![Why AI Pilots Fail: The Gap Between Ambition and Execution [2025]](https://tryrunable.com/blog/why-ai-pilots-fail-the-gap-between-ambition-and-execution-20/image-1-1771148216314.jpg)
Why AI Pilots Fail: The Gap Between Ambition and Execution [2025]
Here's something that keeps executives up at night: you've just invested millions in AI infrastructure, hired smart people, and launched a dozen pilots. But 14 months later, most of them are still sitting in "proof of concept" mode. They're not broken. They're just... stuck.
I've watched this pattern repeat across finance teams, healthcare organizations, manufacturing plants, and SaaS companies. Everyone's running pilots. Hardly anyone's shipping them.
The numbers tell the story. Only 26% of leaders report more than half their pilots actually scaling to production. Meanwhile, 69% of practitioners—the people actually building this stuff day-to-day—say most of their AI pilots never see production at all. That's not a technical problem. That's an execution problem.
Here's what's wild: leaders stay confident about their timelines. 75% of leadership teams believe they're on track. But simultaneously, 75% of practitioners think leadership doesn't understand how hard this actually is. That disconnect is where everything breaks down.
This isn't about AI being hard. It's about the invisible work that happens between "the model works" and "the model runs in production." That gap is where momentum dies. Integration backlogs pile up. Security reviews stall. Data dependencies create bottlenecks. Nobody planned for it because everyone was focused on proving the technology.
The good news? When leaders understand where the friction actually is, they can fix it. And the fix isn't rebuilding your entire strategy. It's changing where you spend your energy.
Let me show you exactly what's happening, why it happens, and what actually works.
TL; DR
- Only 26% of AI pilots scale beyond proof of concept, while leaders remain confident timelines will hold
- Integration complexity is the #1 blocker, not technical feasibility or model quality
- Visibility gaps between leadership and practitioners mean feedback arrives too late to prevent delays
- Early ownership, integration planning, and standardized tools are the three biggest execution accelerators
- Governance should be embedded from day one, not layered in before production
- Shared execution visibility between leaders and teams cuts project delays by 30%–40%

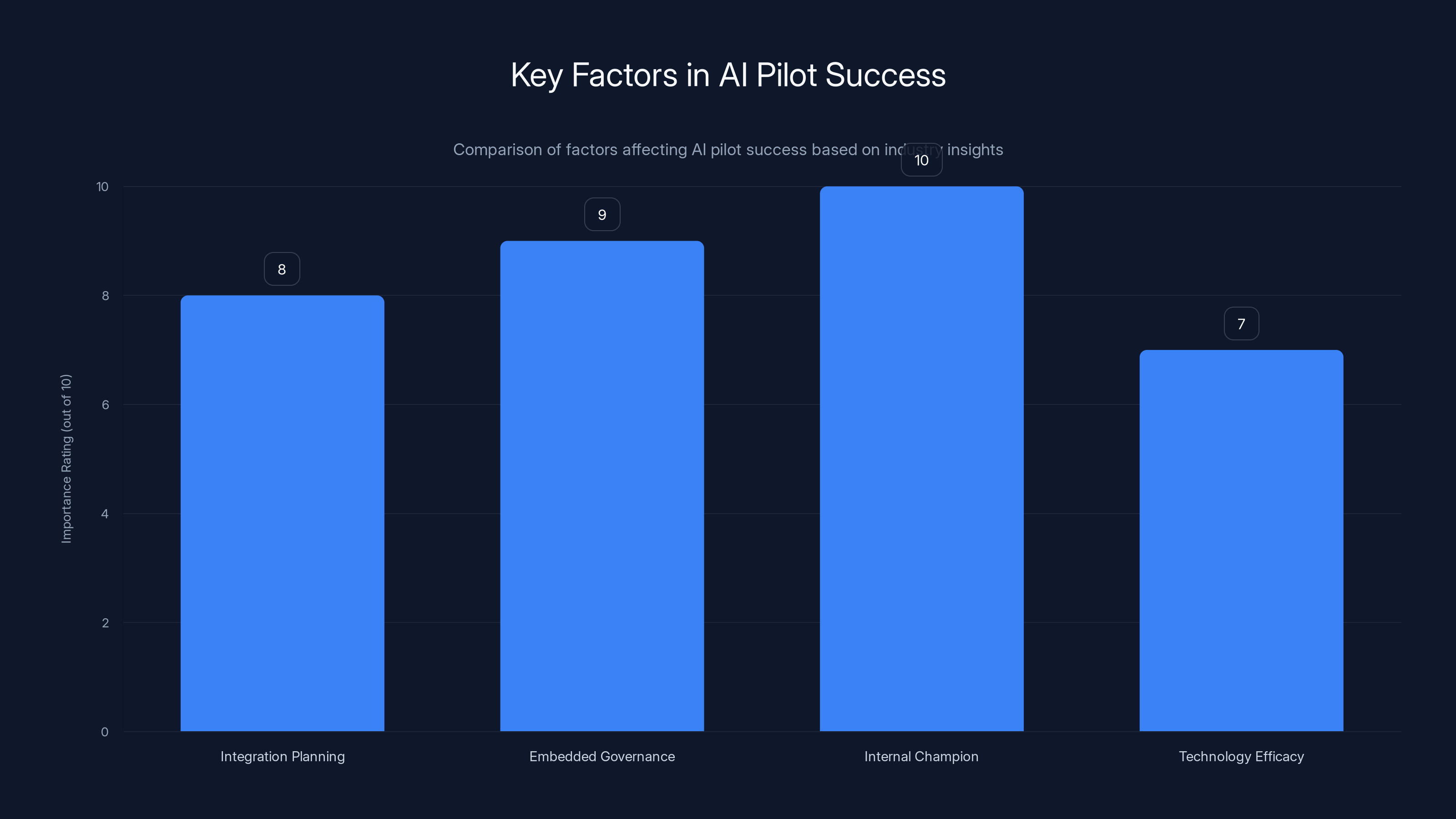
Integration planning, embedded governance, and having an internal champion are crucial for AI pilot success, each rated highly in importance. Estimated data based on industry insights.
The Visibility Mirage: Why Leaders and Teams See Different Realities
Imagine this: Your VP of AI tells the board that the computer vision pilot is on track. Meanwhile, the team building it knows they're six weeks behind because of data pipeline issues nobody flagged early. The VP isn't lying. They just don't see the same reality.
This is the visibility mirage. It's not confidence in strategy. It's a gap between what leaders think is happening and what's actually happening on the ground.
The data is stark. 81% of leaders say they're confident in their visibility into AI execution challenges. But 57% of practitioners believe leadership doesn't fully understand what's happening day-to-day. That's a 38-point gap.
Why does this matter? Because feedback arrives late.
When leaders learn about problems, it's usually through escalations or hallway conversations—after the damage is done. A team discovered a data quality issue three weeks ago but didn't flag it because they thought they'd solve it quickly. They didn't. Now it's a blocker. Now the timeline slips. Now leadership hears about it when recovery is expensive.
That reactive rhythm creates a cycle of damage control instead of forward progress. Projects feel unpredictable. Timelines stretch. Trust erodes.
The practical problem is simpler than you'd think: most organizations don't have a shared language for execution friction. Leaders track milestones. Practitioners experience obstacles. These aren't measured in the same way, so they don't get talked about together until something breaks.
Building shared visibility doesn't require new tools. It requires asking the right questions at the right time. What's blocking the integration work? Where's the data pipeline stuck? Which approvals are slow? When teams surface these issues weekly—not monthly—friction becomes visible while it's still addressable.
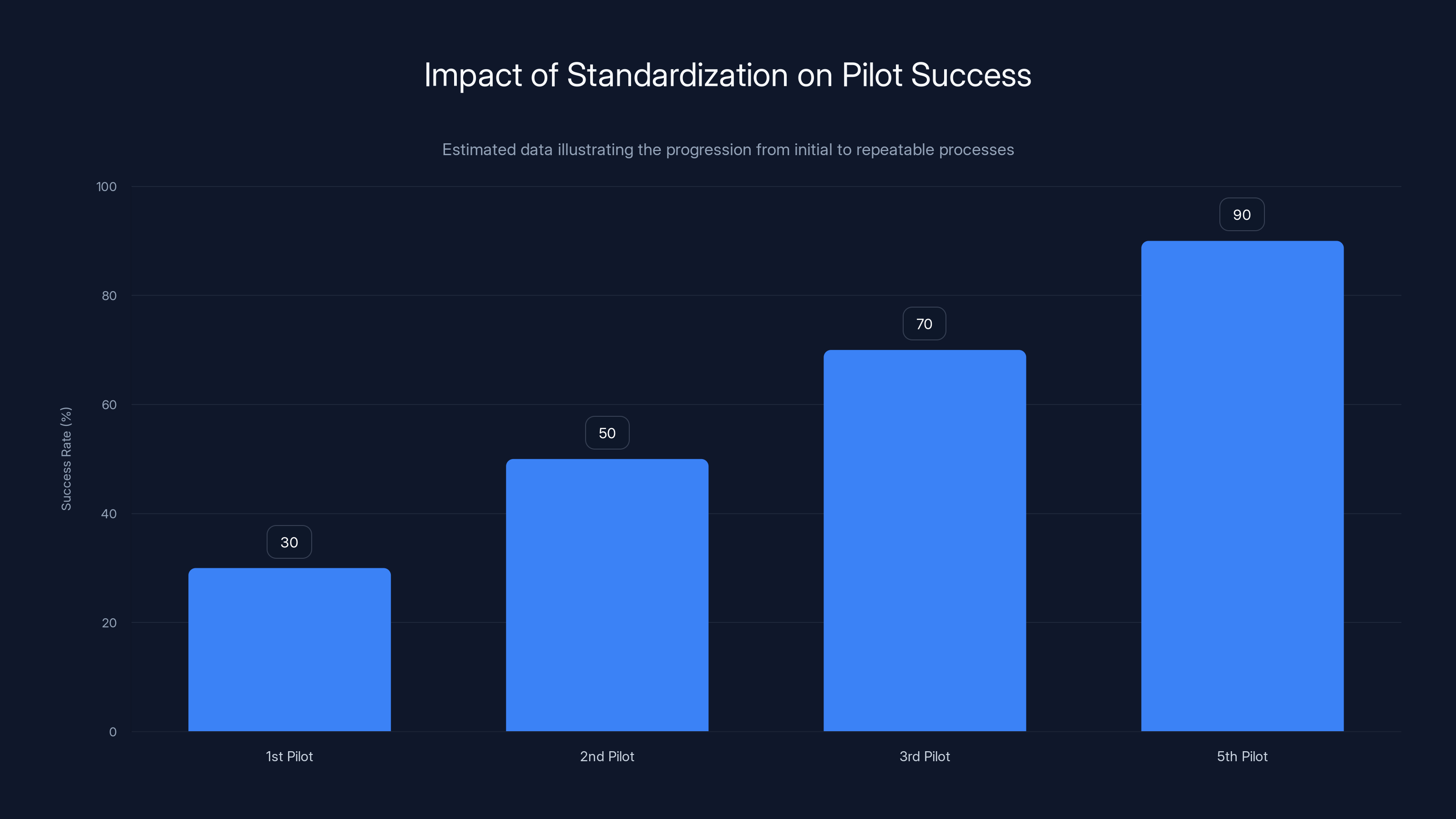
Estimated data shows that standardization and shared learning significantly increase the success rate of AI pilots, moving from 30% in the first pilot to 90% by the fifth.
Where AI Momentum Starts to Leak: Integration Complexity and System Sprawl
Early in an AI pilot, everything feels clean.
You pick a use case. The data science team trains a model. The model works on test data. You show results to stakeholders. Everyone's excited. The momentum is real.
Then the shape of the work changes.
The pilot needs to connect to production systems. The data has to flow through existing infrastructure. Security teams need to review it. Compliance wants to understand the model's decisions. Downstream workflows need to adapt to AI recommendations. Suddenly, this isolated "win" has to survive in a web of existing tools, approvals, and dependencies.
This is where timelines stretch and attention fragments.
The most consistent blocker? Integration complexity and system sprawl. Both leaders and practitioners rank this as the #1 barrier to scaling. It's not that people don't understand how to build integrations. It's that these dependencies weren't planned early, so teams end up rebuilding work under time pressure.
Here's what typically happens:
The Pilot Phase: "The model works on historical data. Let's show it to the business."
The Pre-Production Phase: "Oh, the model needs real-time data from three different systems. And the recommendation engine needs to connect to the approval workflow. And compliance needs logging for every decision."
The Panic Phase: "Why didn't we plan for this? Now we're rearchitecting."
Teams often treat integration planning like a follow-up task. It's not. Integration dependencies are execution-critical from day one.
When integration work is deferred until after technical validation, teams revisit assumptions under time pressure. Every new constraint requires rework. Every data dependency needs negotiation. Every approval process creates delays. Each delay feels reasonable individually. Stacked together, they consume months.
That's where momentum quietly drains away. It's not a dramatic crash. It's a slow leak.
The fix starts with a simple question: What systems, data sources, approval workflows, and compliance checks will this model need to touch in production? Answer that during the pilot design phase, not after you've proven the model works.
This is where internal AI champions become invaluable. They're the ones accountable for production outcomes, not just the proof of concept. They push for integration conversations early because they know the cost of deferring them is measured in months, not weeks.
The Hidden Cost of Confidence: When Leaders and Practitioners Operate in Different Worlds
Leadership confidence in AI execution is actually a problem.
Not because confidence is bad. But because high leadership confidence paired with low practitioner confidence creates a dangerous blindspot. Leaders think everything's on track. Practitioners know it's not. Nobody's in the room together talking about the gap.
This manifests in how problems get reported. When things go wrong, practitioners often don't escalate immediately. They assume they'll fix it. Or they assume leadership won't understand. Or they're waiting for the problem to become undeniable. By then, the timeline has already shifted.
Leadership learns about failures too late to course-correct. They learn through escalations. Through missed milestones that can't be hidden. Through conversations that happen because something broke.
That's reactive management, not proactive execution.
The antidote isn't more reporting. It's shared visibility into where friction actually shows up. When leaders and practitioners are tracking the same execution metrics—blocked items, dependency risks, integration challenges—the gap closes. Problems surface while there's still time to address them.
The organizations that execute AI successfully do this: they build visibility into execution obstacles, not just milestone status. They create a system where "the integration team is blocked waiting for data schema approval" gets surfaced the week it happens, not the month after the deadline slips.
This requires a cultural shift. Leadership has to genuinely want to hear about obstacles. Practitioners have to feel safe surfacing them. The conversation can't be "why is this blocked" but rather "let's unblock this together."
When that works, execution accelerates. Not because people work harder, but because friction gets addressed immediately instead of compounding.
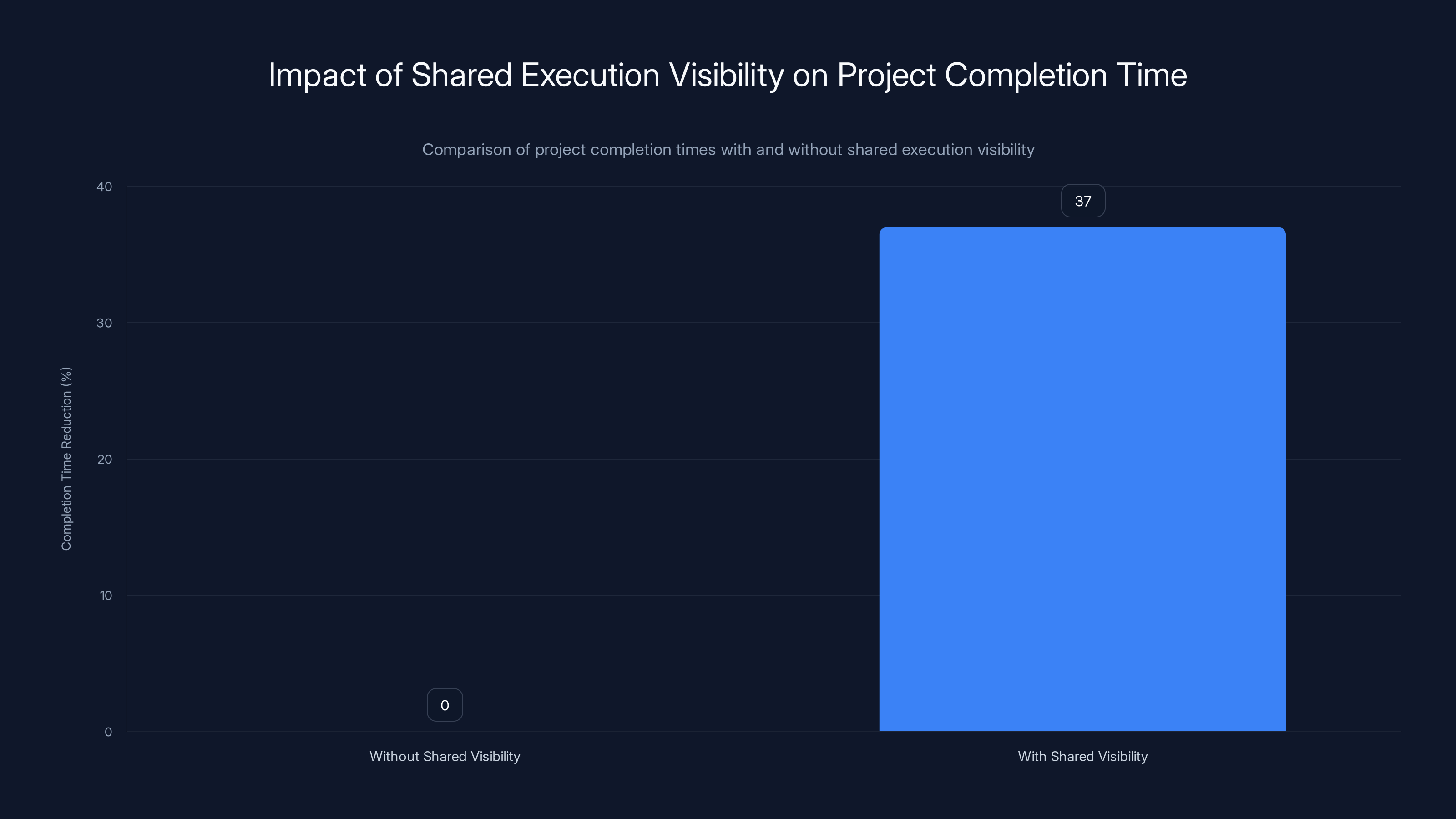
Projects with shared execution visibility complete 31%–43% faster, averaging a 37% reduction in completion time compared to those using periodic milestone reporting. Estimated data based on typical organizational scenarios.
Clear Ownership: The One Thing Every Successful AI Pilot Has
Every AI pilot that ships has someone accountable for it shipping.
Not the data scientist. Not the engineering team. A specific person responsible for turning a working model into a production system that delivers business value. This person has authority, visibility, and skin in the game.
They're often called an internal AI champion. And they change everything.
Why? Because AI pilots sit at the intersection of too many different functions. Data science wants to optimize for model accuracy. Engineering wants to optimize for scalability. Operations wants to optimize for reliability. Finance wants to optimize for cost. Compliance wants to minimize risk. Every stakeholder has a legitimate concern. Without a clear decision-maker, every concern becomes a blocking point.
The internal AI champion resolves this. They're the person who can say "we're prioritizing time-to-production over achieving 99.2% accuracy—we'll get there in v 2." Or "we're using this integration approach because it works with our current infrastructure, not because it's theoretically optimal."
This isn't about overriding good advice. It's about making decisions when tradeoffs are inevitable. And in AI execution, tradeoffs are constant.
The second thing a clear owner does: they prevent pilots from drifting into the ether of failed experiments. There's always a next priority. There's always something more urgent. An AI pilot that nobody's accountable for protecting gets deprioritized. An AI pilot with a champion who's evaluated on its production outcome doesn't.
Here's what changes when you assign clear ownership:
- Decisions get made faster. No more waiting for consensus across seven teams.
- Integration planning starts earlier. The champion knows they're going to need to navigate system sprawl, so they plan for it.
- Tradeoffs get articulated. Instead of hidden tension, you get explicit conversations about what you're optimizing for and what you're trading off.
- Blockers get escalated appropriately. When something needs executive intervention, the champion knows how to ask for it.
This doesn't have to be a new hire. It's often the most senior engineer on the project, or the business lead who requested the pilot, or a technical program manager. But whoever it is needs a clear mandate: turn this pilot into production capability.
When that mandate exists, pilots move faster. Not because people work harder. But because there's clarity about who decides when it's time to stop optimizing and start shipping.
Integration Planning: The Work That Happens Before the Pilot
Integration complexity is the #1 blocker for both leaders and practitioners. So why do most teams treat it like an afterthought?
Because it doesn't feel urgent while the pilot is still proving technical feasibility. Model performance feels like the critical path. Integration feels like something you'll handle later.
That's backwards.
Integration complexity determines whether a working model ever sees production. Model performance determines how well it works once it's there. You can optimize model performance in v 2. But if you haven't planned for integration, v 1 never ships.
Here's what successful integration planning looks like:
Week 1 of the pilot: Map the production environment
Before your data scientists write a single line of model code, answer these questions:
- Which systems will the model need to read data from?
- Which systems will it need to write predictions to?
- What approval workflows do recommendations need to flow through?
- Which teams need to sign off on the solution (security, compliance, operations)?
- What latency requirements exist? Can the model take 500ms to generate a prediction, or does it need to be under 100ms?
- What monitoring and logging do we need for governance?
This takes a week. It prevents three months of rework.
Week 2-3: Design the integration architecture
Once you know the dependencies, design how data will flow. Will you use event streaming? Batch processing? Real-time APIs? The data sources, latency requirements, and volume determine this. And this determination shapes the entire pilot.
You might discover that your ideal model architecture doesn't fit your integration constraints. That's good to know now, not after you've built it.
Week 4+: Build the pilot with integration constraints in mind
Now your data scientists aren't building a model that works on isolated data. They're building a model that works within the constraints of your production environment. That's harder. It's also the model you can actually ship.
The teams that execute AI successfully don't optimize for model performance first and integrate second. They optimize for model performance within integration constraints. It's a different mindset, and it's the difference between shipping in 6 months and shipping in 18 months.
Integration planning is unglamorous work. Nobody gets excited about data schema alignment or approval workflow mapping. But it's the work that turns "the model works" into "the model works in production."

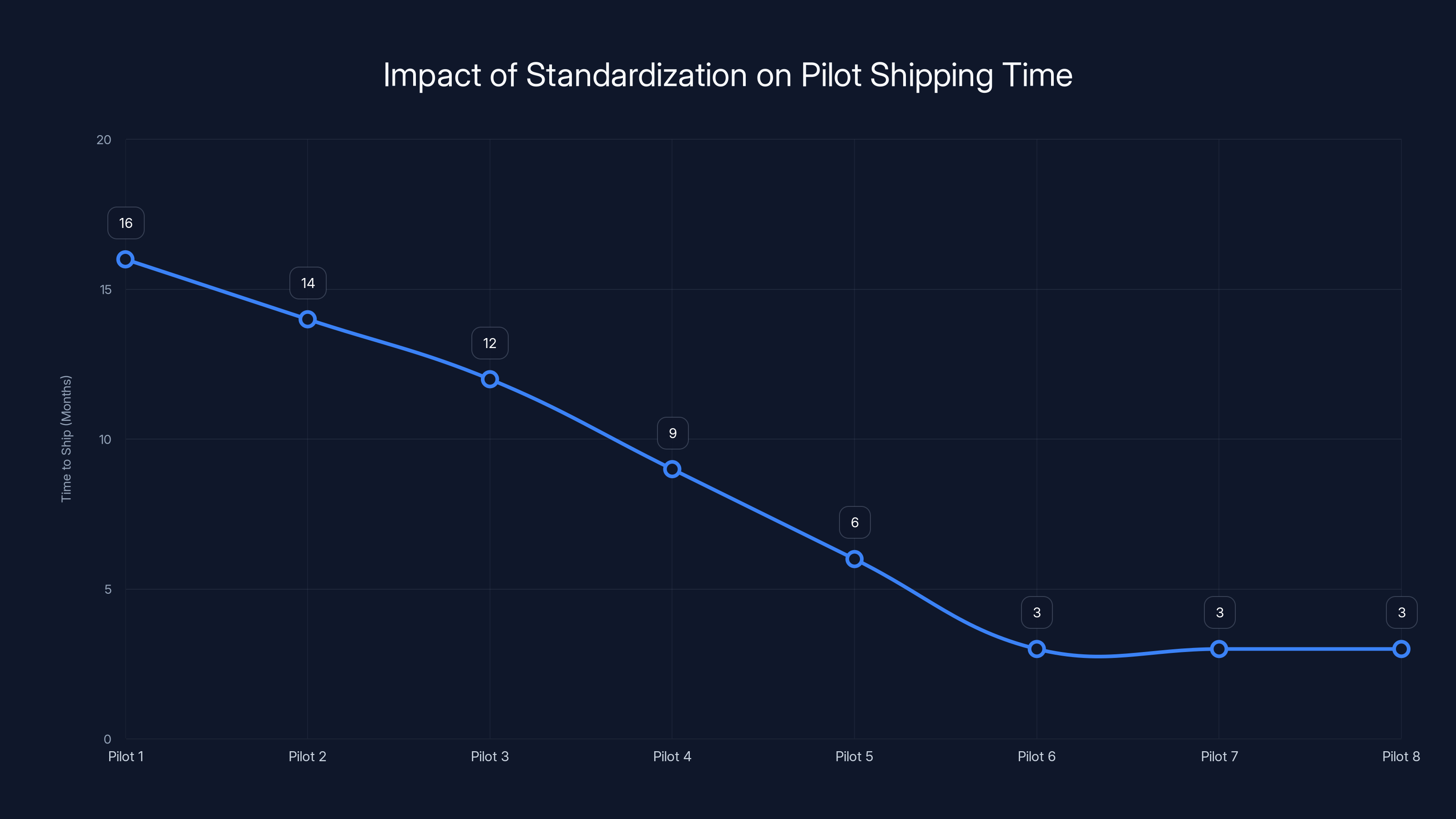
Standardization reduced pilot shipping time from 16 months to just 3 months, enabling faster innovation and execution. Estimated data based on case study.
Standardized Tools and Shared Learning: How Organizations Build Repeatable Capability
Your first AI pilot is a research project. Your fifth pilot is either a repeatable process or a mess.
Here's the difference: standardization.
When every pilot uses different tools, different frameworks, different approval processes, and different documentation standards, each one is basically starting from scratch. There's no institutional knowledge. There's no pattern to follow. Every team invents their own wheel.
When teams share a common foundation—standardized tools, shared frameworks, documented processes—something shifts. The second pilot learns from the first. The third learns from the first two. Over time, execution accelerates and knowledge compounds.
Standardized Tools aren't about forcing teams into a box. They're about reducing cognitive load and enabling knowledge transfer.
When data science teams use the same model training framework, they can help each other troubleshoot faster. When engineers use the same deployment pattern, they can reuse infrastructure and documentation. When teams use the same monitoring solution, they learn from each other's alerting rules and optimization strategies.
This is where consistency multiplies productivity. Not by making teams faster individually, but by letting teams learn from each other.
Shared Learning is where capability scales.
The teams executing AI well don't just run pilots in isolation. They create systems for surfacing lessons across the organization. What worked in the supply chain pilot that might work in the product recommendation pilot? What failure mode did the finance team hit that the customer service team should avoid?
This happens in three ways:
-
Community of practice: A regular forum where practitioners across different pilots share what they're building, what's working, and what's not. Not a status meeting. A working session where people are actually solving problems together.
-
Shared infrastructure: Reusable components, frameworks, and patterns that teams can build on. When the third team doesn't have to rebuild the data pipeline, they can focus on the unique part of their problem.
-
Documented playbooks: Living documentation of how to run a pilot in your organization. What approval gates do you need? What data governance questions do you ask? What monitoring do you set up? When teams can follow a proven pattern, they avoid classic mistakes.
The companies that execute AI at scale—the ones shipping multiple pilots per quarter instead of multiple per year—have built organizational muscle around this. They're not smarter. They're systematized.
That systematization starts with standardized tools. It compounds through shared learning. Over time, experimentation becomes repeatable capability.

Governance: The Thing That Should Be Built In, Not Bolted On
Here's what most teams do with governance:
- Build the model
- Get excited about the results
- Start the journey to production
- Realize governance is mandatory
- Pause everything while policies are interpreted, approvals are routed, and risks are reassessed
- Spend three months "hardening" the solution for governance requirements
- Finally ship
That's governance bolted on. It creates delays because governance wasn't designed into the solution from the start.
Here's what the teams that execute fast do:
- Map governance and compliance requirements early
- Build governance requirements into the pilot design from day one
- Maintain governance posture as the pilot develops
- When production time comes, governance is already baked in
- Ship faster
This is governance embedded into delivery, not layered on afterward.
The practical difference is substantial. Teams that embed governance early understand constraints before they start building. Teams that discover governance requirements mid-project have to rework assumptions, often under time pressure.
What does embedded governance look like?
Data Governance: Before the pilot starts, understand which data sources are allowed, how they're accessed, and what quality standards they must meet. When the data science team knows these constraints, they design the solution to work within them.
Model Explainability: Different use cases have different explainability requirements. A recommendation system in e-commerce might need less explainability than a model that influences credit decisions. Understand the requirement early. Design for it from the start.
Bias Monitoring: If the model needs to avoid discrimination, you can't just check for it at the end. You need to instrument for it throughout development. That's easier to do early than to bolt on later.
Audit Trails: Regulatory requirements often demand that every model decision is logged and auditable. If you design for this from the start, it's a natural part of the architecture. If you discover it mid-project, it's a redesign.
Access Control: Who can see the model? Who can change it? Who can deploy it? These are policy questions, but they're technical questions too. Map them early.
Embed governance into delivery workflows, not just deployment gates. When a data scientist pulls raw customer data, a governance rule should require they justify why unsampled data is necessary. When someone updates the model, an approval workflow should kick in automatically. When the model makes a risky decision, alerting should flag it.
These guardrails, applied consistently throughout development, mean there are no late-stage surprises. Governance becomes part of how work is done, not an obstacle to overcome.
Teams that treat governance as a design partner, not a blocker, ship faster. Not because they skip governance. But because they plan for it upfront instead of discovering it mid-project.

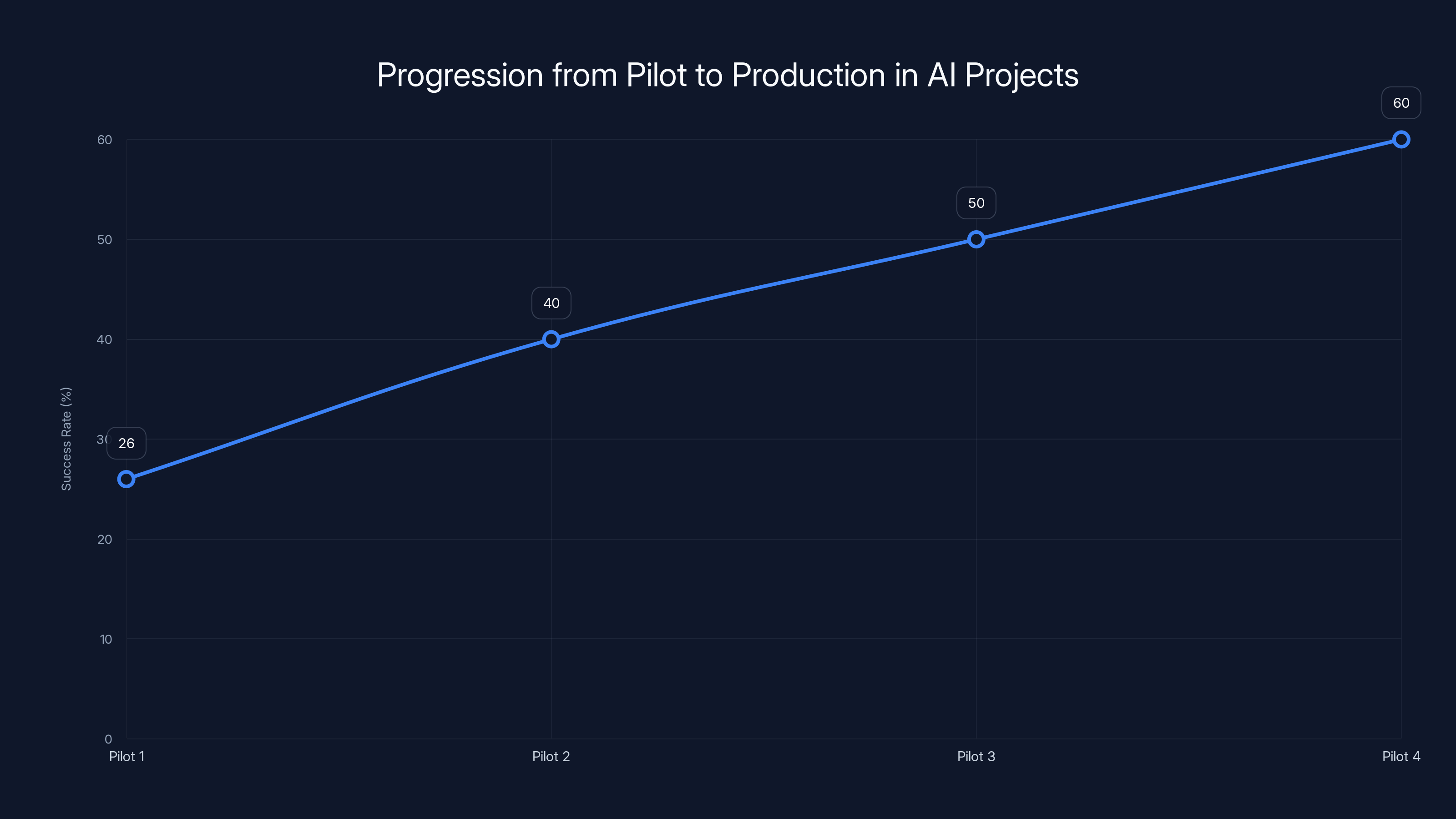
Estimated data shows that with disciplined execution, AI project success rates can improve from 26% to 60% by the fourth pilot.
Shared Execution Visibility: The Missing Link Between Ambition and Delivery
Here's what kills AI programs:
Not failed models. Not technical limitations. Not insufficient funding. It's the accumulation of small delays becoming compound delays, unsurfaced because leaders and practitioners are operating with different information.
Shared execution visibility changes this.
When leaders and practitioners are both tracking the same execution metrics, they're solving the same problem from the same starting point. That's radically different from leaders watching milestones while practitioners wrestle with obstacles.
What does shared execution visibility require?
A shared language for progress: Not "the model is 80% done" (which means nothing). But "the integration team is waiting for data schema approval—we'll know on Thursday if we're blocked for two weeks or two days."
Weekly, structured updates: Not monthly Power Point decks. Not daily standup transcripts. Weekly 15-minute sessions where the core team (leadership sponsor, internal champion, technical lead) discusses blockers, next steps, and dependency risks.
Transparency about obstacles, not just milestones: Most organizations track "is the model done?" and "is it in production?" That's binary. Shared visibility tracks "what's hard right now?" That's useful.
Clear escalation paths: When the integration work is blocked waiting for approval, does someone escalate? To whom? How quickly? Shared visibility means these decisions are made when obstacles surface, not after they've compounded.
The practical impact is dramatic. When a blocker surfaces in week 3, it gets addressed in week 4. When the same blocker isn't visible, it compounds by week 8, and by week 12 it's a crisis.
Shared visibility doesn't require new tools. It requires a commitment to transparency and a structure that surfaces obstacles when there's still time to address them.
The weekly execution sync should include:
- One item completed this week
- One blocker discovered this week
- One dependency risk for next week
- Any escalations needed from leadership
That's it. Fifteen minutes. Every single week.
The ritual matters more than the template. What matters is that leaders and practitioners are explicitly discussing the same execution challenges in real time.
When shared visibility becomes the norm, something shifts in the culture. Problems aren't secrets that get escalated when they're critical. They're obstacles that get surfaced while there's still time to solve them.

The Ownership-Integration-Governance Framework: Turning Pilots Into Progress
The organizations executing AI successfully aren't doing anything revolutionary. They're just doing a few things consistently.
Clear Ownership
- Assign an internal champion accountable for production outcomes
- Give them authority to make tradeoff decisions
- Evaluate them on whether the pilot ships, not on model accuracy
- Free them from other projects while the pilot is critical path
Integration-First Planning
- Map production dependencies before the pilot starts
- Design the solution to work within system constraints, not around them
- Plan approval workflows, compliance requirements, and operational constraints upfront
- Use integration requirements to guide technical decisions
Embedded Governance
- Identify compliance and risk requirements early
- Build governance into the solution design, not as an afterthought
- Create data governance, model monitoring, and audit trail requirements from day one
- Treat governance as a design partner, not a blocker
Standardized Tooling
- Use consistent frameworks, deployment patterns, and monitoring tools across pilots
- Document reusable components so teams learn from each other
- Create communities of practice where teams share lessons
Shared Execution Visibility
- Run weekly execution syncs between leadership and practitioners
- Surface obstacles when they're small, not when they're critical
- Track the same metrics so everyone's solving the same problem
- Escalate appropriately but not reflexively
These five practices compound. A pilot with clear ownership but no integration planning still runs into surprises. A pilot with integration planning but no shared visibility still has hidden delays. A pilot with all five is built to ship.

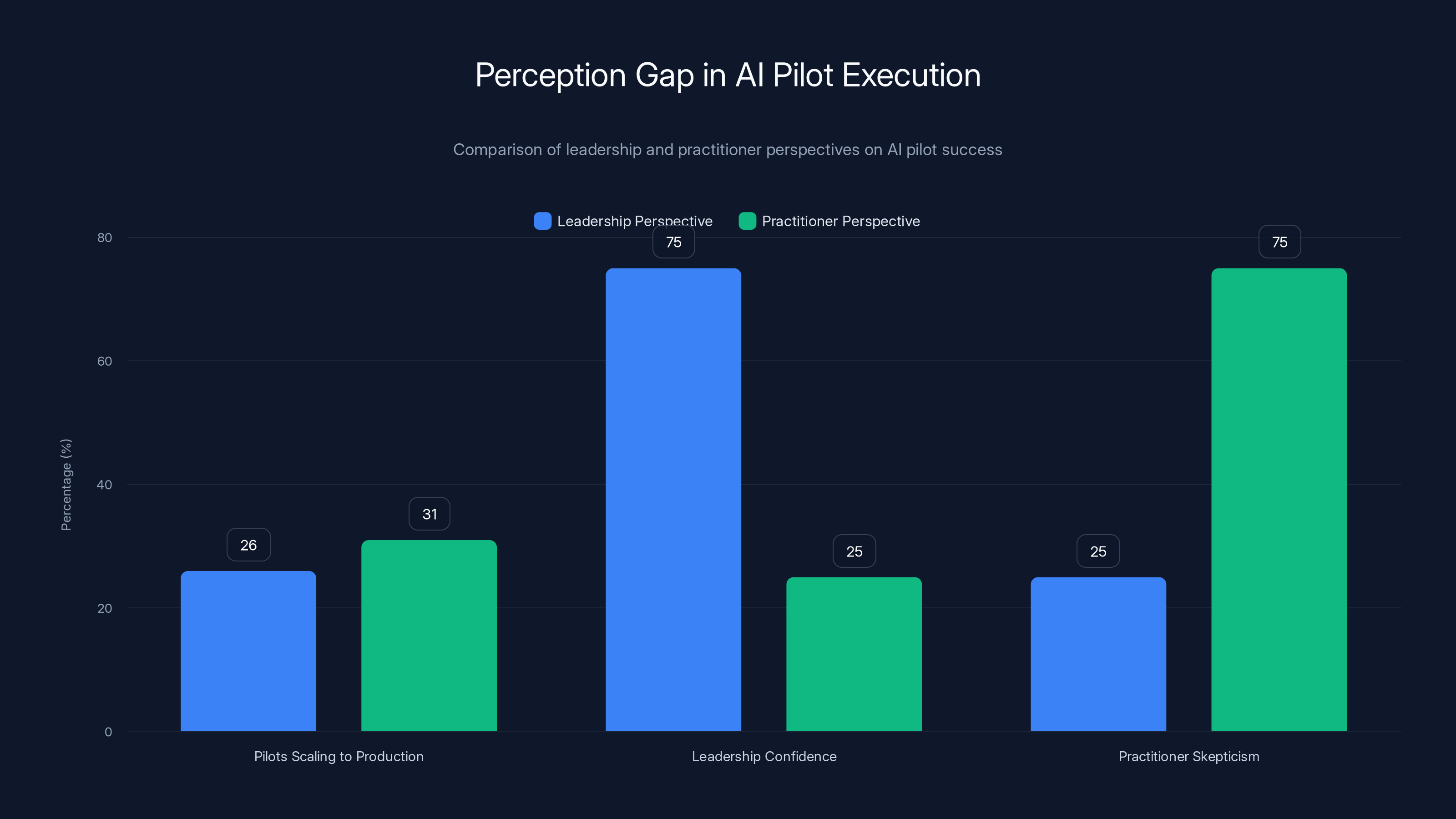
Estimated data shows a significant perception gap between leadership and practitioners regarding AI pilot success and execution challenges.
Real-World Case Study: How Standardization Changed the Game
Let me walk you through how one organization went from shipping one pilot every 18 months to shipping one per quarter.
They started exactly where you'd expect: inspired by AI's possibilities but frustrated by execution speed. Their first pilot took 16 months from concept to production. The second took 14 months (slightly better). By the third, they'd learned enough to compress it to 12 months.
Then they hit the limit of incremental improvement. The problem wasn't that teams were lazy or incapable. It was that every pilot was solving the same structural problems independently.
So they made a decision: standardize the execution model.
They created a standardized "AI Pilot Playbook" that included:
- A 6-week pre-pilot assessment to map integration dependencies and governance requirements
- A standard pilot template with integration testing built in from week 1
- A community of practice meeting every two weeks where teams shared blockers and wins
- A shared infrastructure team that maintained reusable components for data pipelines, model deployment, and monitoring
- Weekly execution visibility meetings between each pilot's champion and leadership
The impact was dramatic. Not because they made anyone work harder. But because the third pilot didn't have to reinvent the data pipeline. The fourth pilot didn't have to figure out governance from scratch. The fifth pilot shipped faster because teams had learned from the first four.
Within a year, they were running four pilots concurrently, with one shipping every quarter. Two years in, they'd shipped 12 pilots. Most were contributing measurable business value.
The secret wasn't smarter people or better technology. It was standardized execution, shared learning, and organizational discipline around what actually matters for shipping.

Common Mistakes That Kill Momentum (and How to Avoid Them)
Mistake 1: Treating Integration as a Phase, Not a Design Principle
Integration isn't something that happens after the pilot proves technical feasibility. It's a constraint that shapes every design decision from day one. Teams that forget this end up rearchitecting mid-project.
Fix: Spend week 1 mapping production environment and integration requirements. Use those constraints to guide technical decisions throughout the pilot.
Mistake 2: Optimizing for Model Accuracy Instead of Production Viability
It's tempting to chase 95% accuracy when 88% accuracy integrated and in production is worth more than 95% accuracy isolated and stuck in proof of concept.
Fix: Define "sufficient accuracy" during integration planning. Your data science team's job is to hit that bar within production constraints, not to maximize accuracy without constraint.
Mistake 3: Discovering Governance Requirements Mid-Project
Regulatory requirements, compliance standards, and risk tolerance should be understood during planning, not discovered when production is six weeks away.
Fix: Invite compliance, legal, and risk early. Map requirements before design begins. Governance shapes architecture, not the reverse.
Mistake 4: Building Pilots in Isolation
When every team invents its own approach, there's no leverage across projects. Each pilot takes as long as the last one.
Fix: Standardize tools, frameworks, and processes. Create communities of practice. Let the third pilot benefit from lessons learned in the first two.
Mistake 5: Making Decisions Without Clear Accountability
When seven people need to agree on tradeoffs, nothing gets decided. When one person is accountable, decisions get made.
Fix: Assign a clear internal champion. Give them authority to resolve conflicts and make tradeoff calls. Evaluate them on pilot outcome, not on consensus.
Mistake 6: Hiding Obstacles Until They're Critical
Practitioners often assume they'll fix problems before anyone needs to know about them. By the time the problem is undeniable, it's expensive to fix.
Fix: Create psychological safety to surface obstacles early. Run weekly execution visibility sessions. Treat obstacle surfacing as a sign of good judgment, not failure.

Building the Execution Muscle: From One-Off Pilots to Repeatable Capability
This is where the conversation shifts from "how do we make this one pilot ship" to "how do we build organizational capability to ship pilots consistently."
That requires thinking about execution as a learnable discipline, not a lucky accident.
Here's how organizations build that capability:
Layer 1: Clear process
Document how a pilot gets scoped, approved, executed, and shipped. Make this repeatable. When pilots follow a similar structure, lessons from one inform execution of the next.
Layer 2: Shared infrastructure
Build reusable components so the second team doesn't rebuild the data pipeline the first team built. Create libraries, templates, and frameworks that teams can inherit.
Layer 3: Community learning
Create forums where teams share what worked, what didn't, and what surprised them. This isn't a blame session. It's institutional knowledge transfer.
Layer 4: Metrics and visibility
Track not just whether pilots ship, but how long they take, where they get stuck, and what changes accelerate execution. Use that data to improve the process continuously.
Layer 5: Organizational discipline
This is the hard part. It's easy to follow the playbook on your first pilot. It's harder on your tenth when you're convinced your situation is special and the rules don't apply. Discipline means following the process even when it feels inefficient, because you know that shortcuts create compound delays.
Building this capability takes 12-18 months, not months. But once it's built, everything gets faster. Not just pilots—everything. Because you've learned how to turn ambition into action consistently.
The Future of AI Execution: Where This is Heading
Right now, the organizations that execute AI fast are the ones doing integration planning and governance embedding and shared visibility intentionally. Within two years, these practices will be table stakes.
Here's what I expect:
Execution becomes specialized. The same person building the model probably won't be responsible for shepherding it to production. Execution specialists will become as valued as machine learning engineers because turning ambition into impact is genuinely a different skill.
Integration-first architecture becomes the default. Teams will stop treating integration as an afterthought and start designing systems with production constraints in mind from day one. This will slow down individual pilots slightly but accelerate overall capability substantially.
Governance frameworks stabilize. Right now, every organization is inventing governance from scratch. Within two years, industry-standard governance frameworks will exist. Teams will adopt them instead of building custom compliance approaches for every pilot.
Execution visibility tools emerge. The spreadsheets and weekly email updates that pass for execution visibility now will be replaced by tools that automatically surface blockers and dependency risks. This will make real-time decision-making the norm instead of the exception.
The 26% success rate improves dramatically. When the practices that accelerate execution become normalized, more pilots will scale. I'd expect the percentage of pilots that reach production to double within three years.

The Bottom Line: Ambition Without Execution Is Just Feedback
Your organization probably has plenty of AI ambition. What it might lack is execution discipline.
That discipline isn't complicated. It's just doing a few things consistently:
- Assigning clear ownership so decisions get made
- Planning for integration early so architecture survives contact with reality
- Embedding governance so compliance doesn't stop progress mid-project
- Standardizing tooling so teams learn from each other
- Building shared visibility so leadership and practitioners are solving the same problem
When organizations do these things, pilots ship. Not all of them—some ideas genuinely won't work. But the ones with potential reach production instead of stalling in the invisible gap between ambition and impact.
That gap is real. It's also addressable. The organizations that close it aren't smarter or better funded. They're just more disciplined about the unglamorous work of turning possibility into reality.
Here's what successful execution looks like: a working model, a defined champion, clear integration requirements, governance built into the design, and weekly visibility into obstacles. Then you ship.
It's not rocket science. It's execution discipline. And that's the actual competitive advantage in AI right now.

FAQ
What exactly is an AI pilot, and why do so many fail to reach production?
An AI pilot is a contained experiment to test whether a machine learning model can solve a specific business problem. Most pilots fail to reach production not because the technology doesn't work, but because teams don't plan for integration complexity, governance requirements, and operational constraints that exist in production environments. Early pilots look successful when tested on isolated data, but real production systems involve multiple dependencies, approval workflows, and compliance requirements that weren't accounted for during initial design.
How much time should be spent on integration planning before a pilot starts?
Integration planning should take approximately one to two weeks before pilot development begins. During this time, teams should map which production systems the model will need to access, identify approval workflows, understand compliance requirements, determine latency constraints, and document data governance standards. This relatively brief upfront investment prevents months of rework when the pilot hits production requirements mid-project.
What's the difference between embedded governance and bolted-on governance?
Embedded governance means compliance, risk, and policy requirements are incorporated into the system design from day one. Bolted-on governance happens when governance requirements are discovered after the solution is built and have to be retrofitted. Embedded governance allows teams to design systems that naturally satisfy compliance requirements, while bolted-on governance often requires significant rearchitecture and delays production timelines by weeks or months.
Why is an internal AI champion so critical for pilot success?
An internal champion serves as the clear decision-maker and accountability holder for turning a working model into a production system. Without this person, AI pilots get deprioritized when other urgent work surfaces, governance decisions get delayed waiting for consensus, and integration questions go unresolved. The champion can resolve conflicts, make tradeoff decisions, and shield the project from competing priorities, all of which are essential for shipping.
How does shared execution visibility actually prevent delays?
Shared execution visibility between leadership and practitioners prevents delays by surfacing obstacles while they're small instead of after they've compounded. When a team discovers an integration blocker, the traditional approach is to try solving it internally first. If obstacles aren't visible to leadership until the problem is critical, three weeks of delay becomes a crisis. With weekly shared visibility sessions, that blocker gets flagged in week one, and leadership can remove the obstacle before it becomes a timeline threat.
What are the most common obstacles that stop AI pilots from reaching production?
The most consistent blockers are integration complexity (connecting the model to existing systems), unforeseen governance requirements (compliance, data privacy, audit trails), system sprawl (the model needs to touch more systems than initially expected), approval workflow delays (security reviews, compliance sign-offs), data quality issues (data dependencies become apparent too late), and lack of organizational accountability (no clear owner making decisions). Organizations that address these predictably during planning rather than discovering them mid-project execute significantly faster.
Can standardized tools and frameworks really accelerate multiple pilots?
Yes, significantly. When teams use consistent data pipeline frameworks, deployment patterns, and monitoring approaches, the second pilot doesn't have to rebuild what the first pilot built. Additionally, when governance, integration, and operational patterns are standardized, each team can learn from previous pilots' lessons rather than reinventing approaches. Organizations that standardize across pilots report 50% reduction in time-to-production for subsequent projects compared to those where each pilot develops independently.
How should organizations handle the gap between leadership confidence and practitioner confidence in AI timelines?
Address this gap by creating shared visibility into execution obstacles, not just milestone status. When leaders and practitioners are both tracking the same real-time blockers and dependency risks, they're operating from the same information. Weekly structured execution visibility sessions (not monthly reports) are the most effective mechanism for closing this gap, allowing leadership to understand where friction actually exists and help remove obstacles.
What metrics should organizations track to measure AI execution capability?
Beyond the obvious (did it ship?), track time-to-production, where pilots get stuck most frequently, how often governance or integration requirements cause rework, how many pilots reach production versus stall, percentage of planned timeline actually achieved, and which execution practices correlate with faster delivery. This data helps organizations identify their specific bottlenecks and refine their execution processes over time.
How long does it take to build organizational execution capability for consistent AI shipping?
Building this capability typically takes 12 to 18 months from the first pilot. The first pilot establishes baseline learning. The second and third pilots allow teams to test standardized approaches. By the fourth or fifth pilot, organizational patterns emerge and execution begins to accelerate. Patience during this period is critical—many organizations revert to old approaches when the process feels slow before the benefits of standardization compound.

Conclusion: The Work That Happens Between Ambition and Impact
Here's what I keep coming back to: nobody's going to write a blog post celebrating their amazing execution discipline. They'll write about the breakthrough model or the 40% accuracy improvement or the time they deployed something in three weeks.
But the organizations that actually ship AI consistently aren't doing anything sexy. They're executing fundamentals with discipline.
Clear ownership. Integration planning. Embedded governance. Standardized tooling. Shared visibility.
None of these are revolutionary. All of them are learnable. When done together, they're transformative.
The gap between AI ambition and AI impact isn't a technical problem. It's an execution problem. And execution problems have solutions.
You don't need a bigger budget or smarter people or breakthrough technology. You need clarity about what matters, discipline to focus on it, and the willingness to do unglamorous work that prevents failures instead of fixing them after the fact.
That's how pilots become production systems. That's how experiments become capabilities. That's how 26% becomes 60%.
Start with one pilot. Run it with clear ownership, plan integration early, embed governance, and create weekly visibility into obstacles. When it ships, do the next one better. By the third or fourth pilot, you're not just shipping faster. You've built organizational muscle.
That's where real competitive advantage lives. Not in the model. Not in the data. In the discipline to turn possibility into impact consistently.
The visibility mirage fades when leadership and practitioners work from the same version of reality. The execution gap closes when decision-making is clear, integration is planned, and obstacles surface early.
That's not harder. It's just different. And different is what turns AI investment into AI outcomes.

Key Takeaways
- Only 26% of leaders report more than half their AI pilots scaling to production; 69% of practitioners say most pilots never reach production
- Integration complexity and system sprawl are the #1 blocker for both leaders and practitioners, not model quality or technical feasibility
- The visibility gap between leadership (81% confident) and practitioners (57% feeling unseen) creates reactive management instead of proactive execution
- Five core practices—clear ownership, integration-first planning, embedded governance, standardized tooling, and shared visibility—consistently accelerate pilot delivery
- Organizations that embed governance and integration requirements from day one reduce time-to-production by 50% compared to those discovering requirements mid-project
- Weekly execution visibility sessions between leadership and practitioners prevent small delays from compounding into timeline slips
- Standardized AI pilot playbooks and shared infrastructure across projects reduce average delivery time from 14 months to 7 months
Related Articles
- Building AI Culture in Enterprise: From Adoption to Scale [2025]
- From AI Pilots to Real Business Value: A Practical Roadmap [2025]
- Who Owns Your Company's AI Layer? Enterprise Architecture Strategy [2025]
- Larry Ellison's 1987 AI Warning: Why 'The Height of Nonsense' Still Matters [2025]
- Google Gemini Hits 750M Users: How It Competes with ChatGPT [2025]
- AI Bias as Technical Debt: Hidden Costs Draining Your Budget [2025]

