complementary pressures, not direct competition for the same market.
What timeline should we expect for seeing real results from Flapping Airplanes?
Based on typical AI research timelines, Year 1 would involve infrastructure and initial experiments. Year 2-3 is when you'd expect first significant published findings and proof-of-concept demonstrations of major data efficiency improvements. Year 3-4 is when early commercial applications would probably appear. Year 5 is when you'd expect clearer evidence of whether this approach can scale to match frontier capabilities. These are estimates—actual progress could be faster or slower depending on whether their core hypotheses prove correct.
Conclusion: Why This Moment Matters
Flapping Airplanes represents something important that often gets overlooked in discussions of AI: the field is not settled. The idea that scaling is the path to AI capability is very productive, but it's not the only possible path.
The fact that serious researchers with real funding are explicitly saying "we think there's a completely different direction worth exploring" is valuable, regardless of whether they succeed.
If they succeed, AI development might shift toward more distributed, efficient approaches. If they fail, they'll have probably generated useful research about the limits and constraints of alternative approaches.
Either way, the existence of labs like Flapping Airplanes keeps the field honest. It prevents orthodoxy from calcifying. It keeps fundamental questions about how intelligence works and how machines can learn from becoming purely theoretical.
And in a field moving as fast as AI, keeping fundamental questions alive might be the most important thing anyone can do.
The $180 million bet is real. The founders are serious. The research questions they're asking are the right questions to be asking. Whether they answer them successfully will tell us something important about the future of artificial intelligence.
Key Takeaways
- Current AI models train on humanity's entire recorded knowledge, while humans learn with vastly less data—this efficiency gap is Flapping Airplanes' core focus
- The team is explicitly not competing with OpenAI/DeepMind on scaling metrics; they're exploring fundamentally different learning algorithms inspired by neuroscience
- Data efficiency unlocks AI deployment in robotics, drug discovery, scientific research, and enterprise applications where training data is scarce or prohibitively expensive
- Flapping Airplanes' $180M seed funding provides 3-5 years of runway to validate their hypothesis that alternative learning approaches can achieve comparable performance with 10-100x less training data
- Success would prove intelligence doesn't require current levels of scale—failure would provide valuable evidence that scaling is actually optimal, either outcome advancing AI knowledge
Related Articles
- Why AI Pilots Fail: The Gap Between Ambition and Execution [2025]
- How Bill Gates Predicted Adaptive AI in 1983 [2025]
- AI Video Generation Without Degradation: How Error Recycling Fixes Drift [2025]
- How Spotify's Top Developers Stopped Coding: The AI Revolution [2025]
- Building AI Culture in Enterprise: From Adoption to Scale [2025]
- OpenAI Disbands Alignment Team: What It Means for AI Safety [2025]

